 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe NeurIPS 2022 Neural MMO Challenge: A Massively Multiagent Competition with Specialization and Trade
Nov 07, 2023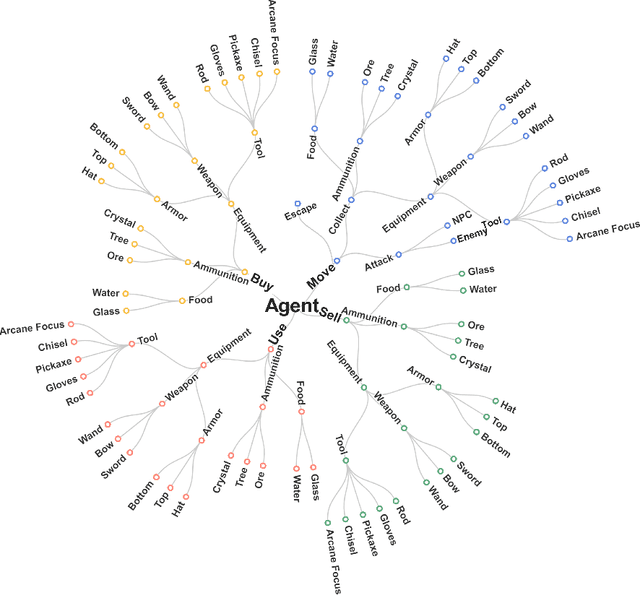



In this paper, we present the results of the NeurIPS-2022 Neural MMO Challenge, which attracted 500 participants and received over 1,600 submissions. Like the previous IJCAI-2022 Neural MMO Challenge, it involved agents from 16 populations surviving in procedurally generated worlds by collecting resources and defeating opponents. This year's competition runs on the latest v1.6 Neural MMO, which introduces new equipment, combat, trading, and a better scoring system. These elements combine to pose additional robustness and generalization challenges not present in previous competitions. This paper summarizes the design and results of the challenge, explores the potential of this environment as a benchmark for learning methods, and presents some practical reinforcement learning training approaches for complex tasks with sparse rewards. Additionally, we have open-sourced our baselines, including environment wrappers, benchmarks, and visualization tools for future research.
Progression Cognition Reinforcement Learning with Prioritized Experience for Multi-Vehicle Pursuit
Jun 08, 2023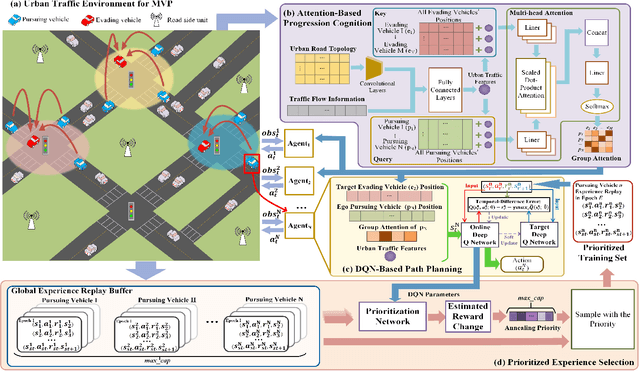
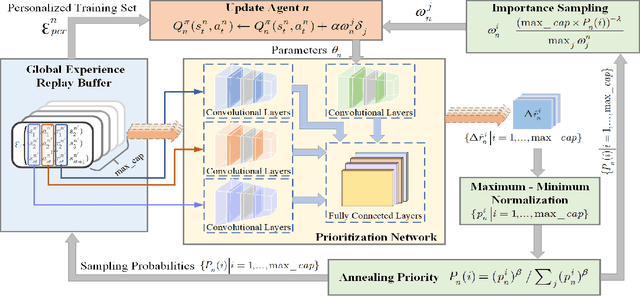

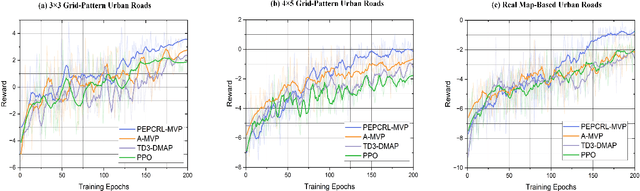
Multi-vehicle pursuit (MVP) such as autonomous police vehicles pursuing suspects is important but very challenging due to its mission and safety critical nature. While multi-agent reinforcement learning (MARL) algorithms have been proposed for MVP problem in structured grid-pattern roads, the existing algorithms use randomly training samples in centralized learning, which leads to homogeneous agents showing low collaboration performance. For the more challenging problem of pursuing multiple evading vehicles, these algorithms typically select a fixed target evading vehicle for pursuing vehicles without considering dynamic traffic situation, which significantly reduces pursuing success rate. To address the above problems, this paper proposes a Progression Cognition Reinforcement Learning with Prioritized Experience for MVP (PEPCRL-MVP) in urban multi-intersection dynamic traffic scenes. PEPCRL-MVP uses a prioritization network to assess the transitions in the global experience replay buffer according to the parameters of each MARL agent. With the personalized and prioritized experience set selected via the prioritization network, diversity is introduced to the learning process of MARL, which can improve collaboration and task related performance. Furthermore, PEPCRL-MVP employs an attention module to extract critical features from complex urban traffic environments. These features are used to develop progression cognition method to adaptively group pursuing vehicles. Each group efficiently target one evading vehicle in dynamic driving environments. Extensive experiments conducted with a simulator over unstructured roads of an urban area show that PEPCRL-MVP is superior to other state-of-the-art methods. Specifically, PEPCRL-MVP improves pursuing efficiency by 3.95% over TD3-DMAP and its success rate is 34.78% higher than that of MADDPG. Codes are open sourced.
