 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYoutu-VL: Unleashing Visual Potential via Unified Vision-Language Supervision
Jan 27, 2026Despite the significant advancements represented by Vision-Language Models (VLMs), current architectures often exhibit limitations in retaining fine-grained visual information, leading to coarse-grained multimodal comprehension. We attribute this deficiency to a suboptimal training paradigm inherent in prevailing VLMs, which exhibits a text-dominant optimization bias by conceptualizing visual signals merely as passive conditional inputs rather than supervisory targets. To mitigate this, we introduce Youtu-VL, a framework leveraging the Vision-Language Unified Autoregressive Supervision (VLUAS) paradigm, which fundamentally shifts the optimization objective from ``vision-as-input'' to ``vision-as-target.'' By integrating visual tokens directly into the prediction stream, Youtu-VL applies unified autoregressive supervision to both visual details and linguistic content. Furthermore, we extend this paradigm to encompass vision-centric tasks, enabling a standard VLM to perform vision-centric tasks without task-specific additions. Extensive empirical evaluations demonstrate that Youtu-VL achieves competitive performance on both general multimodal tasks and vision-centric tasks, establishing a robust foundation for the development of comprehensive generalist visual agents.
TACO: Think-Answer Consistency for Optimized Long-Chain Reasoning and Efficient Data Learning via Reinforcement Learning in LVLMs
May 27, 2025DeepSeek R1 has significantly advanced complex reasoning for large language models (LLMs). While recent methods have attempted to replicate R1's reasoning capabilities in multimodal settings, they face limitations, including inconsistencies between reasoning and final answers, model instability and crashes during long-chain exploration, and low data learning efficiency. To address these challenges, we propose TACO, a novel reinforcement learning algorithm for visual reasoning. Building on Generalized Reinforcement Policy Optimization (GRPO), TACO introduces Think-Answer Consistency, which tightly couples reasoning with answer consistency to ensure answers are grounded in thoughtful reasoning. We also introduce the Rollback Resample Strategy, which adaptively removes problematic samples and reintroduces them to the sampler, enabling stable long-chain exploration and future learning opportunities. Additionally, TACO employs an adaptive learning schedule that focuses on moderate difficulty samples to optimize data efficiency. Furthermore, we propose the Test-Time-Resolution-Scaling scheme to address performance degradation due to varying resolutions during reasoning while balancing computational overhead. Extensive experiments on in-distribution and out-of-distribution benchmarks for REC and VQA tasks show that fine-tuning LVLMs leads to significant performance improvements.
Self-Correcting Decoding with Generative Feedback for Mitigating Hallucinations in Large Vision-Language Models
Feb 10, 2025While recent Large Vision-Language Models (LVLMs) have shown remarkable performance in multi-modal tasks, they are prone to generating hallucinatory text responses that do not align with the given visual input, which restricts their practical applicability in real-world scenarios. In this work, inspired by the observation that the text-to-image generation process is the inverse of image-conditioned response generation in LVLMs, we explore the potential of leveraging text-to-image generative models to assist in mitigating hallucinations in LVLMs. We discover that generative models can offer valuable self-feedback for mitigating hallucinations at both the response and token levels. Building on this insight, we introduce self-correcting Decoding with Generative Feedback (DeGF), a novel training-free algorithm that incorporates feedback from text-to-image generative models into the decoding process to effectively mitigate hallucinations in LVLMs. Specifically, DeGF generates an image from the initial response produced by LVLMs, which acts as an auxiliary visual reference and provides self-feedback to verify and correct the initial response through complementary or contrastive decoding. Extensive experimental results validate the effectiveness of our approach in mitigating diverse types of hallucinations, consistently surpassing state-of-the-art methods across six benchmarks. Code is available at https://github.com/zhangce01/DeGF.
