 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Bias Alignment for High-Fidelity Diffusion Inversion in Real-World Image Reconstruction and Manipulation
Mar 25, 2026Recent research has shown that text-to-image diffusion models are capable of generating high-quality images guided by text prompts. But can they be used to generate or approximate real-world images from the seed noise? This is known as the diffusion inversion problem, which serves as a fundamental building block for bridging diffusion models and real-world scenarios. However, existing diffusion inversion methods often suffer from low reconstruction quality or weak robustness. Two major challenges need to be carefully addressed: (1) the misalignment between the inversion and generation trajectories during the diffusion process, and (2) the mismatch between the diffusion inversion process and the VQ autoencoder (VQAE) reconstruction. To address these challenges, we introduce a latent bias vector at each inversion step, which is learned to reduce the misalignment between inversion and generation trajectories. We refer to this strategy as Latent Bias Optimization (LBO). Furthermore, we perform an approximate joint optimization of the diffusion inversion and VQAE reconstruction processes by learning to adjust the image latent representation, which serves as the connecting interface between them. We refer to this technique as Image Latent Boosting (ILB). Extensive experimental results demonstrate that the proposed method significantly improves the image reconstruction quality of the diffusion model, as well as the performance of downstream tasks, including image editing and rare concept generation.
Progressive Conditioned Scale-Shift Recalibration of Self-Attention for Online Test-time Adaptation
Dec 14, 2025
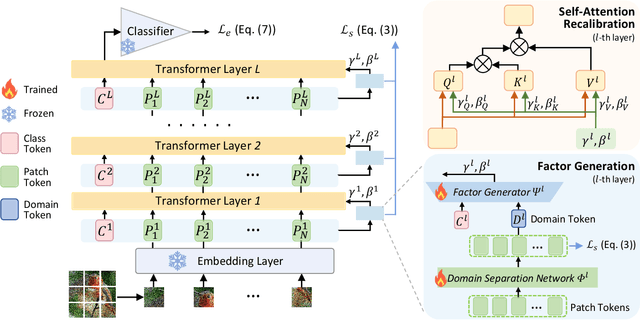


Online test-time adaptation aims to dynamically adjust a network model in real-time based on sequential input samples during the inference stage. In this work, we find that, when applying a transformer network model to a new target domain, the Query, Key, and Value features of its self-attention module often change significantly from those in the source domain, leading to substantial performance degradation of the transformer model. To address this important issue, we propose to develop a new approach to progressively recalibrate the self-attention at each layer using a local linear transform parameterized by conditioned scale and shift factors. We consider the online model adaptation from the source domain to the target domain as a progressive domain shift separation process. At each transformer network layer, we learn a Domain Separation Network to extract the domain shift feature, which is used to predict the scale and shift parameters for self-attention recalibration using a Factor Generator Network. These two lightweight networks are adapted online during inference. Experimental results on benchmark datasets demonstrate that the proposed progressive conditioned scale-shift recalibration (PCSR) method is able to significantly improve the online test-time domain adaptation performance by a large margin of up to 3.9\% in classification accuracy on the ImageNet-C dataset.
Training-Free Dual Hyperbolic Adapters for Better Cross-Modal Reasoning
Dec 09, 2025Recent research in Vision-Language Models (VLMs) has significantly advanced our capabilities in cross-modal reasoning. However, existing methods suffer from performance degradation with domain changes or require substantial computational resources for fine-tuning in new domains. To address this issue, we develop a new adaptation method for large vision-language models, called \textit{Training-free Dual Hyperbolic Adapters} (T-DHA). We characterize the vision-language relationship between semantic concepts, which typically has a hierarchical tree structure, in the hyperbolic space instead of the traditional Euclidean space. Hyperbolic spaces exhibit exponential volume growth with radius, unlike the polynomial growth in Euclidean space. We find that this unique property is particularly effective for embedding hierarchical data structures using the Poincaré ball model, achieving significantly improved representation and discrimination power. Coupled with negative learning, it provides more accurate and robust classifications with fewer feature dimensions. Our extensive experimental results on various datasets demonstrate that the T-DHA method significantly outperforms existing state-of-the-art methods in few-shot image recognition and domain generalization tasks.