Graded-Q Reinforcement Learning with Information-Enhanced State Encoder for Hierarchical Collaborative Multi-Vehicle Pursuit
Oct 24, 2022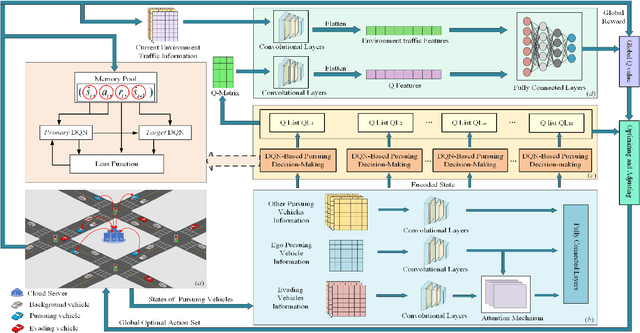
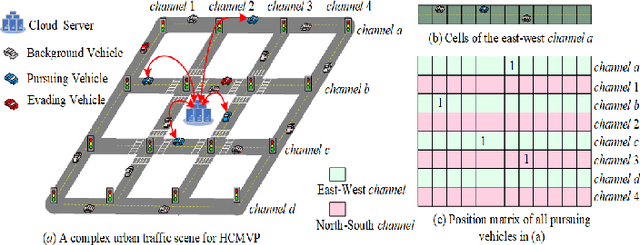
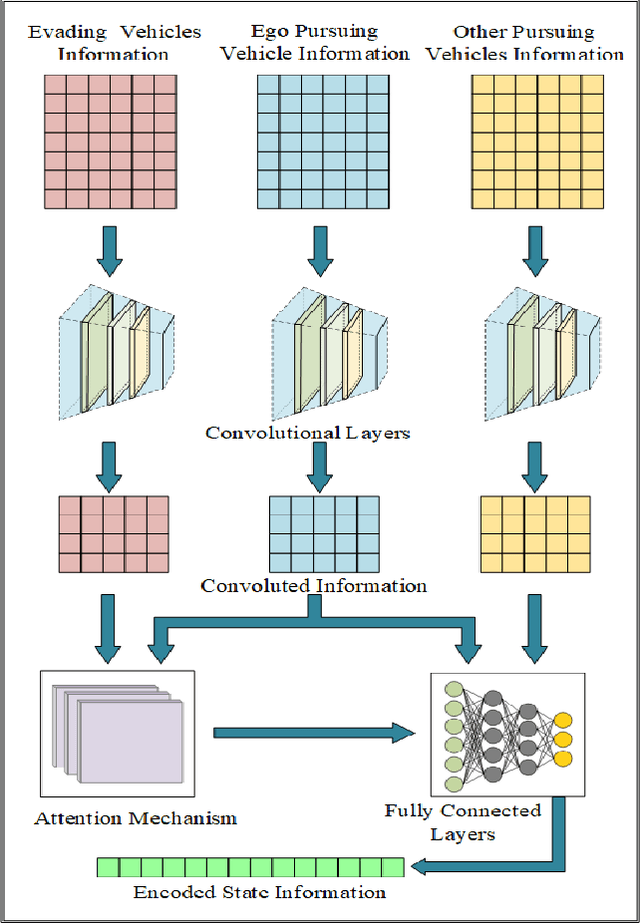
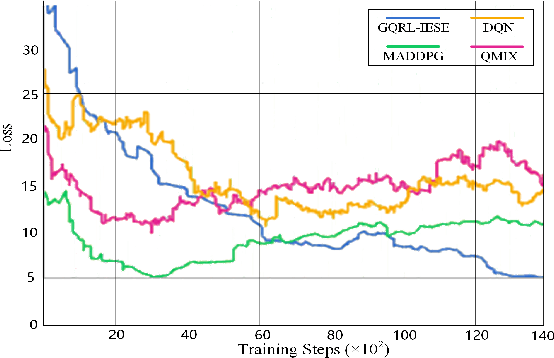
The multi-vehicle pursuit (MVP), as a problem abstracted from various real-world scenarios, is becoming a hot research topic in Intelligent Transportation System (ITS). The combination of Artificial Intelligence (AI) and connected vehicles has greatly promoted the research development of MVP. However, existing works on MVP pay little attention to the importance of information exchange and cooperation among pursuing vehicles under the complex urban traffic environment. This paper proposed a graded-Q reinforcement learning with information-enhanced state encoder (GQRL-IESE) framework to address this hierarchical collaborative multi-vehicle pursuit (HCMVP) problem. In the GQRL-IESE, a cooperative graded Q scheme is proposed to facilitate the decision-making of pursuing vehicles to improve pursuing efficiency. Each pursuing vehicle further uses a deep Q network (DQN) to make decisions based on its encoded state. A coordinated Q optimizing network adjusts the individual decisions based on the current environment traffic information to obtain the global optimal action set. In addition, an information-enhanced state encoder is designed to extract critical information from multiple perspectives and uses the attention mechanism to assist each