 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmark Everything Everywhere All at Once
Jun 04, 2026Benchmarks are fundamental for evaluating and advancing LLMs and MLLMs by providing standardized and explicit measures of performance. However, their construction is labor-intensive and hard to reuse, raising concerns about sustainability and scalability. Moreover, existing benchmarks often quickly reach performance saturation after their release, resulting in insufficient discrimination among state-of-the-art models. To address these challenges, we introduce Benchmark Agent, a fully autonomous agentic system designed for benchmark building. Our framework orchestrates the complete benchmark construction pipeline, from user query analysis and subtask design to data annotation and quality control. To assess Benchmark Agent, we implement it to produce 15 representative benchmarks, spanning diverse evaluation scenarios, including text understanding, multimodal understanding, and domain-specific reasoning. Extensive experiments, including human evaluation, LLM-as-a-judge assessment, and consistency checks, demonstrate Benchmark Agent can generate high-quality benchmark samples with minimal human involvement. More importantly, through continual evaluation, we observe several insightful findings, including that current models struggle with certain domain-specific reasoning tasks. We believe that rapidly evolving benchmarks can contribute significantly to the research community. The preview and code will be publicly available at the demo page and code repository.
Minimizing Modality Gap from the Input Side: Your Speech LLM Can Be a Prosody-Aware Text LLM
May 07, 2026Speech large language models (SLMs) are typically built from text large language model (TLM) checkpoints, yet they still suffer from a substantial modality gap. Prior work has mainly attempted to reduce this gap from the output side by making speech generation more text-like, but the gap remains. We argue that the key remaining bottleneck lies on the input side. We propose TextPro-SLM, an SLM that makes spoken input more closely resemble that of a prosody-aware text LLM. TextPro-SLM combines WhisperPro, a unified speech encoder that produces synchronized text tokens and prosody embeddings, with an LLM backbone trained to preserve the semantic capabilities of the original TLM while learning paralinguistic understanding. Experiments show that TextPro-SLM achieves the lowest modality gap among leading SLMs at both 3B and 7B scales, while also delivering strong overall performance on paralinguistic understanding tasks. These gains are achieved with only roughly 1,000 hours of LLM training audio, suggesting that reducing the modality gap from the input side is both effective and data-efficient.
DocSAM: Unified Document Image Segmentation via Query Decomposition and Heterogeneous Mixed Learning
Apr 05, 2025Document image segmentation is crucial for document analysis and recognition but remains challenging due to the diversity of document formats and segmentation tasks. Existing methods often address these tasks separately, resulting in limited generalization and resource wastage. This paper introduces DocSAM, a transformer-based unified framework designed for various document image segmentation tasks, such as document layout analysis, multi-granularity text segmentation, and table structure recognition, by modelling these tasks as a combination of instance and semantic segmentation. Specifically, DocSAM employs Sentence-BERT to map category names from each dataset into semantic queries that match the dimensionality of instance queries. These two sets of queries interact through an attention mechanism and are cross-attended with image features to predict instance and semantic segmentation masks. Instance categories are predicted by computing the dot product between instance and semantic queries, followed by softmax normalization of scores. Consequently, DocSAM can be jointly trained on heterogeneous datasets, enhancing robustness and generalization while reducing computational and storage resources. Comprehensive evaluations show that DocSAM surpasses existing methods in accuracy, efficiency, and adaptability, highlighting its potential for advancing document image understanding and segmentation across various applications. Codes are available at https://github.com/xhli-git/DocSAM.
QG-VTC: Question-Guided Visual Token Compression in MLLMs for Efficient VQA
Apr 01, 2025Recent advances in Multi-modal Large Language Models (MLLMs) have shown significant progress in open-world Visual Question Answering (VQA). However, integrating visual information increases the number of processed tokens, leading to higher GPU memory usage and computational overhead. Images often contain more redundant information than text, and not all visual details are pertinent to specific questions. To address these challenges, we propose QG-VTC, a novel question-guided visual token compression method for MLLM-based VQA tasks. QG-VTC employs a pretrained text encoder and a learnable feed-forward layer to embed user questions into the vision encoder's feature space then computes correlation scores between the question embeddings and visual tokens. By selecting the most relevant tokens and softly compressing others, QG-VTC ensures fine-tuned relevance to user needs. Additionally, a progressive strategy applies this compression across different vision encoder layers, gradually reducing token numbers. This approach maximizes retention of question-relevant information while discarding irrelevant details. Experimental results show that our method achieves performance on par with uncompressed models using just 1/8 of the visual tokens. The code and model will be publicly available on GitHub.