Open-World Test-Time Adaptation with Hierarchical Feature Aggregation and Attention Affine
Nov 16, 2025Test-time adaptation (TTA) refers to adjusting the model during the testing phase to cope with changes in sample distribution and enhance the model's adaptability to new environments. In real-world scenarios, models often encounter samples from unseen (out-of-distribution, OOD) categories. Misclassifying these as known (in-distribution, ID) classes not only degrades predictive accuracy but can also impair the adaptation process, leading to further errors on subsequent ID samples. Many existing TTA methods suffer substantial performance drops under such conditions. To address this challenge, we propose a Hierarchical Ladder Network that extracts OOD features from class tokens aggregated across all Transformer layers. OOD detection performance is enhanced by combining the original model prediction with the output of the Hierarchical Ladder Network (HLN) via weighted probability fusion. To improve robustness under domain shift, we further introduce an Attention Affine Network (AAN) that adaptively refines the self-attention mechanism conditioned on the token information to better adapt to domain drift, thereby improving the classification performance of the model on datasets with domain shift. Additionally, a weighted entropy mechanism is employed to dynamically suppress the influence of low-confidence samples during adaptation. Experimental results on benchmark datasets show that our method significantly improves the performance on the most widely used classification datasets.
Domain-Conditioned Transformer for Fully Test-time Adaptation
Oct 14, 2024Fully test-time adaptation aims to adapt a network model online based on sequential analysis of input samples during the inference stage. We observe that, when applying a transformer network model into a new domain, the self-attention profiles of image samples in the target domain deviate significantly from those in the source domain, which results in large performance degradation during domain changes. To address this important issue, we propose a new structure for the self-attention modules in the transformer. Specifically, we incorporate three domain-conditioning vectors, called domain conditioners, into the query, key, and value components of the self-attention module. We learn a network to generate these three domain conditioners from the class token at each transformer network layer. We find that, during fully online test-time adaptation, these domain conditioners at each transform network layer are able to gradually remove the impact of domain shift and largely recover the original self-attention profile. Our extensive experimental results demonstrate that the proposed domain-conditioned transformer significantly improves the online fully test-time domain adaptation performance and outperforms existing state-of-the-art methods by large margins.
Window-based Channel Attention for Wavelet-enhanced Learned Image Compression
Sep 21, 2024
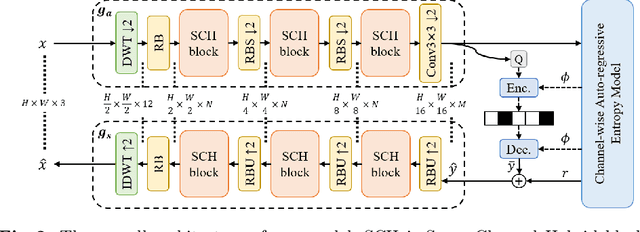
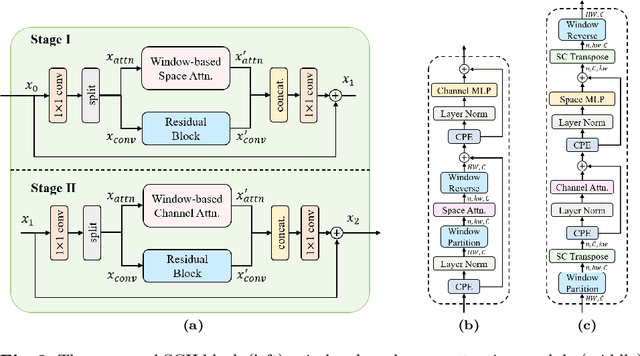
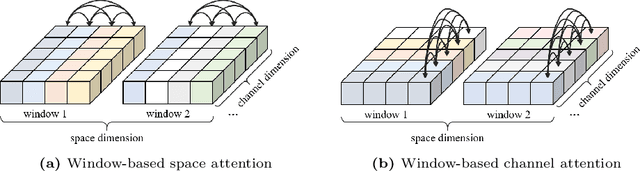
Learned Image Compression (LIC) models have achieved superior rate-distortion performance than traditional codecs. Existing LIC models use CNN, Transformer, or Mixed CNN-Transformer as basic blocks. However, limited by the shifted window attention, Swin-Transformer-based LIC exhibits a restricted growth of receptive fields, affecting the ability to model large objects in the image. To address this issue, we incorporate window partition into channel attention for the first time to obtain large receptive fields and capture more global information. Since channel attention hinders local information learning, it is important to extend existing attention mechanisms in Transformer codecs to the space-channel attention to establish multiple receptive fields, being able to capture global correlations with large receptive fields while maintaining detailed characterization of local correlations with small receptive fields. We also incorporate the discrete wavelet transform into our Spatial-Channel Hybrid (SCH) framework for efficient frequency-dependent down-sampling and further enlarging receptive fields. Experiment results demonstrate that our method achieves state-of-the-art performances, reducing BD-rate by 18.54%, 23.98%, 22.33%, and 24.71% on four standard datasets compared to VTM-23.1.