pursuing vehicle in effectively determining the target. Extensive experimental results based on SUMO indicate that the total timestep of the proposed GQRL-IESE is less than other methods on average by 47.64%, which demonstrates the excellent pursuing efficiency of the GQRL-IESE. Codes are outsourced in https://github.com/ANT-ITS/GQRL-IESE.
Confidence Estimation Transformer for Long-term Renewable Energy Forecasting in Reinforcement Learning-based Power Grid Dispatching
Apr 10, 2022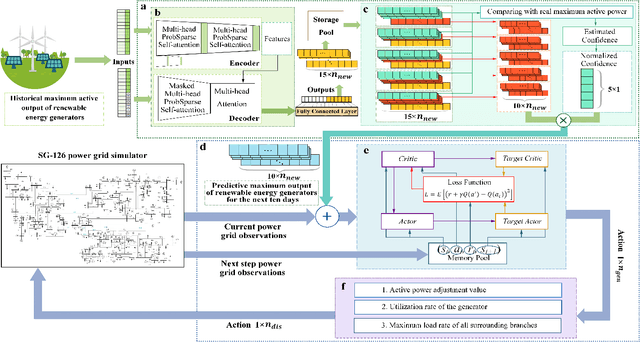
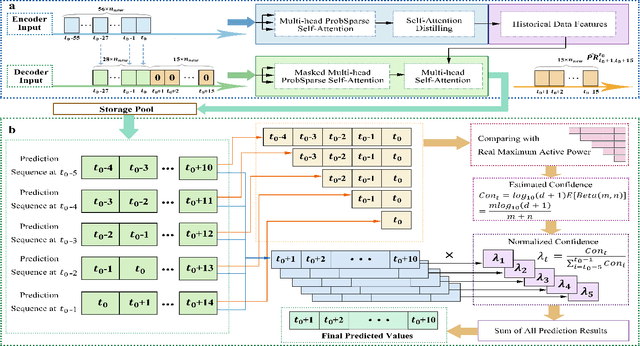
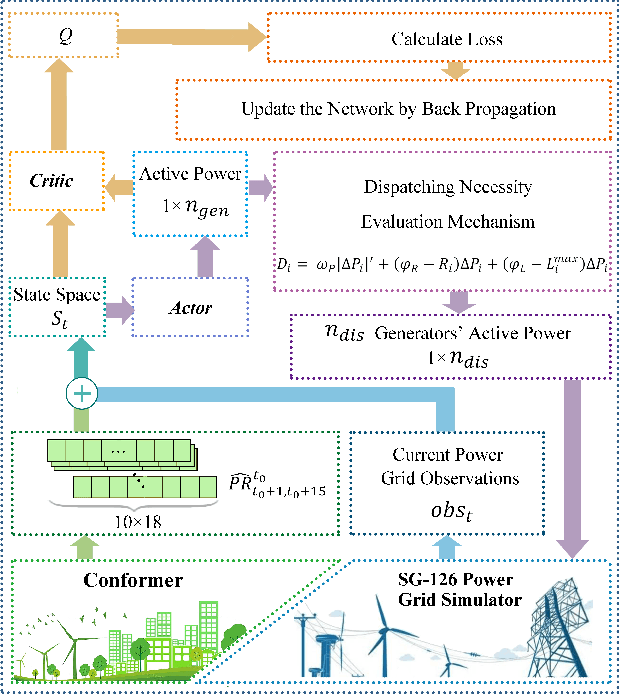
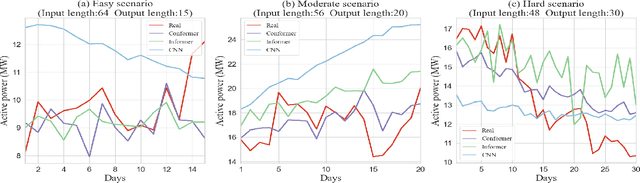
The expansion of renewable energy could help realizing the goals of peaking carbon dioxide emissions and carbon neutralization. Some existing grid dispatching methods integrating short-term renewable energy prediction and reinforcement learning (RL) have been proved to alleviate the adverse impact of energy fluctuations risk. However, these methods omit the long-term output prediction, which leads to stability and security problems on the optimal power flow. This paper proposes a confidence estimation Transformer for long-term renewable energy forecasting in reinforcement learning-based power grid dispatching (Conformer-RLpatching). Conformer-RLpatching predicts long-term active output of each renewable energy generator with an enhanced Transformer to boost the performance of hybrid energy grid dispatching. Furthermore, a confidence estimation method is proposed to reduce the prediction error of