 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantitative Evaluations on Saliency Methods: An Experimental Study
Dec 31, 2020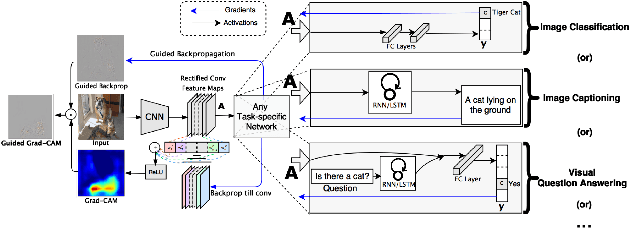
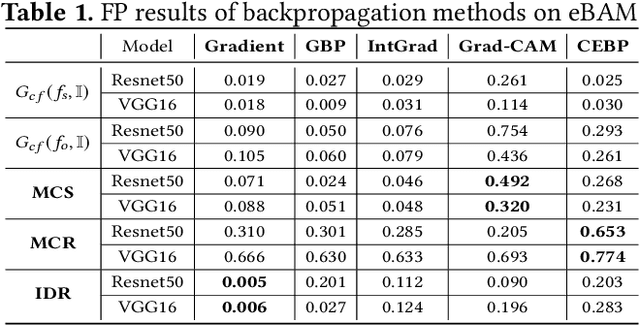
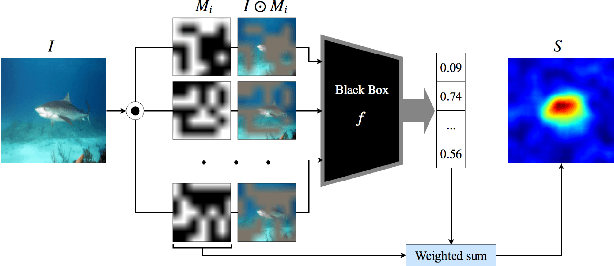
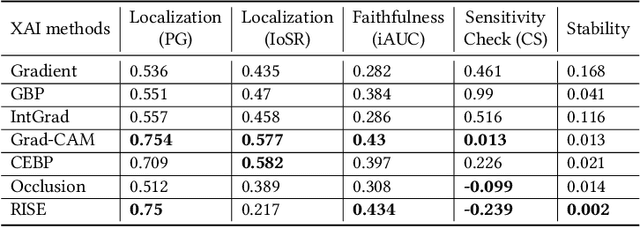
It has been long debated that eXplainable AI (XAI) is an important topic, but it lacks rigorous definition and fair metrics. In this paper, we briefly summarize the status quo of the metrics, along with an exhaustive experimental study based on them, including faithfulness, localization, false-positives, sensitivity check, and stability. With the experimental results, we conclude that among all the methods we compare, no single explanation method dominates others in all metrics. Nonetheless, Gradient-weighted Class Activation Mapping (Grad-CAM) and Randomly Input Sampling for Explanation (RISE) perform fairly well in most of the metrics. Utilizing a set of filtered metrics, we further present a case study to diagnose the classification bases for models. While providing a comprehensive experimental study of metrics, we also examine measuring factors that are missed in current metrics and hope this valuable work could serve as a guide for future research.