 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCuraLight: Debate-Guided Data Curation for LLM-Centered Traffic Signal Control
Apr 07, 2026Traffic signal control (TSC) is a core component of intelligent transportation systems (ITS), aiming to reduce congestion, emissions, and travel time. Recent approaches based on reinforcement learning (RL) and large language models (LLMs) have improved adaptivity, but still suffer from limited interpretability, insufficient interaction data, and weak generalization to heterogeneous intersections. This paper proposes CuraLight, an LLM-centered framework where an RL agent assists the fine-tuning of an LLM-based traffic signal controller. The RL agent explores traffic environments and generates high-quality interaction trajectories, which are converted into prompt-response pairs for imitation fine-tuning. A multi-LLM ensemble deliberation system further evaluates candidate signal timing actions through structured debate, providing preference-aware supervision signals for training. Experiments conducted in SUMO across heterogeneous real-world networks from Jinan, Hangzhou, and Yizhuang demonstrate that CuraLight consistently outperforms state-of-the-art baselines, reducing average travel time by 5.34 percent, average queue length by 5.14 percent, and average waiting time by 7.02 percent. The results highlight the effectiveness of combining RL-assisted exploration with deliberation-based data curation for scalable and interpretable traffic signal control.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Retrieval Augmented Generation-Enhanced Distributed LLM Agents for Generalizable Traffic Signal Control with Emergency Vehicles
Oct 30, 2025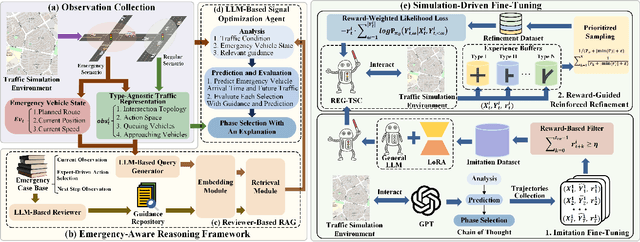
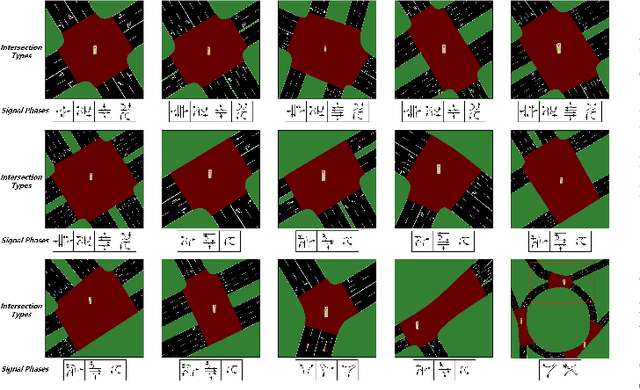
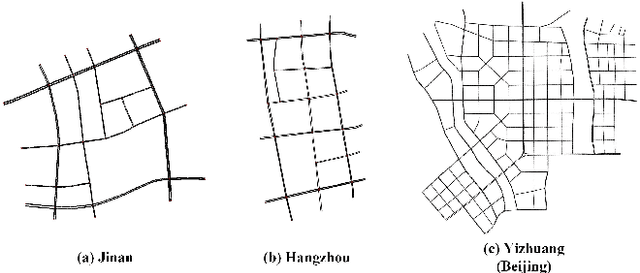
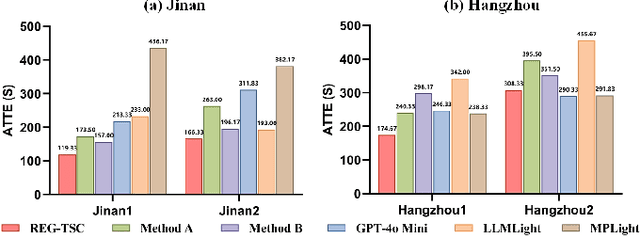
With increasing urban traffic complexity, Traffic Signal Control (TSC) is essential for optimizing traffic flow and improving road safety. Large Language Models (LLMs) emerge as promising approaches for TSC. However, they are prone to hallucinations in emergencies, leading to unreliable decisions that may cause substantial delays for emergency vehicles. Moreover, diverse intersection types present substantial challenges for traffic state encoding and cross-intersection training, limiting generalization across heterogeneous intersections. Therefore, this paper proposes Retrieval Augmented Generation (RAG)-enhanced distributed LLM agents with Emergency response for Generalizable TSC (REG-TSC). Firstly, this paper presents an emergency-aware reasoning framework, which dynamically adjusts reasoning depth based on the emergency scenario and is equipped with a novel Reviewer-based Emergency RAG (RERAG) to distill specific knowledge and guidance from historical cases, enhancing the reliability and rationality of agents' emergency decisions. Secondly, this paper designs a type-agnostic traffic representation and proposes a Reward-guided Reinforced Refinement (R3) for heterogeneous intersections. R3 adaptively samples training experience from diverse intersections with environment feedback-based priority and fine-tunes LLM agents with a designed reward-weighted likelihood loss, guiding REG-TSC toward high-reward policies across heterogeneous intersections. On three real-world road networks with 17 to 177 heterogeneous intersections, extensive experiments show that REG-TSC reduces travel time by 42.00%, queue length by 62.31%, and emergency vehicle waiting time by 83.16%, outperforming other state-of-the-art methods.
