 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Homogeneous Graph Neural Network for Precoding and Power Allocation in Scalable Wireless Networks
Aug 30, 2024



Deep learning is widely used in wireless communications but struggles with fixed neural network sizes, which limit their adaptability in environments where the number of users and antennas varies. To overcome this, this paper introduced a generalization strategy for precoding and power allocation in scalable wireless networks. Initially, we employ an innovative approach to abstract the wireless network into a homogeneous graph. This primarily focuses on bypassing the heterogeneous features between transmitter (TX) and user entities to construct a virtual homogeneous graph serving optimization objectives, thereby enabling all nodes in the virtual graph to share the same neural network. This "TX entity" is known as a base station (BS) in cellular networks and an access point (AP) in cell-free networks. Subsequently, we design a universal graph neural network, termed the information carrying graph neural network (ICGNN), to capture and integrate information from this graph, maintaining permutation invariance. Lastly, using ICGNN as the core algorithm, we tailor the neural network's input and output for specific problem requirements and validate its performance in two scenarios: 1) in cellular networks, we develop a matrix-inverse-free multi-user multi-input multi-output (MU-MIMO) precoding scheme using the conjugate gradient (CG) method, adaptable to varying user and antenna numbers; 2) in a cell-free network, facing dynamic variations in the number of users served by APs, the number of APs serving each user, and the number of antennas per AP, we propose a universal power allocation scheme. Simulations demonstrate that the proposed approach not only significantly reduces computational complexity but also achieves, and potentially exceeds, the spectral efficiency (SE) of conventional algorithms.
TextBlockV2: Towards Precise-Detection-Free Scene Text Spotting with Pre-trained Language Model
Mar 15, 2024Existing scene text spotters are designed to locate and transcribe texts from images. However, it is challenging for a spotter to achieve precise detection and recognition of scene texts simultaneously. Inspired by the glimpse-focus spotting pipeline of human beings and impressive performances of Pre-trained Language Models (PLMs) on visual tasks, we ask: 1) "Can machines spot texts without precise detection just like human beings?", and if yes, 2) "Is text block another alternative for scene text spotting other than word or character?" To this end, our proposed scene text spotter leverages advanced PLMs to enhance performance without fine-grained detection. Specifically, we first use a simple detector for block-level text detection to obtain rough positional information. Then, we finetune a PLM using a large-scale OCR dataset to achieve accurate recognition. Benefiting from the comprehensive language knowledge gained during the pre-training phase, the PLM-based recognition module effectively handles complex scenarios, including multi-line, reversed, occluded, and incomplete-detection texts. Taking advantage of the fine-tuned language model on scene recognition benchmarks and the paradigm of text block detection, extensive experiments demonstrate the superior performance of our scene text spotter across multiple public benchmarks. Additionally, we attempt to spot texts directly from an entire scene image to demonstrate the potential of PLMs, even Large Language Models (LLMs).
