 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCannyEdit: Selective Canny Control and Dual-Prompt Guidance for Training-Free Image Editing
Aug 09, 2025Recent advances in text-to-image (T2I) models have enabled training-free regional image editing by leveraging the generative priors of foundation models. However, existing methods struggle to balance text adherence in edited regions, context fidelity in unedited areas, and seamless integration of edits. We introduce CannyEdit, a novel training-free framework that addresses these challenges through two key innovations: (1) Selective Canny Control, which masks the structural guidance of Canny ControlNet in user-specified editable regions while strictly preserving details of the source images in unedited areas via inversion-phase ControlNet information retention. This enables precise, text-driven edits without compromising contextual integrity. (2) Dual-Prompt Guidance, which combines local prompts for object-specific edits with a global target prompt to maintain coherent scene interactions. On real-world image editing tasks (addition, replacement, removal), CannyEdit outperforms prior methods like KV-Edit, achieving a 2.93 to 10.49 percent improvement in the balance of text adherence and context fidelity. In terms of editing seamlessness, user studies reveal only 49.2 percent of general users and 42.0 percent of AIGC experts identified CannyEdit's results as AI-edited when paired with real images without edits, versus 76.08 to 89.09 percent for competitor methods.
Dual Risk Minimization: Towards Next-Level Robustness in Fine-tuning Zero-Shot Models
Nov 29, 2024



Fine-tuning foundation models often compromises their robustness to distribution shifts. To remedy this, most robust fine-tuning methods aim to preserve the pre-trained features. However, not all pre-trained features are robust and those methods are largely indifferent to which ones to preserve. We propose dual risk minimization (DRM), which combines empirical risk minimization with worst-case risk minimization, to better preserve the core features of downstream tasks. In particular, we utilize core-feature descriptions generated by LLMs to induce core-based zero-shot predictions which then serve as proxies to estimate the worst-case risk. DRM balances two crucial aspects of model robustness: expected performance and worst-case performance, establishing a new state of the art on various real-world benchmarks. DRM significantly improves the out-of-distribution performance of CLIP ViT-L/14@336 on ImageNet (75.9 to 77.1), WILDS-iWildCam (47.1 to 51.8), and WILDS-FMoW (50.7 to 53.1); opening up new avenues for robust fine-tuning. Our code is available at https://github.com/vaynexie/DRM .
A Causal Framework to Unify Common Domain Generalization Approaches
Jul 13, 2023



Domain generalization (DG) is about learning models that generalize well to new domains that are related to, but different from, the training domain(s). It is a fundamental problem in machine learning and has attracted much attention in recent years. A large number of approaches have been proposed. Different approaches are motivated from different perspectives, making it difficult to gain an overall understanding of the area. In this paper, we propose a causal framework for domain generalization and present an understanding of common DG approaches in the framework. Our work sheds new lights on the following questions: (1) What are the key ideas behind each DG method? (2) Why is it expected to improve generalization to new domains theoretically? (3) How are different DG methods related to each other and what are relative advantages and limitations? By providing a unified perspective on DG, we hope to help researchers better understand the underlying principles and develop more effective approaches for this critical problem in machine learning.
Two-Stage Holistic and Contrastive Explanation of Image Classification
Jun 10, 2023



The need to explain the output of a deep neural network classifier is now widely recognized. While previous methods typically explain a single class in the output, we advocate explaining the whole output, which is a probability distribution over multiple classes. A whole-output explanation can help a human user gain an overall understanding of model behaviour instead of only one aspect of it. It can also provide a natural framework where one can examine the evidence used to discriminate between competing classes, and thereby obtain contrastive explanations. In this paper, we propose a contrastive whole-output explanation (CWOX) method for image classification, and evaluate it using quantitative metrics and through human subject studies. The source code of CWOX is available at https://github.com/vaynexie/CWOX.
ViT-CX: Causal Explanation of Vision Transformers
Nov 06, 2022



Despite the popularity of Vision Transformers (ViTs) and eXplainable AI (XAI), only a few explanation methods have been proposed for ViTs thus far. They use attention weights of the classification token on patch embeddings and often produce unsatisfactory saliency maps. In this paper, we propose a novel method for explaining ViTs called ViT-CX. It is based on patch embeddings, rather than attentions paid to them, and their causal impacts on the model output. ViT-CX can be used to explain different ViT models. Empirical results show that, in comparison with previous methods, ViT-CX produces more meaningful saliency maps and does a better job at revealing all the important evidence for prediction. It is also significantly more faithful to the model as measured by deletion AUC and insertion AUC.
Example Perplexity
Mar 16, 2022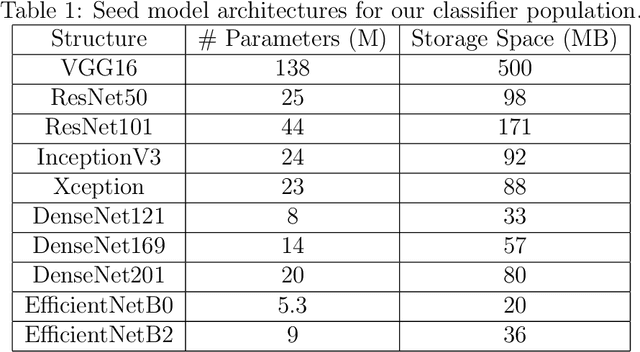
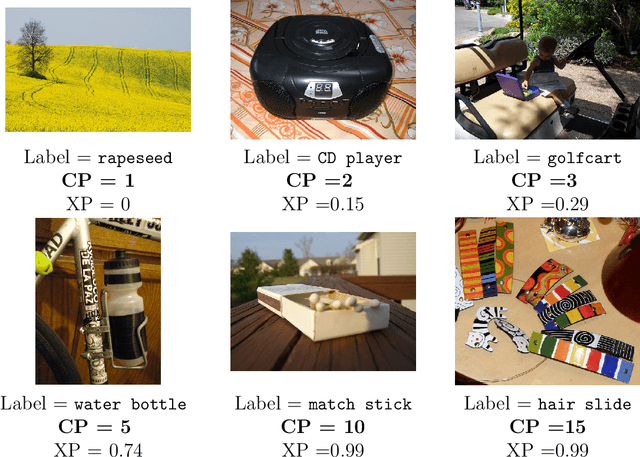

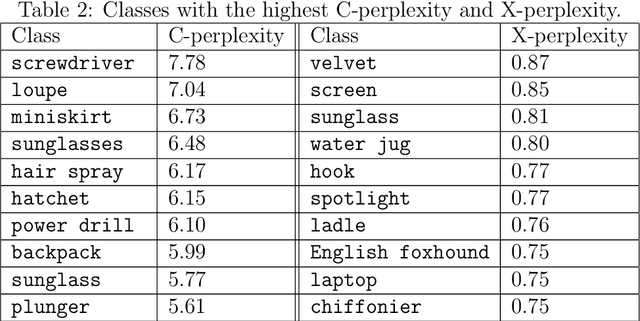
Some examples are easier for humans to classify than others. The same should be true for deep neural networks (DNNs). We use the term example perplexity to refer to the level of difficulty of classifying an example. In this paper, we propose a method to measure the perplexity of an example and investigate what factors contribute to high example perplexity. The related codes and resources are available at https://github.com/vaynexie/Example-Perplexity.