E4SRec: An Elegant Effective Efficient Extensible Solution of Large Language Models for Sequential Recommendation
Dec 05, 2023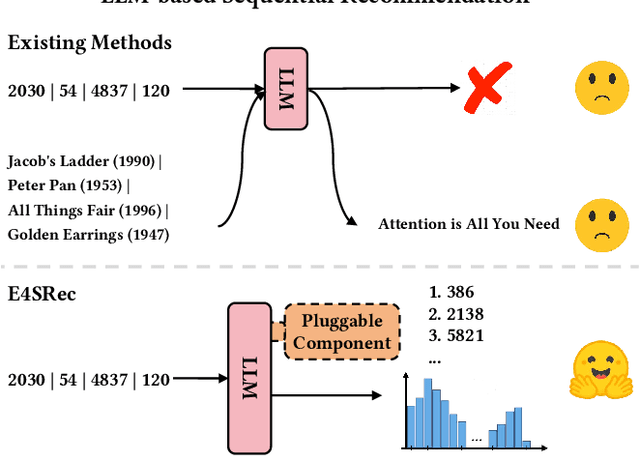

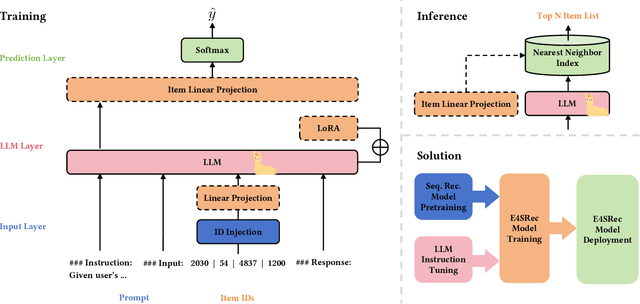
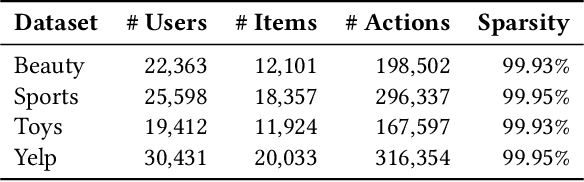
The recent advancements in Large Language Models (LLMs) have sparked interest in harnessing their potential within recommender systems. Since LLMs are designed for natural language tasks, existing recommendation approaches have predominantly transformed recommendation tasks into open-domain natural language generation tasks. However, this approach necessitates items to possess rich semantic information, often generates out-of-range results, and suffers from notably low efficiency and limited extensibility. Furthermore, practical ID-based recommendation strategies, reliant on a huge number of unique identities (IDs) to represent users and items, have gained prominence in real-world recommender systems due to their effectiveness and efficiency. Nevertheless, the incapacity of LLMs to model IDs presents a formidable challenge when seeking to leverage LLMs for personalized recommendations. In this paper, we introduce an Elegant Effective Efficient Extensible solution for large language models for Sequential Recommendation (E4SRec), which seamlessly integrates LLMs with traditional recommender systems that exclusively utilize IDs to represent items. Specifically, E4SRec takes ID sequences as inputs, ensuring that the generated outputs fall within the candidate lists. Furthermore, E4SRec possesses the capability to generate the entire ranking list in a single forward process, and demands only a minimal set of pluggable parameters, which are trained for each dataset while keeping the entire LLM frozen. We substantiate the effectiveness, efficiency, and extensibility of our proposed E4SRec through comprehensive experiments conducted on four widely-used real-world datasets. The implementation code is accessible at https://github.com/HestiaSky/E4SRec/.
