 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOOSComp: Improving Lightweight Long-Context Compressor via Mitigating Over-Smoothing and Incorporating Outlier Scores
Apr 23, 2025Recent advances in large language models have significantly improved their ability to process long-context input, but practical applications are challenged by increased inference time and resource consumption, particularly in resource-constrained environments. To address these challenges, we propose MOOSComp, a token-classification-based long-context compression method that enhances the performance of a BERT-based compressor by mitigating the over-smoothing problem and incorporating outlier scores. In the training phase, we add an inter-class cosine similarity loss term to penalize excessively similar token representations, thereby improving the token classification accuracy. During the compression phase, we introduce outlier scores to preserve rare but critical tokens that are prone to be discarded in task-agnostic compression. These scores are integrated with the classifier's output, making the compressor more generalizable to various tasks. Superior performance is achieved at various compression ratios on long-context understanding and reasoning benchmarks. Moreover, our method obtains a speedup of 3.3x at a 4x compression ratio on a resource-constrained mobile device.
Open-Vocabulary Object Detection with Meta Prompt Representation and Instance Contrastive Optimization
Mar 14, 2024Classical object detectors are incapable of detecting novel class objects that are not encountered before. Regarding this issue, Open-Vocabulary Object Detection (OVOD) is proposed, which aims to detect the objects in the candidate class list. However, current OVOD models are suffering from overfitting on the base classes, heavily relying on the large-scale extra data, and complex training process. To overcome these issues, we propose a novel framework with Meta prompt and Instance Contrastive learning (MIC) schemes. Firstly, we simulate a novel-class-emerging scenario to help the prompt learner that learns class and background prompts generalize to novel classes. Secondly, we design an instance-level contrastive strategy to promote intra-class compactness and inter-class separation, which benefits generalization of the detector to novel class objects. Without using knowledge distillation, ensemble model or extra training data during detector training, our proposed MIC outperforms previous SOTA methods trained with these complex techniques on LVIS. Most importantly, MIC shows great generalization ability on novel classes, e.g., with $+4.3\%$ and $+1.9\% \ \mathrm{AP}$ improvement compared with previous SOTA on COCO and Objects365, respectively.
Explore and Exploit the Diverse Knowledge in Model Zoo for Domain Generalization
Jun 05, 2023



The proliferation of pretrained models, as a result of advancements in pretraining techniques, has led to the emergence of a vast zoo of publicly available models. Effectively utilizing these resources to obtain models with robust out-of-distribution generalization capabilities for downstream tasks has become a crucial area of research. Previous research has primarily focused on identifying the most powerful models within the model zoo, neglecting to fully leverage the diverse inductive biases contained within. This paper argues that the knowledge contained in weaker models is valuable and presents a method for leveraging the diversity within the model zoo to improve out-of-distribution generalization capabilities. Specifically, we investigate the behaviors of various pretrained models across different domains of downstream tasks by characterizing the variations in their encoded representations in terms of two dimensions: diversity shift and correlation shift. This characterization enables us to propose a new algorithm for integrating diverse pretrained models, not limited to the strongest models, in order to achieve enhanced out-of-distribution generalization performance. Our proposed method demonstrates state-of-the-art empirical results on a variety of datasets, thus validating the benefits of utilizing diverse knowledge.
Heavy-Tailed Regularization of Weight Matrices in Deep Neural Networks
Apr 07, 2023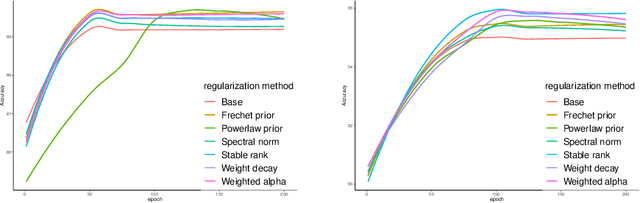
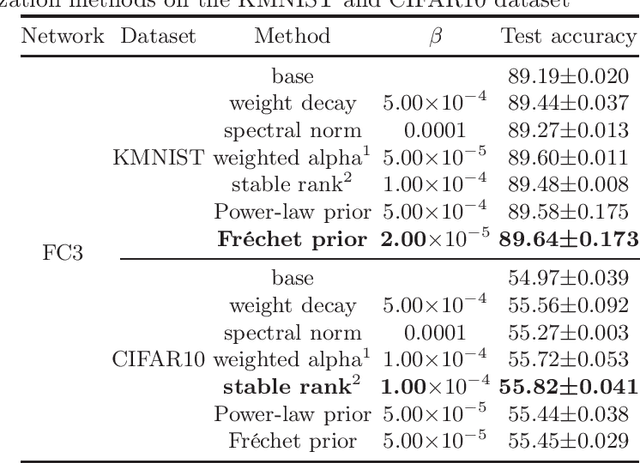

