 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOsmosis Distillation: Model Hijacking with the Fewest Samples
Mar 05, 2026Transfer learning is devised to leverage knowledge from pre-trained models to solve new tasks with limited data and computational resources. Meanwhile, dataset distillation has emerged to synthesize a compact dataset that preserves critical information from the original large dataset. Therefore, a combination of transfer learning and dataset distillation offers promising performance in evaluations. However, a non-negligible security threat remains undiscovered in transfer learning using synthetic datasets generated by dataset distillation methods, where an adversary can perform a model hijacking attack with only a few poisoned samples in the synthetic dataset. To reveal this threat, we propose Osmosis Distillation (OD) attack, a novel model hijacking strategy that targets deep learning models using the fewest samples. Comprehensive evaluations on various datasets demonstrate that the OD attack attains high attack success rates in hidden tasks while preserving high model utility in original tasks. Furthermore, the distilled osmosis set enables model hijacking across diverse model architectures, allowing model hijacking in transfer learning with considerable attack performance and model utility. We argue that awareness of using third-party synthetic datasets in transfer learning must be raised.
Hide&Seek: Remove Image Watermarks with Negligible Cost via Pixel-wise Reconstruction
Mar 01, 2026Watermarking has emerged as a key defense against the misuse of machine-generated images (MGIs). Yet the robustness of these protections remains underexplored. To reveal the limits of SOTA proactive image watermarking defenses, we propose HIDE&SEEK (HS), a suite of versatile and cost-effective attacks that reliably remove embedded watermarks while preserving high visual fidelity.
Forgetting Similar Samples: Can Machine Unlearning Do it Better?
Jan 11, 2026Machine unlearning, a process enabling pre-trained models to remove the influence of specific training samples, has attracted significant attention in recent years. Although extensive research has focused on developing efficient machine unlearning strategies, we argue that these methods mainly aim at removing samples rather than removing samples' influence on the model, thus overlooking the fundamental definition of machine unlearning. In this paper, we first conduct a comprehensive study to evaluate the effectiveness of existing unlearning schemes when the training dataset includes many samples similar to those targeted for unlearning. Specifically, we evaluate: Do existing unlearning methods truly adhere to the original definition of machine unlearning and effectively eliminate all influence of target samples when similar samples are present in the training dataset? Our extensive experiments, conducted on four carefully constructed datasets with thorough analysis, reveal a notable gap between the expected and actual performance of most existing unlearning methods for image and language models, even for the retraining-from-scratch baseline. Additionally, we also explore potential solutions to enhance current unlearning approaches.