The NeurIPS 2022 Neural MMO Challenge: A Massively Multiagent Competition with Specialization and Trade
Nov 07, 2023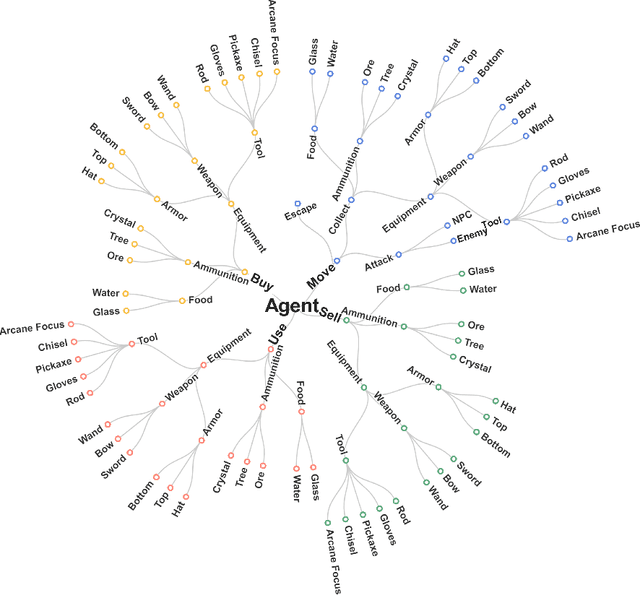



In this paper, we present the results of the NeurIPS-2022 Neural MMO Challenge, which attracted 500 participants and received over 1,600 submissions. Like the previous IJCAI-2022 Neural MMO Challenge, it involved agents from 16 populations surviving in procedurally generated worlds by collecting resources and defeating opponents. This year's competition runs on the latest v1.6 Neural MMO, which introduces new equipment, combat, trading, and a better scoring system. These elements combine to pose additional robustness and generalization challenges not present in previous competitions. This paper summarizes the design and results of the challenge, explores the potential of this environment as a benchmark for learning methods, and presents some practical reinforcement learning training approaches for complex tasks with sparse rewards. Additionally, we have open-sourced our baselines, including environment wrappers, benchmarks, and visualization tools for future research.
Contrastive Graph Pooling for Explainable Classification of Brain Networks
Jul 07, 2023



Functional magnetic resonance imaging (fMRI) is a commonly used technique to measure neural activation. Its application has been particularly important in identifying underlying neurodegenerative conditions such as Parkinson's, Alzheimer's, and Autism. Recent analysis of fMRI data models the brain as a graph and extracts features by graph neural networks (GNNs). However, the unique characteristics of fMRI data require a special design of GNN. Tailoring GNN to generate effective and domain-explainable features remains challenging. In this paper, we propose a contrastive dual-attention block and a differentiable graph pooling method called ContrastPool to better utilize GNN for brain networks, meeting fMRI-specific requirements. We apply our method to 5 resting-state fMRI brain network datasets of 3 diseases and demonstrate its superiority over state-of-the-art baselines. Our case study confirms that the patterns extracted by our method match the domain knowledge in neuroscience literature, and disclose direct and interesting insights. Our contributions underscore the potential of ContrastPool for advancing the understanding of brain networks and neurodegenerative conditions.
OpenSiteRec: An Open Dataset for Site Recommendation
Jul 03, 2023



As a representative information retrieval task, site recommendation, which aims at predicting the optimal sites for a brand or an institution to open new branches in an automatic data-driven way, is beneficial and crucial for brand development in modern business. However, there is no publicly available dataset so far and most existing approaches are limited to an extremely small scope of brands, which seriously hinders the research on site recommendation. Therefore, we collect, construct and release an open comprehensive dataset, namely OpenSiteRec, to facilitate and promote the research on site recommendation. Specifically, OpenSiteRec leverages a heterogeneous graph schema to represent various types of real-world entities and relations in four international metropolises. To evaluate the performance of the existing general methods on the site recommendation task, we conduct benchmarking experiments of several representative recommendation models on OpenSiteRec. Furthermore, we also highlight the potential application directions to demonstrate the wide applicability of OpenSiteRec. We believe that our OpenSiteRec dataset is significant and anticipated to encourage the development of advanced methods for site recommendation. OpenSiteRec is available online at https://OpenSiteRec.github.io/.