CATCH: Complementary Adaptive Token-level Contrastive Decoding to Mitigate Hallucinations in LVLMs
Nov 19, 2024


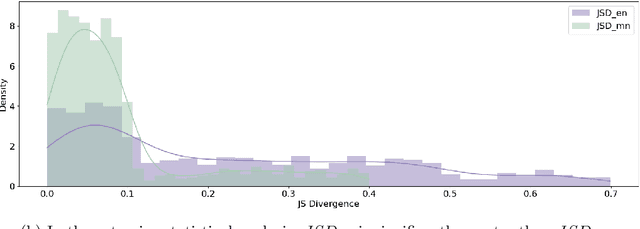
Large Vision-Language Model (LVLM) systems have demonstrated impressive vision-language reasoning capabilities but suffer from pervasive and severe hallucination issues, posing significant risks in critical domains such as healthcare and autonomous systems. Despite previous efforts to mitigate hallucinations, a persistent issue remains: visual defect from vision-language misalignment, creating a bottleneck in visual processing capacity. To address this challenge, we develop Complementary Adaptive Token-level Contrastive Decoding to Mitigate Hallucinations in LVLMs (CATCH), based on the Information Bottleneck theory. CATCH introduces Complementary Visual Decoupling (CVD) for visual information separation, Non-Visual Screening (NVS) for hallucination detection, and Adaptive Token-level Contrastive Decoding (ATCD) for hallucination mitigation. CATCH addresses issues related to visual defects that cause diminished fine-grained feature perception and cumulative hallucinations in open-ended scenarios. It is applicable to various visual question-answering tasks without requiring any specific data or prior knowledge, and generalizes robustly to new tasks without additional training, opening new possibilities for advancing LVLM in various challenging applications.
Learning Visual Conditioning Tokens to Correct Domain Shift for Fully Test-time Adaptation
Jun 27, 2024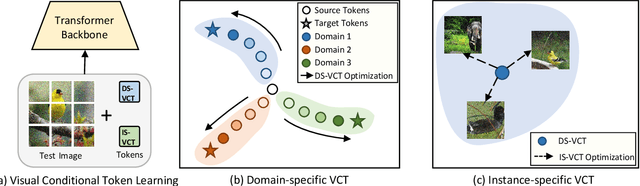
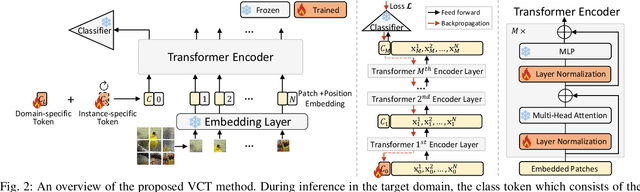
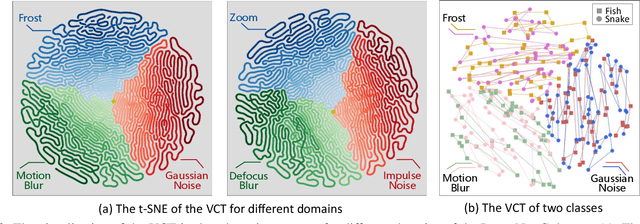
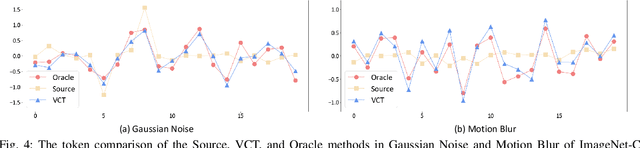
Fully test-time adaptation aims to adapt the network model based on sequential analysis of input samples during the inference stage to address the cross-domain performance degradation problem of deep neural networks. This work is based on the following interesting finding: in transformer-based image classification, the class token at the first transformer encoder layer can be learned to capture the domain-specific characteristics of target samples during test-time adaptation. This learned token, when combined with input image patch embeddings, is able to gradually remove the domain-specific information from the feature representations of input samples during the transformer encoding process, thereby significantly improving the test-time adaptation performance of the source model across different domains. We refer to this class token as visual conditioning token (VCT). To successfully learn the VCT, we propose a bi-level learning approach to capture the long-term variations of domain-specific characteristics while accommodating local variations of instance-specific characteristics. Experimental results on the benchmark datasets demonstrate that our proposed bi-level visual conditioning token learning method is able to achieve significantly improved test-time adaptation performance by up to 1.9%.