LongDocURL: a Comprehensive Multimodal Long Document Benchmark Integrating Understanding, Reasoning, and Locating
Dec 24, 2024Large vision language models (LVLMs) have improved the document understanding capabilities remarkably, enabling the handling of complex document elements, longer contexts, and a wider range of tasks. However, existing document understanding benchmarks have been limited to handling only a small number of pages and fail to provide a comprehensive analysis of layout elements locating. In this paper, we first define three primary task categories: Long Document Understanding, numerical Reasoning, and cross-element Locating, and then propose a comprehensive benchmark, LongDocURL, integrating above three primary tasks and comprising 20 sub-tasks categorized based on different primary tasks and answer evidences. Furthermore, we develop a semi-automated construction pipeline and collect 2,325 high-quality question-answering pairs, covering more than 33,000 pages of documents, significantly outperforming existing benchmarks. Subsequently, we conduct comprehensive evaluation experiments on both open-source and closed-source models across 26 different configurations, revealing critical performance gaps in this field.
Two-Stage Holistic and Contrastive Explanation of Image Classification
Jun 10, 2023



The need to explain the output of a deep neural network classifier is now widely recognized. While previous methods typically explain a single class in the output, we advocate explaining the whole output, which is a probability distribution over multiple classes. A whole-output explanation can help a human user gain an overall understanding of model behaviour instead of only one aspect of it. It can also provide a natural framework where one can examine the evidence used to discriminate between competing classes, and thereby obtain contrastive explanations. In this paper, we propose a contrastive whole-output explanation (CWOX) method for image classification, and evaluate it using quantitative metrics and through human subject studies. The source code of CWOX is available at https://github.com/vaynexie/CWOX.
ViT-CX: Causal Explanation of Vision Transformers
Nov 06, 2022



Despite the popularity of Vision Transformers (ViTs) and eXplainable AI (XAI), only a few explanation methods have been proposed for ViTs thus far. They use attention weights of the classification token on patch embeddings and often produce unsatisfactory saliency maps. In this paper, we propose a novel method for explaining ViTs called ViT-CX. It is based on patch embeddings, rather than attentions paid to them, and their causal impacts on the model output. ViT-CX can be used to explain different ViT models. Empirical results show that, in comparison with previous methods, ViT-CX produces more meaningful saliency maps and does a better job at revealing all the important evidence for prediction. It is also significantly more faithful to the model as measured by deletion AUC and insertion AUC.
Example Perplexity
Mar 16, 2022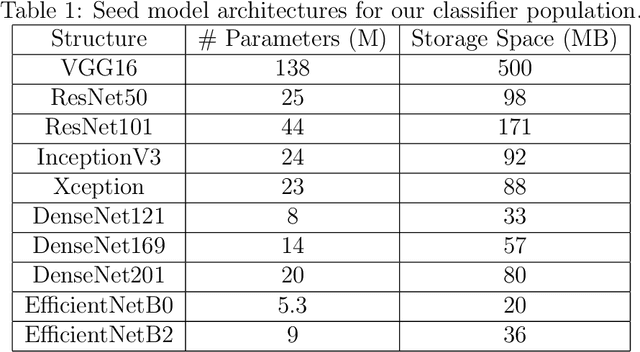
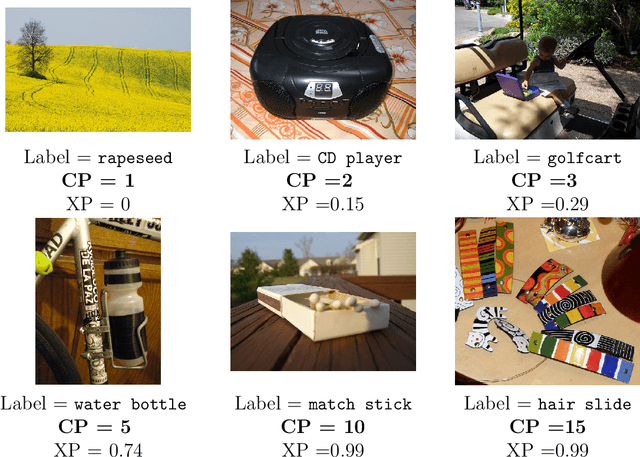

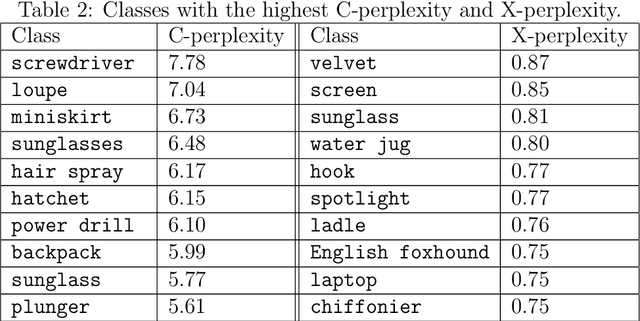
Some examples are easier for humans to classify than others. The same should be true for deep neural networks (DNNs). We use the term example perplexity to refer to the level of difficulty of classifying an example. In this paper, we propose a method to measure the perplexity of an example and investigate what factors contribute to high example perplexity. The related codes and resources are available at https://github.com/vaynexie/Example-Perplexity.