Dual-Path Adversarial Lifting for Domain Shift Correction in Online Test-time Adaptation
Aug 26, 2024

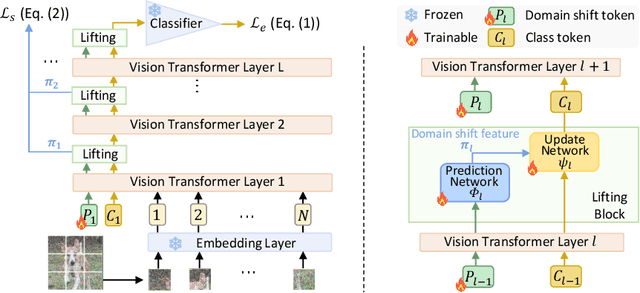
Transformer-based methods have achieved remarkable success in various machine learning tasks. How to design efficient test-time adaptation methods for transformer models becomes an important research task. In this work, motivated by the dual-subband wavelet lifting scheme developed in multi-scale signal processing which is able to efficiently separate the input signals into principal components and noise components, we introduce a dual-path token lifting for domain shift correction in test time adaptation. Specifically, we introduce an extra token, referred to as \textit{domain shift token}, at each layer of the transformer network. We then perform dual-path lifting with interleaved token prediction and update between the path of domain shift tokens and the path of class tokens at all network layers. The prediction and update networks are learned in an adversarial manner. Specifically, the task of the prediction network is to learn the residual noise of domain shift which should be largely invariant across all classes and all samples in the target domain. In other words, the predicted domain shift noise should be indistinguishable between all sample classes. On the other hand, the task of the update network is to update the class tokens by removing the domain shift from the input image samples so that input samples become more discriminative between different classes in the feature space. To effectively learn the prediction and update networks with two adversarial tasks, both theoretically and practically, we demonstrate that it is necessary to use smooth optimization for the update network but non-smooth optimization for the prediction network. Experimental results on the benchmark datasets demonstrate that our proposed method significantly improves the online fully test-time domain adaptation performance. Code is available at \url{https://github.com/yushuntang/DPAL}.
Learning Visual Conditioning Tokens to Correct Domain Shift for Fully Test-time Adaptation
Jun 27, 2024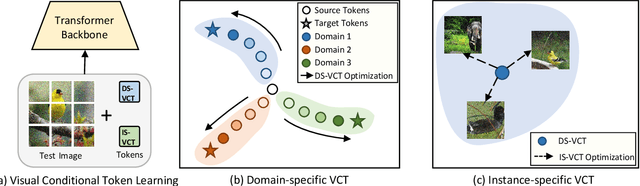
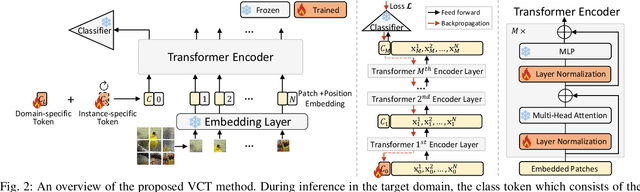
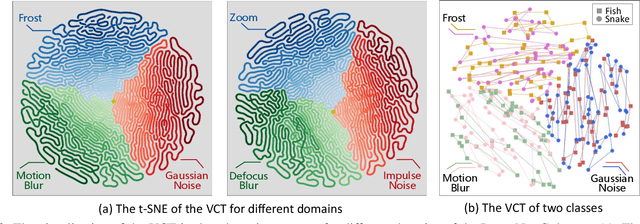
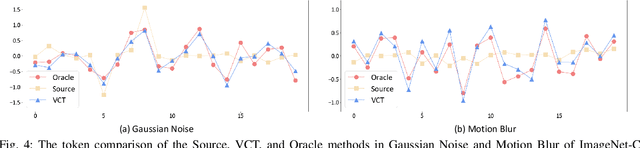
Fully test-time adaptation aims to adapt the network model based on sequential analysis of input samples during the inference stage to address the cross-domain performance degradation problem of deep neural networks. This work is based on the following interesting finding: in transformer-based image classification, the class token at the first transformer encoder layer can be learned to capture the domain-specific characteristics of target samples during test-time adaptation. This learned token, when combined with input image patch embeddings, is able to gradually remove the domain-specific information from the feature representations of input samples during the transformer encoding process, thereby significantly improving the test-time adaptation performance of the source model across different domains. We refer to this class token as visual conditioning token (VCT). To successfully learn the VCT, we propose a bi-level learning approach to capture the long-term variations of domain-specific characteristics while accommodating local variations of instance-specific characteristics. Experimental results on the benchmark datasets demonstrate that our proposed bi-level visual conditioning token learning method is able to achieve significantly improved test-time adaptation performance by up to 1.9%.