Self-Correctable and Adaptable Inference for Generalizable Human Pose Estimation
Mar 25, 2023A central challenge in human pose estimation, as well as in many other machine learning and prediction tasks, is the generalization problem. The learned network does not have the capability to characterize the prediction error, generate feedback information from the test sample, and correct the prediction error on the fly for each individual test sample, which results in degraded performance in generalization. In this work, we introduce a self-correctable and adaptable inference (SCAI) method to address the generalization challenge of network prediction and use human pose estimation as an example to demonstrate its effectiveness and performance. We learn a correction network to correct the prediction result conditioned by a fitness feedback error. This feedback error is generated by a learned fitness feedback network which maps the prediction result to the original input domain and compares it against the original input. Interestingly, we find that this self-referential feedback error is highly correlated with the actual prediction error. This strong correlation suggests that we can use this error as feedback to guide the correction process. It can be also used as a loss function to quickly adapt and optimize the correction network during the inference process. Our extensive experimental results on human pose estimation demonstrate that the proposed SCAI method is able to significantly improve the generalization capability and performance of human pose estimation.
Self-Constrained Inference Optimization on Structural Groups for Human Pose Estimation
Jul 06, 2022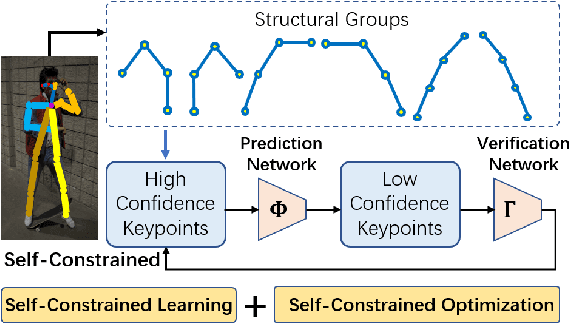
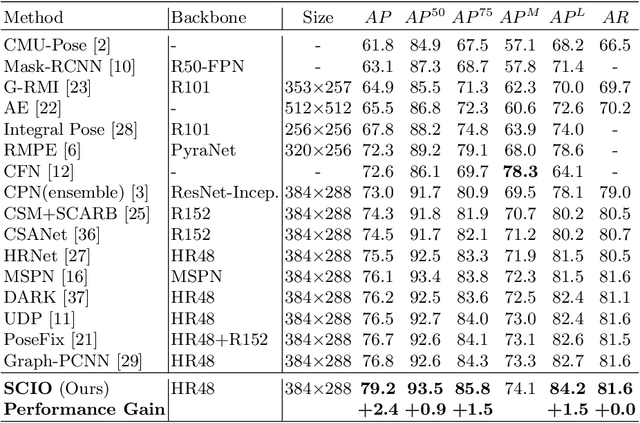
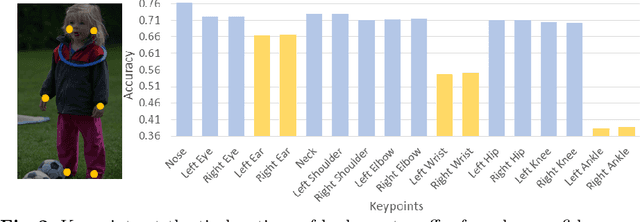

We observe that human poses exhibit strong group-wise structural correlation and spatial coupling between keypoints due to the biological constraints of different body parts. This group-wise structural correlation can be explored to improve the accuracy and robustness of human pose estimation. In this work, we develop a self-constrained prediction-verification network to characterize and learn the structural correlation between keypoints during training. During the inference stage, the feedback information from the verification network allows us to perform further optimization of pose prediction, which significantly improves the performance of human pose estimation. Specifically, we partition the keypoints into groups according to the biological structure of human body. Within each group, the keypoints are further partitioned into two subsets, high-confidence base keypoints and low-confidence terminal keypoints. We develop a self-constrained prediction-verification network to perform forward and backward predictions between these keypoint subsets. One fundamental challenge in pose estimation, as well as in generic prediction tasks, is that there is no mechanism for us to verify if the obtained pose estimation or prediction results are accurate or not, since the ground truth is not available. Once successfully learned, the verification network serves as an accuracy verification module for the forward pose prediction. During the inference stage, it can be used to guide the local optimization of the pose estimation results of low-confidence keypoints with the self-constrained loss on high-confidence keypoints as the objective function. Our extensive experimental results on benchmark MS COCO and CrowdPose datasets demonstrate that the proposed method can significantly improve the pose estimation results.