PLATONT: Learning a Platonic Representation for Unified Network Tomography
Nov 19, 2025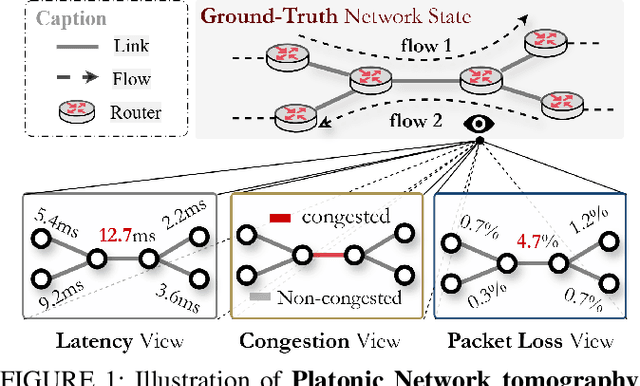
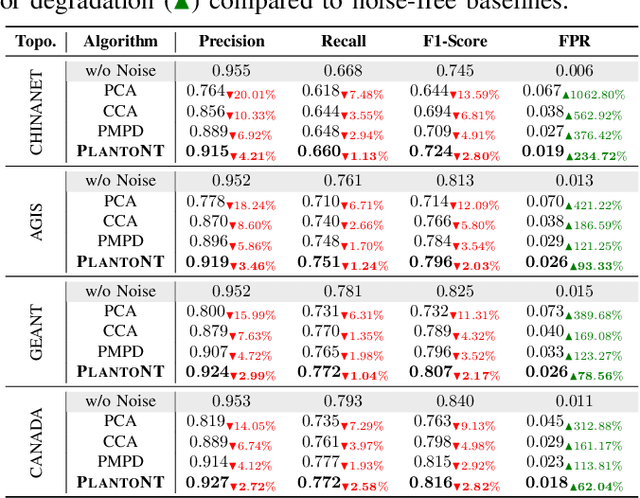
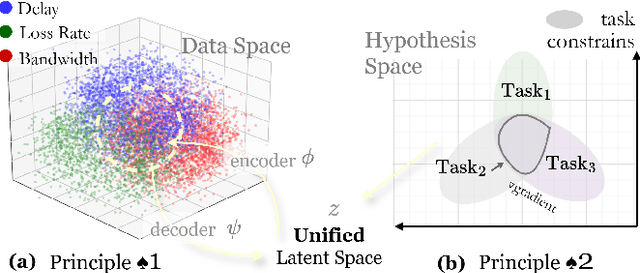
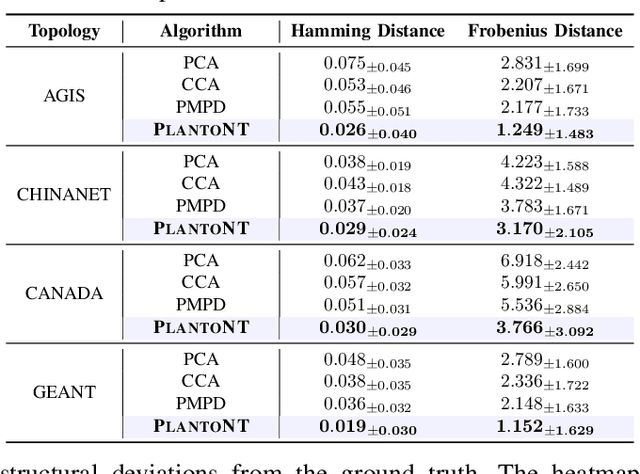
Network tomography aims to infer hidden network states, such as link performance, traffic load, and topology, from external observations. Most existing methods solve these problems separately and depend on limited task-specific signals, which limits generalization and interpretability. We present PLATONT, a unified framework that models different network indicators (e.g., delay, loss, bandwidth) as projections of a shared latent network state. Guided by the Platonic Representation Hypothesis, PLATONT learns this latent state through multimodal alignment and contrastive learning. By training multiple tomography tasks within a shared latent space, it builds compact and structured representations that improve cross-task generalization. Experiments on synthetic and real-world datasets show that PLATONT consistently outperforms existing methods in link estimation, topology inference, and traffic prediction, achieving higher accuracy and stronger robustness under varying network conditions.
Can Large Language Models Logically Predict Myocardial Infarction? Evaluation based on UK Biobank Cohort
Sep 22, 2024
Background: Large language models (LLMs) have seen extraordinary advances with applications in clinical decision support. However, high-quality evidence is urgently needed on the potential and limitation of LLMs in providing accurate clinical decisions based on real-world medical data. Objective: To evaluate quantitatively whether universal state-of-the-art LLMs (ChatGPT and GPT-4) can predict the incidence risk of myocardial infarction (MI) with logical inference, and to further make comparison between various models to assess the performance of LLMs comprehensively. Methods: In this retrospective cohort study, 482,310 participants recruited from 2006 to 2010 were initially included in UK Biobank database and later on resampled into a final cohort of 690 participants. For each participant, tabular data of the risk factors of MI were transformed into standardized textual descriptions for ChatGPT recognition. Responses were generated by asking ChatGPT to select a score ranging from 0 to 10 representing the risk. Chain of Thought (CoT) questioning was used to evaluate whether LLMs make prediction logically. The predictive performance of ChatGPT was compared with published medical indices, traditional machine learning models and other large language models. Conclusions: Current LLMs are not ready to be applied in clinical medicine fields. Future medical LLMs are suggested to be expert in medical domain knowledge to understand both natural languages and quantified medical data, and further make logical inferences.
