 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE4SRec: An Elegant Effective Efficient Extensible Solution of Large Language Models for Sequential Recommendation
Dec 05, 2023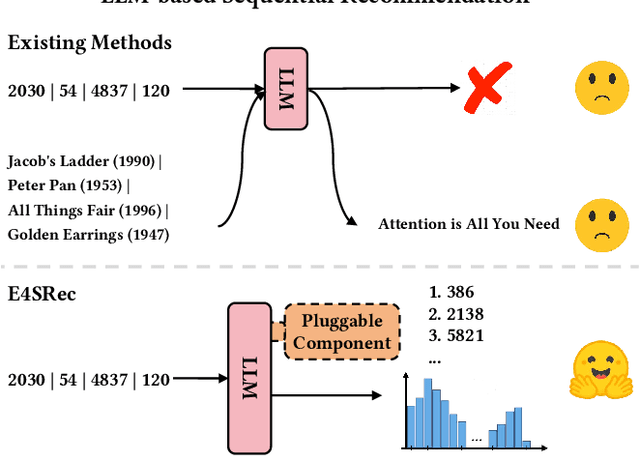

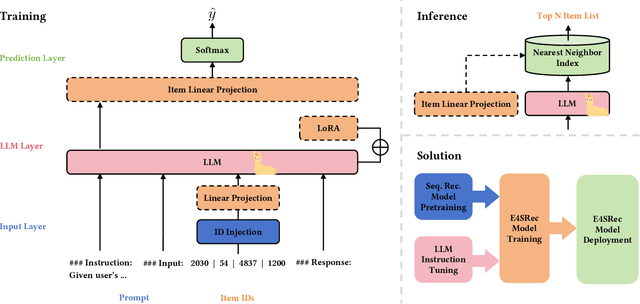
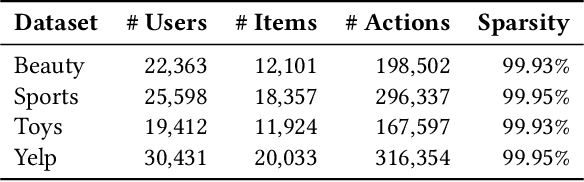
The recent advancements in Large Language Models (LLMs) have sparked interest in harnessing their potential within recommender systems. Since LLMs are designed for natural language tasks, existing recommendation approaches have predominantly transformed recommendation tasks into open-domain natural language generation tasks. However, this approach necessitates items to possess rich semantic information, often generates out-of-range results, and suffers from notably low efficiency and limited extensibility. Furthermore, practical ID-based recommendation strategies, reliant on a huge number of unique identities (IDs) to represent users and items, have gained prominence in real-world recommender systems due to their effectiveness and efficiency. Nevertheless, the incapacity of LLMs to model IDs presents a formidable challenge when seeking to leverage LLMs for personalized recommendations. In this paper, we introduce an Elegant Effective Efficient Extensible solution for large language models for Sequential Recommendation (E4SRec), which seamlessly integrates LLMs with traditional recommender systems that exclusively utilize IDs to represent items. Specifically, E4SRec takes ID sequences as inputs, ensuring that the generated outputs fall within the candidate lists. Furthermore, E4SRec possesses the capability to generate the entire ranking list in a single forward process, and demands only a minimal set of pluggable parameters, which are trained for each dataset while keeping the entire LLM frozen. We substantiate the effectiveness, efficiency, and extensibility of our proposed E4SRec through comprehensive experiments conducted on four widely-used real-world datasets. The implementation code is accessible at https://github.com/HestiaSky/E4SRec/.
OpenSiteRec: An Open Dataset for Site Recommendation
Jul 03, 2023



As a representative information retrieval task, site recommendation, which aims at predicting the optimal sites for a brand or an institution to open new branches in an automatic data-driven way, is beneficial and crucial for brand development in modern business. However, there is no publicly available dataset so far and most existing approaches are limited to an extremely small scope of brands, which seriously hinders the research on site recommendation. Therefore, we collect, construct and release an open comprehensive dataset, namely OpenSiteRec, to facilitate and promote the research on site recommendation. Specifically, OpenSiteRec leverages a heterogeneous graph schema to represent various types of real-world entities and relations in four international metropolises. To evaluate the performance of the existing general methods on the site recommendation task, we conduct benchmarking experiments of several representative recommendation models on OpenSiteRec. Furthermore, we also highlight the potential application directions to demonstrate the wide applicability of OpenSiteRec. We believe that our OpenSiteRec dataset is significant and anticipated to encourage the development of advanced methods for site recommendation. OpenSiteRec is available online at https://OpenSiteRec.github.io/.