Progression Cognition Reinforcement Learning with Prioritized Experience for Multi-Vehicle Pursuit
Jun 08, 2023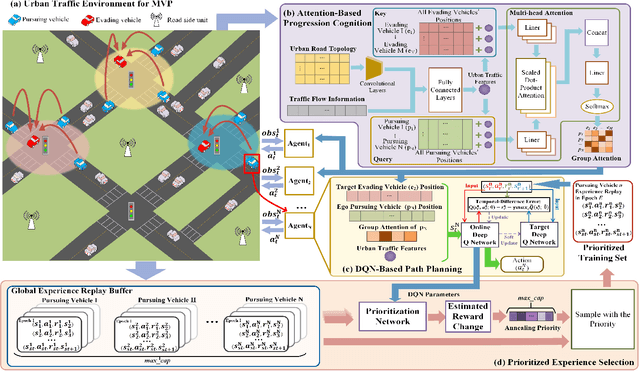
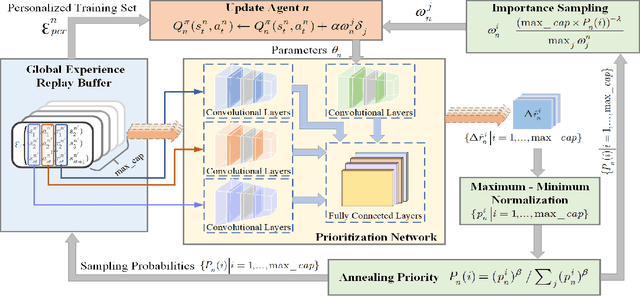

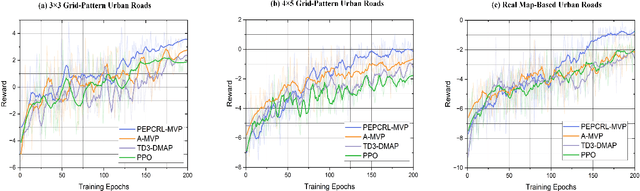
Multi-vehicle pursuit (MVP) such as autonomous police vehicles pursuing suspects is important but very challenging due to its mission and safety critical nature. While multi-agent reinforcement learning (MARL) algorithms have been proposed for MVP problem in structured grid-pattern roads, the existing algorithms use randomly training samples in centralized learning, which leads to homogeneous agents showing low collaboration performance. For the more challenging problem of pursuing multiple evading vehicles, these algorithms typically select a fixed target evading vehicle for pursuing vehicles without considering dynamic traffic situation, which significantly reduces pursuing success rate. To address the above problems, this paper proposes a Progression Cognition Reinforcement Learning with Prioritized Experience for MVP (PEPCRL-MVP) in urban multi-intersection dynamic traffic scenes. PEPCRL-MVP uses a prioritization network to assess the transitions in the global experience replay buffer according to the parameters of each MARL agent. With the personalized and prioritized experience set selected via the prioritization network, diversity is introduced to the learning process of MARL, which can improve collaboration and task related performance. Furthermore, PEPCRL-MVP employs an attention module to extract critical features from complex urban traffic environments. These features are used to develop progression cognition method to adaptively group pursuing vehicles. Each group efficiently target one evading vehicle in dynamic driving environments. Extensive experiments conducted with a simulator over unstructured roads of an urban area show that PEPCRL-MVP is superior to other state-of-the-art methods. Specifically, PEPCRL-MVP improves pursuing efficiency by 3.95% over TD3-DMAP and its success rate is 34.78% higher than that of MADDPG. Codes are open sourced.
IMF: Interactive Multimodal Fusion Model for Link Prediction
Mar 20, 2023Link prediction aims to identify potential missing triples in knowledge graphs. To get better results, some recent studies have introduced multimodal information to link prediction. However, these methods utilize multimodal information separately and neglect the complicated interaction between different modalities. In this paper, we aim at better modeling the inter-modality information and thus introduce a novel Interactive Multimodal Fusion (IMF) model to integrate knowledge from different modalities. To this end, we propose a two-stage multimodal fusion framework to preserve modality-specific knowledge as well as take advantage of the complementarity between different modalities. Instead of directly projecting different modalities into a unified space, our multimodal fusion module limits the representations of different modalities independent while leverages bilinear pooling for fusion and incorporates contrastive learning as additional constraints. Furthermore, the decision fusion module delivers the learned weighted average over the predictions of all modalities to better incorporate the complementarity of different modalities. Our approach has been demonstrated to be effective through empirical evaluations on several real-world datasets. The implementation code is available online at https://github.com/HestiaSky/IMF-Pytorch.