renewable energy. Meanwhile, a dispatching necessity evaluation mechanism is put forward to decide whether the active output of a generator needs to be adjusted. Experiments carried out on the SG-126 power grid simulator show that Conformer-RLpatching achieves great improvement over the second best algorithm DDPG in security score by 25.8% and achieves a better total reward compared with the golden medal team in the power grid dispatching competition sponsored by State Grid Corporation of China under the same simulation environment. Codes are outsourced in https://github.com/buptlxh/Conformer-RLpatching.
$ \text{T}^3 $OMVP: A Transformer-based Time and Team Reinforcement Learning Scheme for Observation-constrained Multi-Vehicle Pursuit in Urban Area
Mar 04, 2022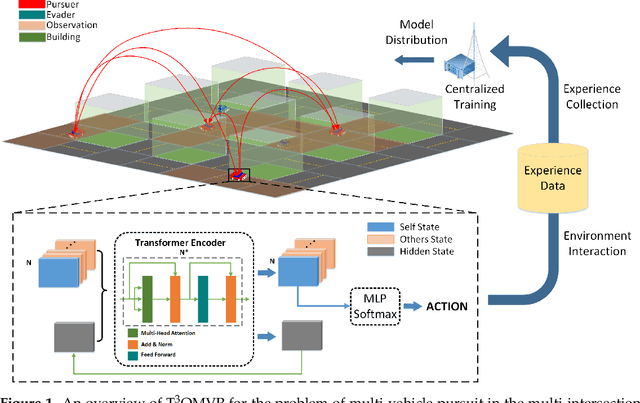

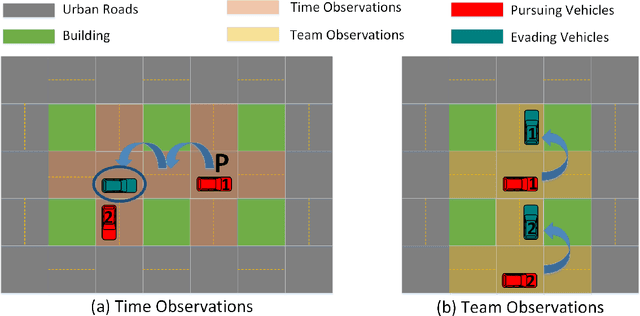
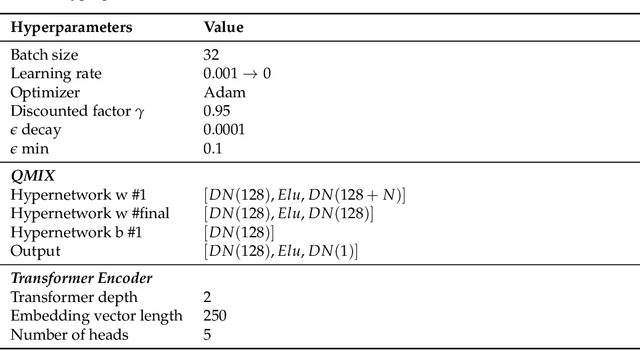
Smart Internet of Vehicles (IoVs) combined with Artificial Intelligence (AI) will contribute to vehicle decision-making in the Intelligent Transportation System (ITS). Multi-Vehicle Pursuit games (MVP), a multi-vehicle cooperative ability to capture mobile targets, is becoming a hot research topic gradually. Although there are some achievements in the field of MVP in the open space environment, the urban area brings complicated road structures and restricted moving spaces as challenges to the resolution of MVP games. We define an Observation-constrained MVP (OMVP) problem in this paper and propose a Transformer-based Time and Team Reinforcement Learning