Window-based Channel Attention for Wavelet-enhanced Learned Image Compression
Sep 21, 2024
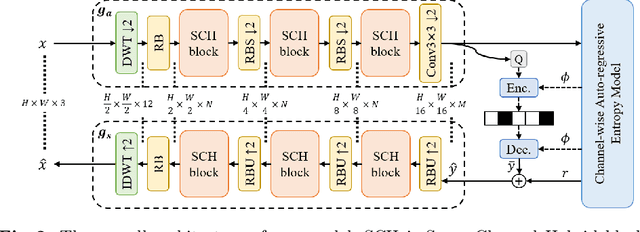
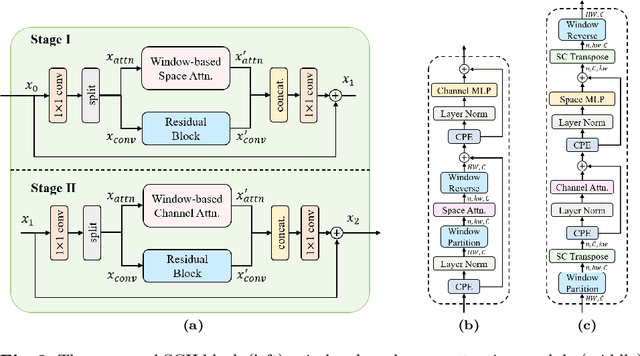
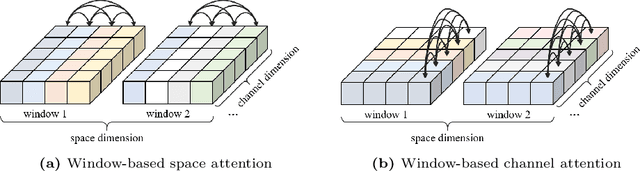
Learned Image Compression (LIC) models have achieved superior rate-distortion performance than traditional codecs. Existing LIC models use CNN, Transformer, or Mixed CNN-Transformer as basic blocks. However, limited by the shifted window attention, Swin-Transformer-based LIC exhibits a restricted growth of receptive fields, affecting the ability to model large objects in the image. To address this issue, we incorporate window partition into channel attention for the first time to obtain large receptive fields and capture more global information. Since channel attention hinders local information learning, it is important to extend existing attention mechanisms in Transformer codecs to the space-channel attention to establish multiple receptive fields, being able to capture global correlations with large receptive fields while maintaining detailed characterization of local correlations with small receptive fields. We also incorporate the discrete wavelet transform into our Spatial-Channel Hybrid (SCH) framework for efficient frequency-dependent down-sampling and further enlarging receptive fields. Experiment results demonstrate that our method achieves state-of-the-art performances, reducing BD-rate by 18.54%, 23.98%, 22.33%, and 24.71% on four standard datasets compared to VTM-23.1.
Update Selective Parameters: Federated Machine Unlearning Based on Model Explanation
Jun 18, 2024



Federated learning is a promising privacy-preserving paradigm for distributed machine learning. In this context, there is sometimes a need for a specialized process called machine unlearning, which is required when the effect of some specific training samples needs to be removed from a learning model due to privacy, security, usability, and/or legislative factors. However, problems arise when current centralized unlearning methods are applied to existing federated learning, in which the server aims to remove all information about a class from the global model. Centralized unlearning usually focuses on simple models or is premised on the ability to access all training data at a central node. However, training data cannot be accessed on the server under the federated learning paradigm, conflicting with the requirements of the centralized unlearning process. Additionally, there are high computation and communication costs associated with accessing clients' data, especially in scenarios involving numerous clients or complex global models. To address these concerns, we propose a more effective and efficient federated unlearning scheme based on the concept of model explanation. Model explanation involves understanding deep networks and individual channel importance, so that this understanding can be used to determine which model channels are critical for classes that need to be unlearned. We select the most influential channels within an already-trained model for the data that need to be unlearned and fine-tune only influential channels to remove the contribution made by those data. In this way, we can simultaneously avoid huge consumption costs and ensure that the unlearned model maintains good performance. Experiments with different training models on various datasets demonstrate the effectiveness of the proposed approach.
Towards Efficient Target-Level Machine Unlearning Based on Essential Graph
Jun 16, 2024



Machine unlearning is an emerging technology that has come to attract widespread attention. A number of factors, including regulations and laws, privacy, and usability concerns, have resulted in this need to allow a trained model to forget some of its training data. Existing studies of machine unlearning mainly focus on unlearning requests that forget a cluster of instances or all instances from one class. While these approaches are effective in removing instances, they do not scale to scenarios where partial targets within an instance need to be forgotten. For example, one would like to only unlearn a person from all instances that simultaneously contain the person and other targets. Directly migrating instance-level unlearning to target-level unlearning will reduce the performance of the model after the unlearning process, or fail to erase information completely. To address these concerns, we have proposed a more effective and efficient unlearning scheme that focuses on removing partial targets from the model, which we name "target unlearning". Specifically, we first construct an essential graph data structure to describe the relationships between all important parameters that are selected based on the model explanation method. After that, we simultaneously filter parameters that are also important for the remaining targets and use the pruning-based unlearning method, which is a simple but effective solution to remove information about the target that needs to be forgotten. Experiments with different training models on various datasets demonstrate the effectiveness of the proposed approach.