Heavy-Tailed Regularization of Weight Matrices in Deep Neural Networks
Apr 07, 2023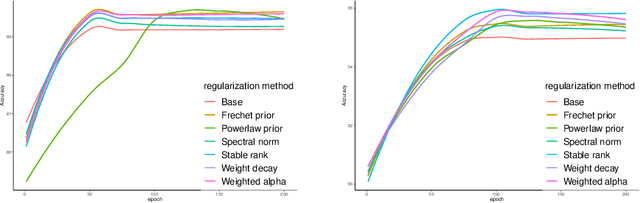
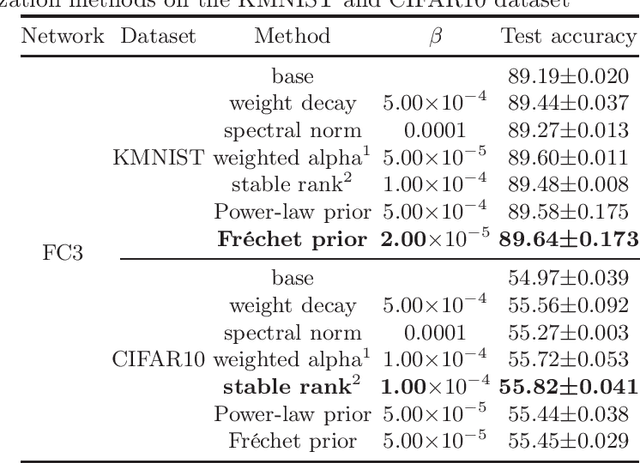

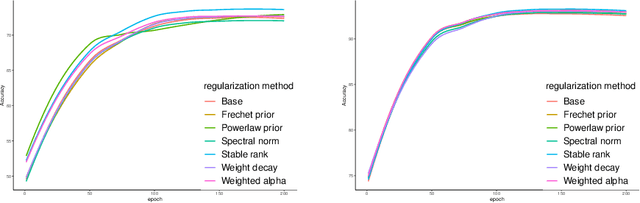
Unraveling the reasons behind the remarkable success and exceptional generalization capabilities of deep neural networks presents a formidable challenge. Recent insights from random matrix theory, specifically those concerning the spectral analysis of weight matrices in deep neural networks, offer valuable clues to address this issue. A key finding indicates that the generalization performance of a neural network is associated with the degree of heavy tails in the spectrum of its weight matrices. To capitalize on this discovery, we introduce a novel regularization technique, termed Heavy-Tailed Regularization, which explicitly promotes a more heavy-tailed spectrum in the weight matrix through regularization. Firstly, we employ the Weighted Alpha and Stable Rank as penalty terms, both of which are differentiable, enabling the direct calculation of their gradients. To circumvent over-regularization, we introduce two variations of the penalty function. Then, adopting a Bayesian statistics perspective and leveraging knowledge from random matrices, we develop two novel heavy-tailed regularization methods, utilizing Powerlaw distribution and Frechet distribution as priors for the global spectrum and maximum eigenvalues, respectively. We empirically show that heavytailed regularization outperforms conventional regularization techniques in terms of generalization performance.
Self-Constrained Inference Optimization on Structural Groups for Human Pose Estimation
Jul 06, 2022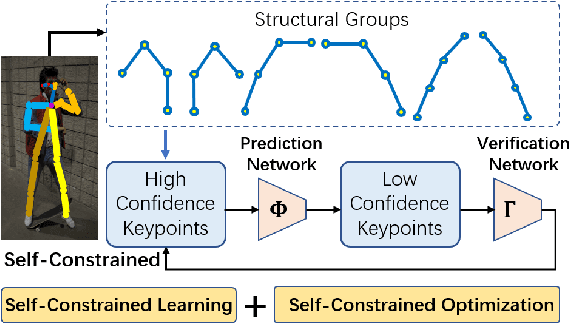
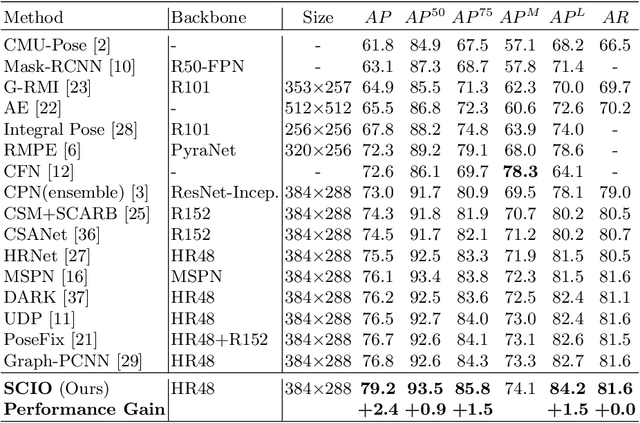
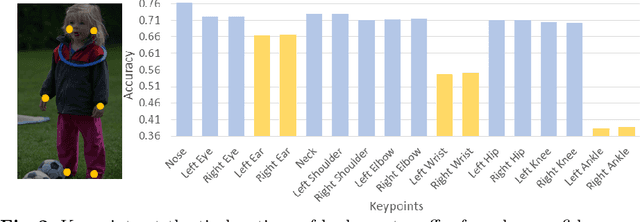

We observe that human poses exhibit strong group-wise structural correlation and spatial coupling between keypoints due to the biological constraints of different body parts. This group-wise structural correlation can be explored to improve the accuracy and robustness of human pose estimation. In this work, we develop a self-constrained prediction-verification network to characterize and learn the structural correlation between keypoints during training. During the inference stage, the feedback information from the verification network allows us to perform further optimization of pose prediction, which significantly improves the performance of human pose estimation. Specifically, we partition the keypoints into groups according to the biological structure of human body. Within each group, the keypoints are further partitioned into two subsets, high-confidence base keypoints and low-confidence terminal keypoints. We develop a self-constrained prediction-verification network to perform forward and backward predictions between these keypoint subsets. One fundamental challenge in pose estimation, as well as in generic prediction tasks, is that there is no mechanism for us to verify if the obtained pose estimation or prediction results are accurate or not, since the ground truth is not available. Once successfully learned, the verification network serves as an accuracy verification module for the forward pose prediction. During the inference stage, it can be used to guide the local optimization of the pose estimation results of low-confidence keypoints with the self-constrained loss on high-confidence keypoints as the objective function. Our extensive experimental results on benchmark MS COCO and CrowdPose datasets demonstrate that the proposed method can significantly improve the pose estimation results.