Graded-Q Reinforcement Learning with Information-Enhanced State Encoder for Hierarchical Collaborative Multi-Vehicle Pursuit
Oct 24, 2022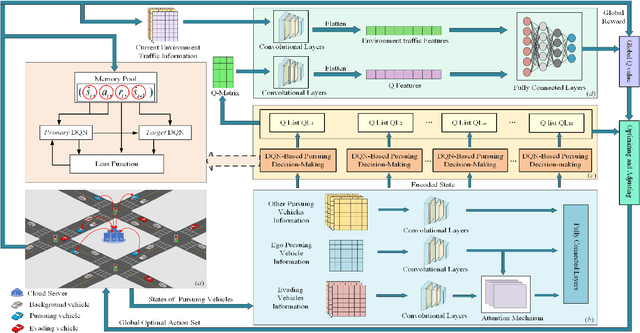
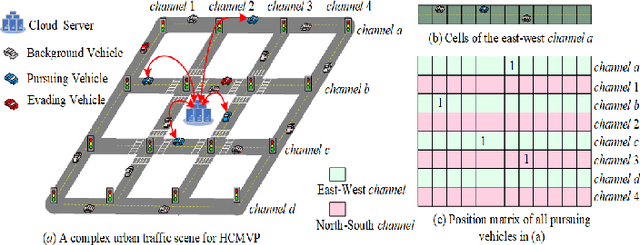
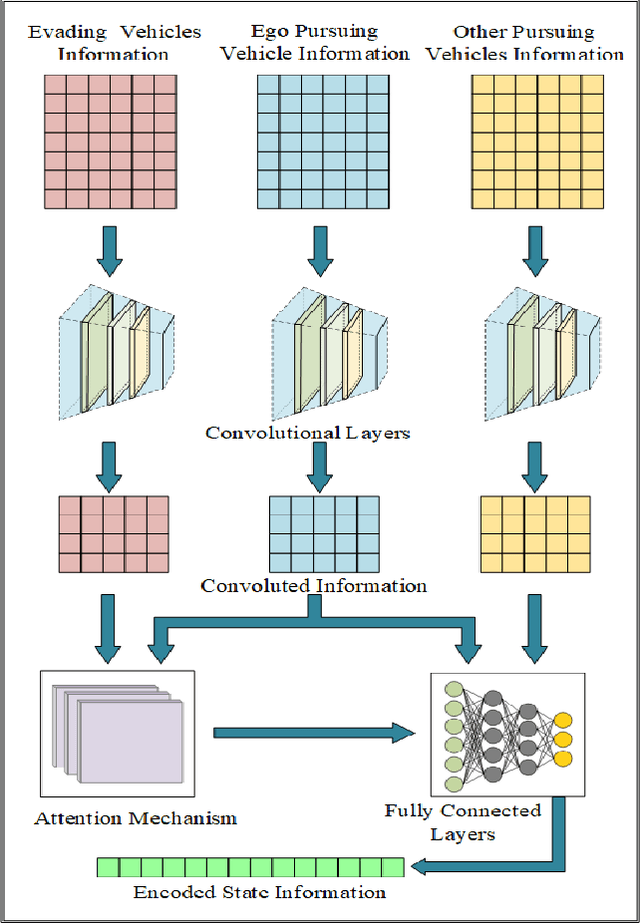
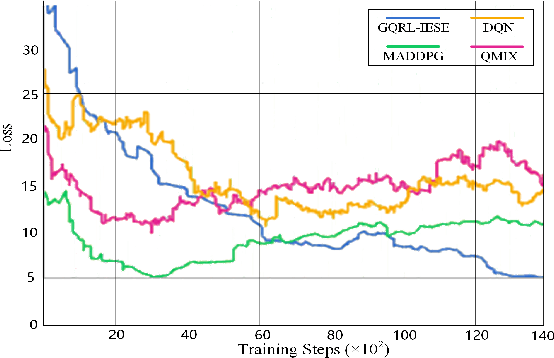
The multi-vehicle pursuit (MVP), as a problem abstracted from various real-world scenarios, is becoming a hot research topic in Intelligent Transportation System (ITS). The combination of Artificial Intelligence (AI) and connected vehicles has greatly promoted the research development of MVP. However, existing works on MVP pay little attention to the importance of information exchange and cooperation among pursuing vehicles under the complex urban traffic environment. This paper proposed a graded-Q reinforcement learning with information-enhanced state encoder (GQRL-IESE) framework to address this hierarchical collaborative multi-vehicle pursuit (HCMVP) problem. In the GQRL-IESE, a cooperative graded Q scheme is proposed to facilitate the decision-making of pursuing vehicles to improve pursuing efficiency. Each pursuing vehicle further uses a deep Q network (DQN) to make decisions based on its encoded state. A coordinated Q optimizing network adjusts the individual decisions based on the current environment traffic information to obtain the global optimal action set. In addition, an information-enhanced state encoder is designed to extract critical information from multiple perspectives and uses the attention mechanism to assist each pursuing vehicle in effectively determining the target. Extensive experimental results based on SUMO indicate that the total timestep of the proposed GQRL-IESE is less than other methods on average by 47.64%, which demonstrates the excellent pursuing efficiency of the GQRL-IESE. Codes are outsourced in https://github.com/ANT-ITS/GQRL-IESE.