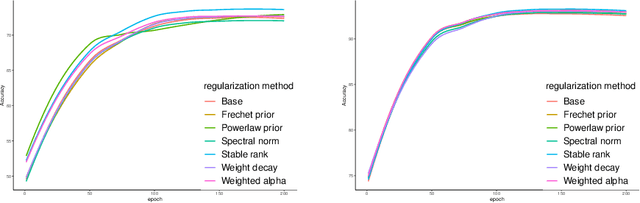
Unraveling the reasons behind the remarkable success and exceptional generalization capabilities of deep neural networks presents a formidable challenge. Recent insights from random matrix theory, specifically those concerning the spectral analysis of weight matrices in deep neural networks, offer valuable clues to address this issue. A key finding indicates that the generalization performance of a neural network is associated with the degree of heavy tails in the spectrum of its weight matrices. To capitalize on this discovery, we introduce a novel regularization technique, termed Heavy-Tailed Regularization, which explicitly promotes a more heavy-tailed spectrum in the weight matrix through regularization. Firstly, we employ the Weighted Alpha and Stable Rank as penalty terms, both of which are differentiable, enabling the direct calculation of their gradients. To circumvent over-regularization, we introduce two variations of the penalty function. Then, adopting a Bayesian statistics perspective and leveraging knowledge from random matrices, we develop two novel heavy-tailed regularization methods, utilizing Powerlaw distribution and Frechet distribution as priors for the global spectrum and maximum eigenvalues, respectively. We empirically show that heavytailed regularization outperforms conventional regularization techniques in terms of generalization performance.
Fair-CDA: Continuous and Directional Augmentation for Group Fairness
Apr 01, 2023In this work, we propose {\it Fair-CDA}, a fine-grained data augmentation strategy for imposing fairness constraints. We use a feature disentanglement method to extract the features highly related to the sensitive attributes. Then we show that group fairness can be achieved by regularizing the models on transition paths of sensitive features between groups. By adjusting the perturbation strength in the direction of the paths, our proposed augmentation is controllable and auditable. To alleviate the accuracy degradation caused by fairness constraints, we further introduce a calibrated model to impute labels for the augmented data. Our proposed method does not assume any data generative model and ensures good generalization for both accuracy and fairness. Experimental results show that Fair-CDA consistently outperforms state-of-the-art methods on widely-used benchmarks, e.g., Adult, CelebA and MovieLens. Especially, Fair-CDA obtains an 86.3\% relative improvement for fairness while maintaining the accuracy on the Adult dataset. Moreover, we evaluate Fair-CDA in an online recommendation system to demonstrate the effectiveness of our method in terms of accuracy and fairness.
ZooD: Exploiting Model Zoo for Out-of-Distribution Generalization
Oct 17, 2022


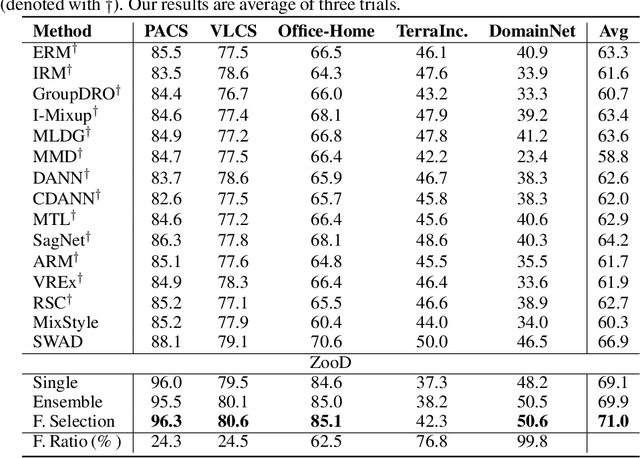
Recent advances on large-scale pre-training have shown great potentials of leveraging a large set of Pre-Trained Models (PTMs) for improving Out-of-Distribution (OoD) generalization, for which the goal is to perform well on possible unseen domains after fine-tuning on multiple training domains. However, maximally exploiting a zoo of PTMs is challenging since fine-tuning all possible combinations of PTMs is computationally prohibitive while accurate selection of PTMs requires tackling the possible data distribution shift for OoD tasks. In this work, we propose ZooD, a paradigm for PTMs ranking and ensemble with feature selection. Our proposed metric ranks PTMs by quantifying inter-class discriminability and inter-domain stability of the features extracted by the PTMs in a leave-one-domain-out cross-validation manner. The top-K ranked models are then aggregated for the target OoD task. To avoid accumulating noise induced by model ensemble, we propose an efficient variational EM algorithm to select informative features. We evaluate our paradigm on a diverse model zoo consisting of 35 models for various OoD tasks and demonstrate: (i) model ranking is better correlated with fine-tuning ranking than previous methods and up to 9859x faster than brute-force fine-tuning; (ii) OoD generalization after model ensemble with feature selection outperforms the state-of-the-art methods and the accuracy on most challenging task DomainNet is improved from 46.5\% to 50.6\%. Furthermore, we provide the fine-tuning results of 35 PTMs on 7 OoD datasets, hoping to help the research of model zoo and OoD generalization. Code will be available at https://gitee.com/mindspore/models/tree/master/research/cv/zood.
Your Contrastive Learning Is Secretly Doing Stochastic Neighbor Embedding
May 30, 2022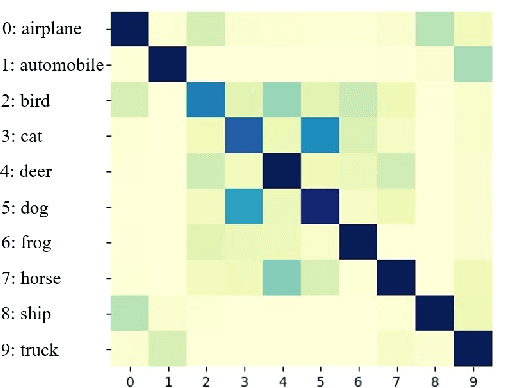