Sparse Linear Spectral Unmixing of Hyperspectral images using Expectation-Propagation
Jun 18, 2021
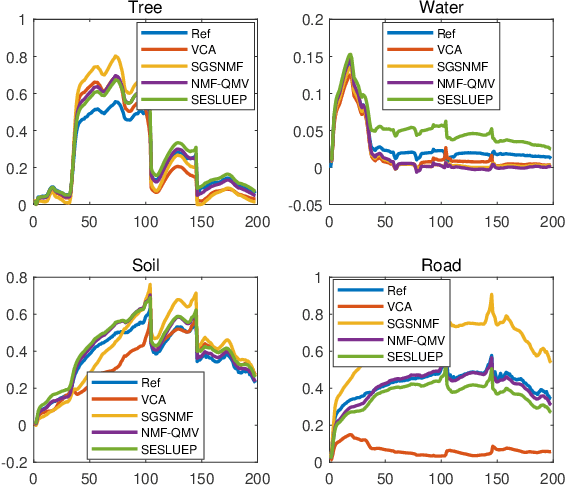
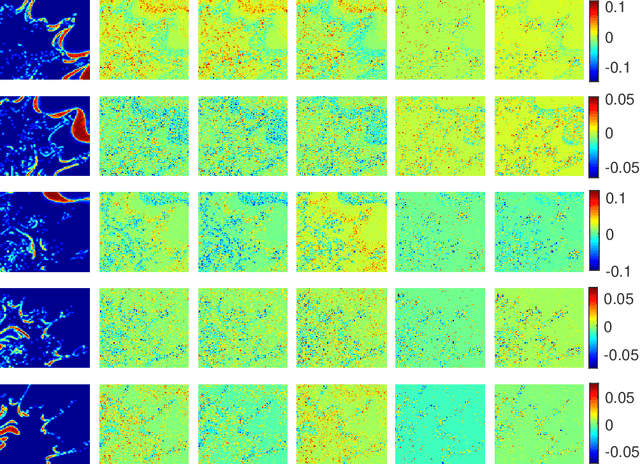
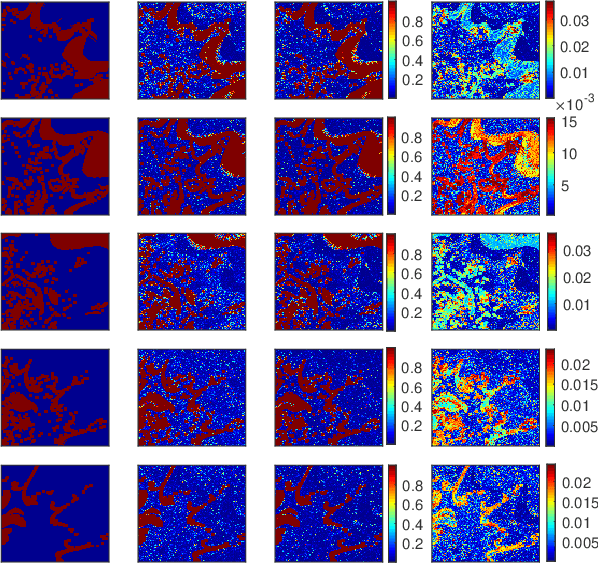
This paper presents a novel Bayesian approach for hyperspectral image unmixing. The observed pixels are modeled by a linear combination of material signatures weighted by their corresponding abundances. A spike-and-slab abundance prior is adopted to promote sparse mixtures and an Ising prior model is used to capture spatial correlation of the mixture support across pixels. We approximate the posterior distribution of the abundances using the expectation-propagation (EP) method. We show that it can significantly reduce the computational complexity of the unmixing stage and meanwhile provide uncertainty measures, compared to expensive Monte Carlo strategies traditionally considered for uncertainty quantification. Moreover, many variational parameters within each EP factor can be updated in a parallel manner, which enables mapping of efficient algorithmic architectures based on graphics processing units (GPU). Under the same approximate Bayesian framework, we then extend the proposed algorithm to semi-supervised unmixing, whereby the abundances are viewed as latent variables and the expectation-maximization (EM) algorithm is used to refine the endmember matrix. Experimental results on synthetic data and real hyperspectral data illustrate the benefits of the proposed framework over state-of-art linear unmixing methods.