Class Machine Unlearning for Complex Data via Concepts Inference and Data Poisoning
May 24, 2024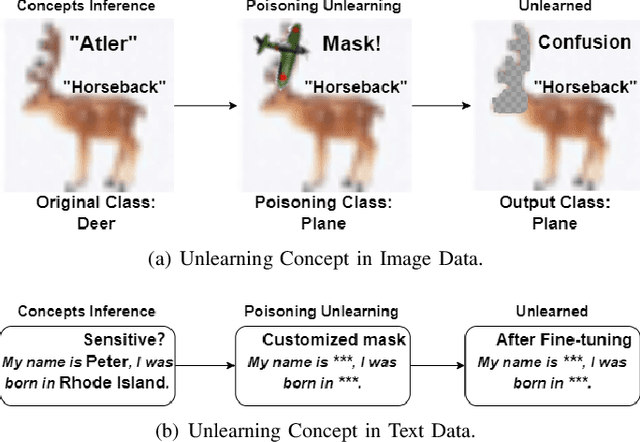
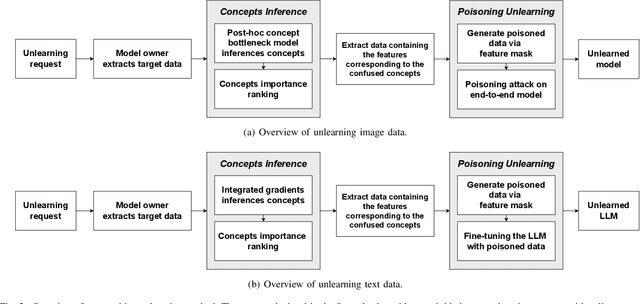


In current AI era, users may request AI companies to delete their data from the training dataset due to the privacy concerns. As a model owner, retraining a model will consume significant computational resources. Therefore, machine unlearning is a new emerged technology to allow model owner to delete requested training data or a class with little affecting on the model performance. However, for large-scaling complex data, such as image or text data, unlearning a class from a model leads to a inferior performance due to the difficulty to identify the link between classes and model. An inaccurate class deleting may lead to over or under unlearning. In this paper, to accurately defining the unlearning class of complex data, we apply the definition of Concept, rather than an image feature or a token of text data, to represent the semantic information of unlearning class. This new representation can cut the link between the model and the class, leading to a complete erasing of the impact of a class. To analyze the impact of the concept of complex data, we adopt a Post-hoc Concept Bottleneck Model, and Integrated Gradients to precisely identify concepts across different classes. Next, we take advantage of data poisoning with random and targeted labels to propose unlearning methods. We test our methods on both image classification models and large language models (LLMs). The results consistently show that the proposed methods can accurately erase targeted information from models and can largely maintain the performance of the models.
Machine Unlearning: A Survey
Jun 06, 2023



Machine learning has attracted widespread attention and evolved into an enabling technology for a wide range of highly successful applications, such as intelligent computer vision, speech recognition, medical diagnosis, and more. Yet a special need has arisen where, due to privacy, usability, and/or the right to be forgotten, information about some specific samples needs to be removed from a model, called machine unlearning. This emerging technology has drawn significant interest from both academics and industry due to its innovation and practicality. At the same time, this ambitious problem has led to numerous research efforts aimed at confronting its challenges. To the best of our knowledge, no study has analyzed this complex topic or compared the feasibility of existing unlearning solutions in different kinds of scenarios. Accordingly, with this survey, we aim to capture the key concepts of unlearning techniques. The existing solutions are classified and summarized based on their characteristics within an up-to-date and comprehensive review of each category's advantages and limitations. The survey concludes by highlighting some of the outstanding issues with unlearning techniques, along with some feasible directions for new research opportunities.