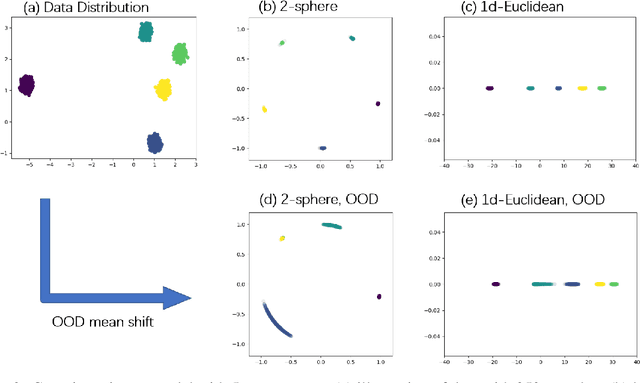
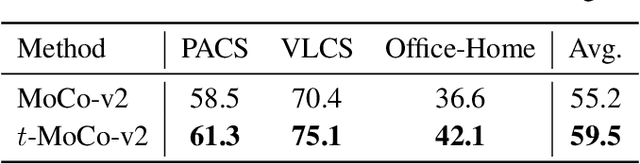
Contrastive learning, especially Self-Supervised Contrastive Learning (SSCL), has achieved great success in extracting powerful features from unlabeled data, enabling comparable performance to the supervised counterpart. In this work, we contribute to the theoretical understanding of SSCL and uncover its connection to the classic data visualization method, Stochastic Neighbor Embedding (SNE). In the perspective of SNE, whose goal is matching pairwise distance, SSCL can be viewed as a special case with the input space pairwise distance specified by constructed "positive" pairs from data augmentation. The established correspondence facilitates deeper theoretical understandings of learned features of SSCL, as well as methodological guidelines for practical improvement. Specifically, through the lens of SNE, not only can we re-derive the alignment and uniformity principle, but also provide novel analysis on domain-agnostic augmentations and implicit bias. To illustrate the practical advantage, we demonstrate that the modifications from SNE to $t$-SNE can also be adopted in the SSCL setting, achieving significant improvement in both in-distribution and out-of-distribution generalization.
MixACM: Mixup-Based Robustness Transfer via Distillation of Activated Channel Maps
Nov 09, 2021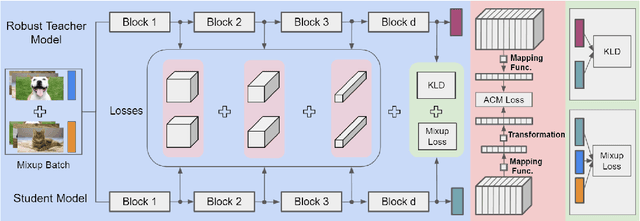
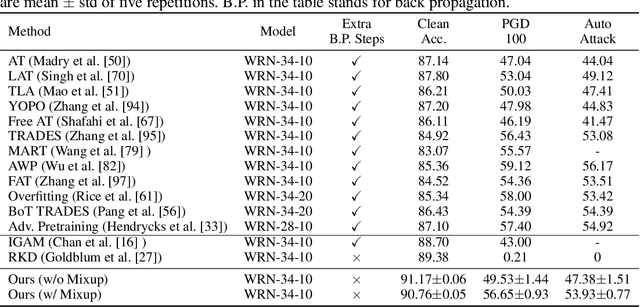