scheme ($ \text{T}^3 $OMVP) to address the problem. First, a new multi-vehicle pursuit model is constructed based on decentralized partially observed Markov decision processes (Dec-POMDP) to instantiate this problem. Second, by introducing and modifying the transformer-based observation sequence, QMIX is redefined to adapt to the complicated road structure, restricted moving spaces and constrained observations, so as to control vehicles to pursue the target combining the vehicle's observations. Third, a multi-intersection urban environment is built to verify the proposed scheme. Extensive experimental results demonstrate that the proposed $ \text{T}^3 $OMVP scheme achieves significant improvements relative to state-of-the-art QMIX approaches by 9.66%~106.25%. Code is available at https://github.com/pipihaiziguai/T3OMVP.
Provable More Data Hurt in High Dimensional Least Squares Estimator
Aug 14, 2020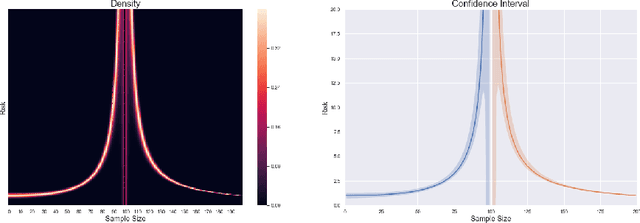
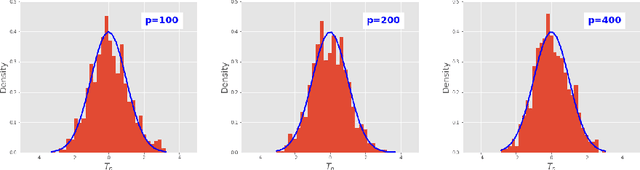
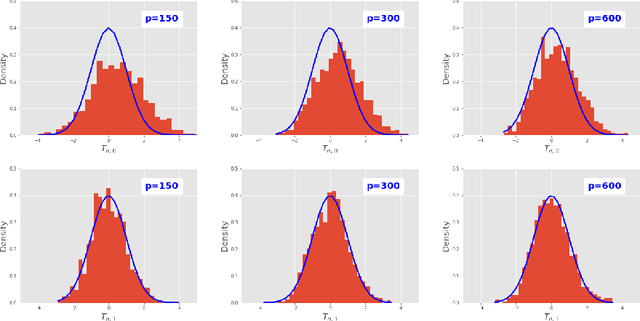
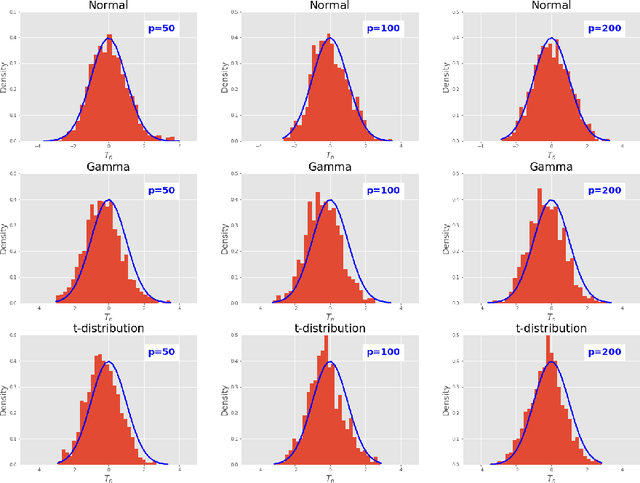
This paper investigates the finite-sample prediction risk of the high-dimensional least squares estimator. We derive the central limit theorem for the prediction risk when both the sample size and the number of features tend to infinity. Furthermore, the finite-sample distribution and the confidence interval of the prediction risk are provided. Our theoretical results demonstrate the sample-wise nonmonotonicity of the prediction risk and confirm "more data hurt" phenomenon.