Provable More Data Hurt in High Dimensional Least Squares Estimator
Aug 14, 2020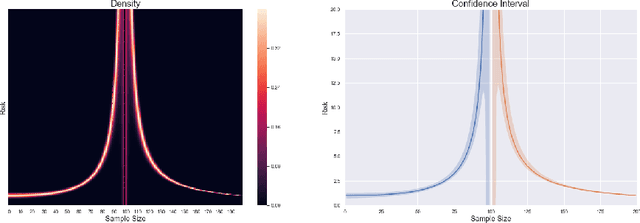
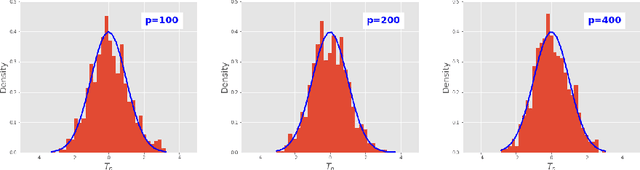
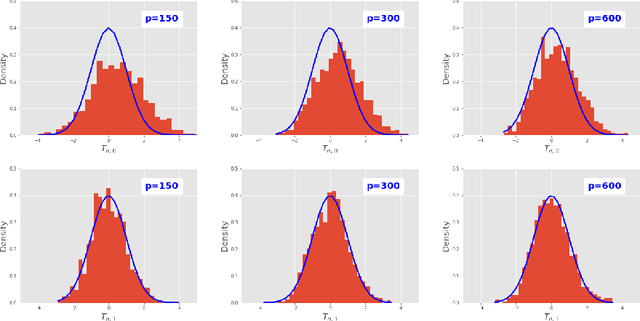
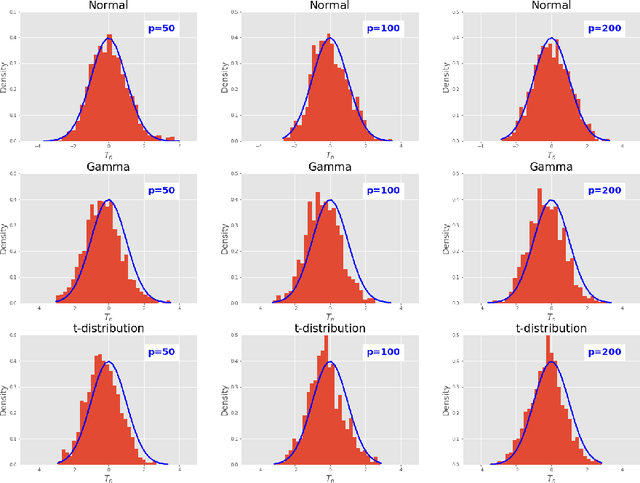
This paper investigates the finite-sample prediction risk of the high-dimensional least squares estimator. We derive the central limit theorem for the prediction risk when both the sample size and the number of features tend to infinity. Furthermore, the finite-sample distribution and the confidence interval of the prediction risk are provided. Our theoretical results demonstrate the sample-wise nonmonotonicity of the prediction risk and confirm "more data hurt" phenomenon.