Concept-Guided Prompt Learning for Generalization in Vision-Language Models
Jan 15, 2024Contrastive Language-Image Pretraining (CLIP) model has exhibited remarkable efficacy in establishing cross-modal connections between texts and images, yielding impressive performance across a broad spectrum of downstream applications through fine-tuning. However, for generalization tasks, the current fine-tuning methods for CLIP, such as CoOp and CoCoOp, demonstrate relatively low performance on some fine-grained datasets. We recognize the underlying reason is that these previous methods only projected global features into the prompt, neglecting the various visual concepts, such as colors, shapes, and sizes, which are naturally transferable across domains and play a crucial role in generalization tasks. To address this issue, in this work, we propose Concept-Guided Prompt Learning (CPL) for vision-language models. Specifically, we leverage the well-learned knowledge of CLIP to create a visual concept cache to enable concept-guided prompting. In order to refine the text features, we further develop a projector that transforms multi-level visual features into text features. We observe that this concept-guided prompt learning approach is able to achieve enhanced consistency between visual and linguistic modalities. Extensive experimental results demonstrate that our CPL method significantly improves generalization capabilities compared to the current state-of-the-art methods.
BDC-Adapter: Brownian Distance Covariance for Better Vision-Language Reasoning
Sep 03, 2023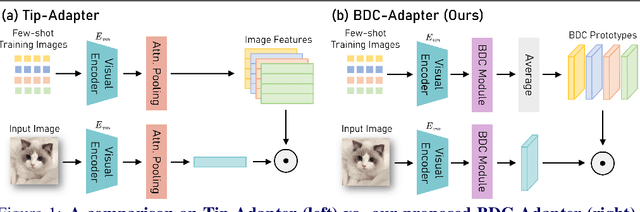
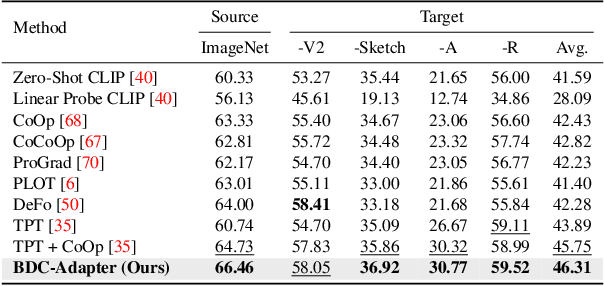
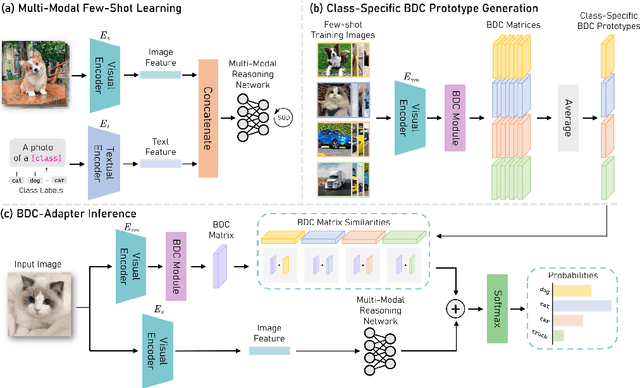

Large-scale pre-trained Vision-Language Models (VLMs), such as CLIP and ALIGN, have introduced a new paradigm for learning transferable visual representations. Recently, there has been a surge of interest among researchers in developing lightweight fine-tuning techniques to adapt these models to downstream visual tasks. We recognize that current state-of-the-art fine-tuning methods, such as Tip-Adapter, simply consider the covariance between the query image feature and features of support few-shot training samples, which only captures linear relations and potentially instigates a deceptive perception of independence. To address this issue, in this work, we innovatively introduce Brownian Distance Covariance (BDC) to the field of vision-language reasoning. The BDC metric can model all possible relations, providing a robust metric for measuring feature dependence. Based on this, we present a novel method called BDC-Adapter, which integrates BDC prototype similarity reasoning and multi-modal reasoning network prediction to perform classification tasks. Our extensive experimental results show that the proposed BDC-Adapter can freely handle non-linear relations and fully characterize independence, outperforming the current state-of-the-art methods by large margins.