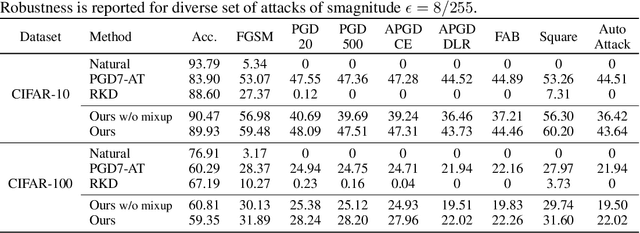
Deep neural networks are susceptible to adversarially crafted, small and imperceptible changes in the natural inputs. The most effective defense mechanism against these examples is adversarial training which constructs adversarial examples during training by iterative maximization of loss. The model is then trained to minimize the loss on these constructed examples. This min-max optimization requires more data, larger capacity models, and additional computing resources. It also degrades the standard generalization performance of a model. Can we achieve robustness more efficiently? In this work, we explore this question from the perspective of knowledge transfer. First, we theoretically show the transferability of robustness from an adversarially trained teacher model to a student model with the help of mixup augmentation. Second, we propose a novel robustness transfer method called Mixup-Based Activated Channel Maps (MixACM) Transfer. MixACM transfers robustness from a robust teacher to a student by matching activated channel maps generated without expensive adversarial perturbations. Finally, extensive experiments on multiple datasets and different learning scenarios show our method can transfer robustness while also improving generalization on natural images.
DHA: End-to-End Joint Optimization of Data Augmentation Policy, Hyper-parameter and Architecture
Sep 13, 2021



Automated machine learning (AutoML) usually involves several crucial components, such as Data Augmentation (DA) policy, Hyper-Parameter Optimization (HPO), and Neural Architecture Search (NAS). Although many strategies have been developed for automating these components in separation, joint optimization of these components remains challenging due to the largely increased search dimension and the variant input types of each component. Meanwhile, conducting these components in a sequence often requires careful coordination by human experts and may lead to sub-optimal results. In parallel to this, the common practice of searching for the optimal architecture first and then retraining it before deployment in NAS often suffers from low performance correlation between the search and retraining stages. An end-to-end solution that integrates the AutoML components and returns a ready-to-use model at the end of the search is desirable. In view of these, we propose DHA, which achieves joint optimization of Data augmentation policy, Hyper-parameter and Architecture. Specifically, end-to-end NAS is achieved in a differentiable manner by optimizing a compressed lower-dimensional feature space, while DA policy and HPO are updated dynamically at the same time. Experiments show that DHA achieves state-of-the-art (SOTA) results on various datasets, especially 77.4\% accuracy on ImageNet with cell based search space, which is higher than current SOTA by 0.5\%. To the best of our knowledge, we are the first to efficiently and jointly optimize DA policy, NAS, and HPO in an end-to-end manner without retraining.
NAS-OoD: Neural Architecture Search for Out-of-Distribution Generalization
Sep 05, 2021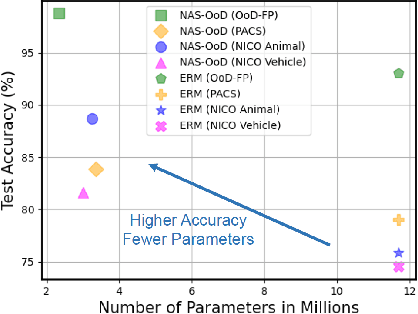



Recent advances on Out-of-Distribution (OoD) generalization reveal the robustness of deep learning models against distribution shifts. However, existing works focus on OoD algorithms, such as invariant risk minimization, domain generalization, or stable learning, without considering the influence of deep model architectures on OoD generalization, which may lead to sub-optimal performance. Neural Architecture Search (NAS) methods search for architecture based on its performance on the training data, which may result in poor generalization for OoD tasks. In this work, we propose robust Neural Architecture Search for OoD generalization (NAS-OoD), which optimizes the architecture with respect to its performance on generated OoD data by gradient descent. Specifically, a data generator is learned to synthesize OoD data by maximizing losses computed by different neural architectures, while the goal for architecture search is to find the optimal architecture parameters that minimize the synthetic OoD data losses. The data generator and the neural architecture are jointly optimized in an end-to-end manner, and the minimax training process effectively discovers robust architectures that generalize well for different distribution shifts. Extensive experimental results show that NAS-OoD achieves superior performance on various OoD generalization benchmarks with deep models having a much fewer number of parameters. In addition, on a real industry dataset, the proposed NAS-OoD method reduces the error rate by more than 70% compared with the state-of-the-art method, demonstrating the proposed method's practicality for real applications.