IMF: Interactive Multimodal Fusion Model for Link Prediction
Mar 20, 2023Link prediction aims to identify potential missing triples in knowledge graphs. To get better results, some recent studies have introduced multimodal information to link prediction. However, these methods utilize multimodal information separately and neglect the complicated interaction between different modalities. In this paper, we aim at better modeling the inter-modality information and thus introduce a novel Interactive Multimodal Fusion (IMF) model to integrate knowledge from different modalities. To this end, we propose a two-stage multimodal fusion framework to preserve modality-specific knowledge as well as take advantage of the complementarity between different modalities. Instead of directly projecting different modalities into a unified space, our multimodal fusion module limits the representations of different modalities independent while leverages bilinear pooling for fusion and incorporates contrastive learning as additional constraints. Furthermore, the decision fusion module delivers the learned weighted average over the predictions of all modalities to better incorporate the complementarity of different modalities. Our approach has been demonstrated to be effective through empirical evaluations on several real-world datasets. The implementation code is available online at https://github.com/HestiaSky/IMF-Pytorch.
Jointly Learning Knowledge Embedding and Neighborhood Consensus with Relational Knowledge Distillation for Entity Alignment
Jan 25, 2022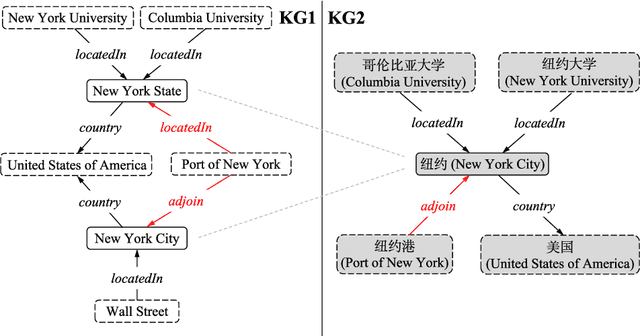
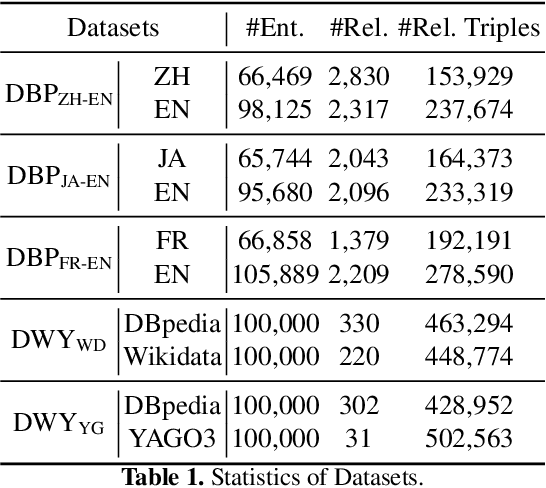
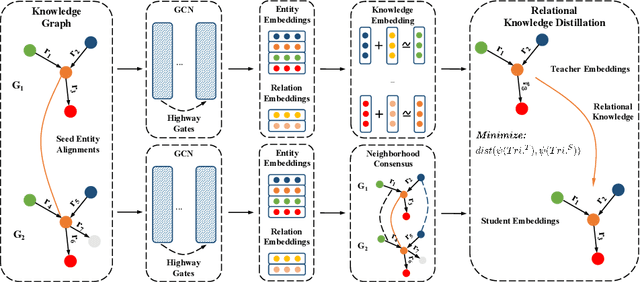
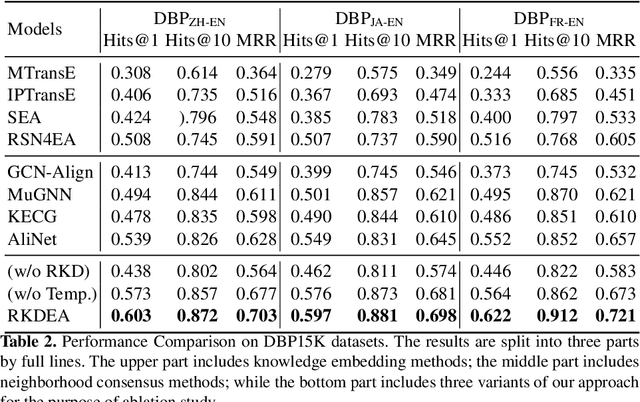
Entity alignment aims at integrating heterogeneous knowledge from different knowledge graphs. Recent studies employ embedding-based methods by first learning the representation of Knowledge Graphs and then performing entity alignment via measuring the similarity between entity embeddings. However, they failed to make good use of the relation semantic information due to the trade-off problem caused by the different objectives of learning knowledge embedding and neighborhood consensus. To address this problem, we propose Relational Knowledge Distillation for Entity Alignment (RKDEA), a Graph Convolutional Network (GCN) based model equipped with knowledge distillation for entity alignment. We adopt GCN-based models to learn the representation of entities by considering the graph structure and incorporating the relation semantic information into GCN via knowledge distillation. Then, we introduce a novel adaptive mechanism to transfer relational knowledge so as to jointly learn entity embedding and neighborhood consensus. Experimental results on several benchmarking datasets demonstrate the effectiveness of our proposed model.