Quantitative Evaluations on Saliency Methods: An Experimental Study
Dec 31, 2020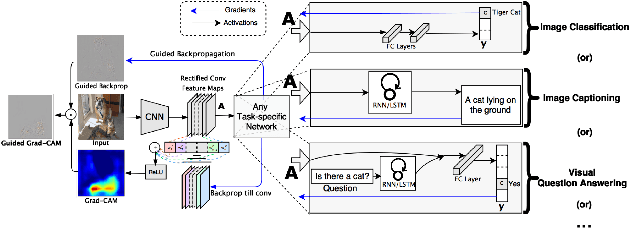
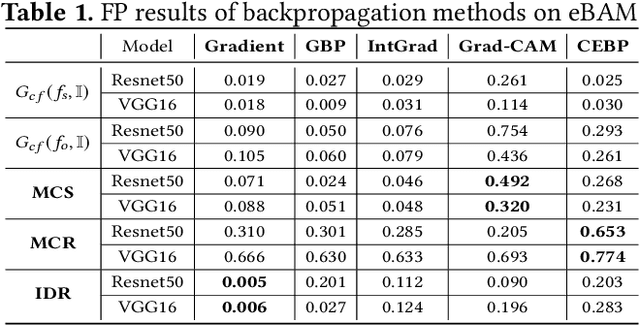
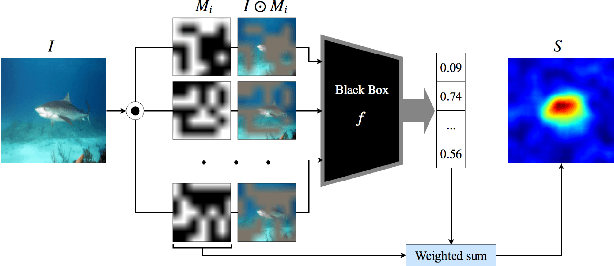
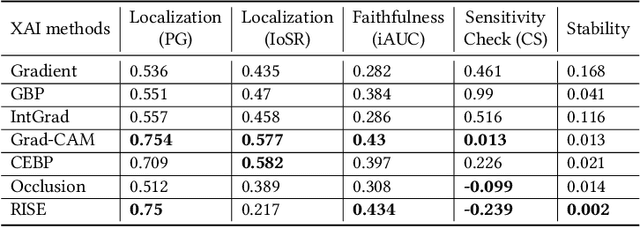
It has been long debated that eXplainable AI (XAI) is an important topic, but it lacks rigorous definition and fair metrics. In this paper, we briefly summarize the status quo of the metrics, along with an exhaustive experimental study based on them, including faithfulness, localization, false-positives, sensitivity check, and stability. With the experimental results, we conclude that among all the methods we compare, no single explanation method dominates others in all metrics. Nonetheless, Gradient-weighted Class Activation Mapping (Grad-CAM) and Randomly Input Sampling for Explanation (RISE) perform fairly well in most of the metrics. Utilizing a set of filtered metrics, we further present a case study to diagnose the classification bases for models. While providing a comprehensive experimental study of metrics, we also examine measuring factors that are missed in current metrics and hope this valuable work could serve as a guide for future research.