 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStarter-Iterator Neural Operator: A Unified Architecture for High-Fidelity Forward and Inverse PDE Problems
Jun 16, 2026Operator learning is an emerging interdisciplinary field that integrates machine learning with scientific computing. By mapping infinite-dimensional function spaces, this approach provides an efficient surrogate modeling framework for high-dimensional partial differential equations (PDEs). Compared to traditional numerical solvers, it achieves a superior trade-off between computational complexity and approximation accuracy, demonstrating significant advantages in many-query tasks such as real-time prediction and parameter sweeps. Given the stringent accuracy requirements of both forward simulation and inverse inference, as well as the precision bottlenecks of existing operator learning methods in handling complex boundaries or long-term evolution, we propose the Starter-Iterator Neural Operator (SINO). Our framework reinterprets the initialization strategies and iterative formats of traditional iterative methods through neural networks, establishing an efficient approach for spectral-spatiotemporal collaborative modeling. Specifically, the frequency-domain initialization module captures globally stable low-frequency features, while the time-domain learning module focuses on optimizing local solution residuals, thereby effectively overcoming the inherent limitations of conventional single-domain modeling approaches. Extensive experiments on typical dynamical systems such as the Navier-Stokes equations and acoustic wave equations, as well as practical applications including super-resolution imaging and weather forecasting, demonstrate that SINO achieves outstanding performance in numerical accuracy, generalization capability, and robustness.
Total Normal Curvature Regularization and its Minimization for Surface and Image Smoothing
Dec 25, 2025We introduce a novel formulation for curvature regularization by penalizing normal curvatures from multiple directions. This total normal curvature regularization is capable of producing solutions with sharp edges and precise isotropic properties. To tackle the resulting high-order nonlinear optimization problem, we reformulate it as the task of finding the steady-state solution of a time-dependent partial differential equation (PDE) system. Time discretization is achieved through operator splitting, where each subproblem at the fractional steps either has a closed-form solution or can be efficiently solved using advanced algorithms. Our method circumvents the need for complex parameter tuning and demonstrates robustness to parameter choices. The efficiency and effectiveness of our approach have been rigorously validated in the context of surface and image smoothing problems.
Total Curvature Regularization and its_Minimization for Surface and Image Smoothing
Dec 22, 2025We introduce a novel formulation for curvature regularization by penalizing normal curvatures from multiple directions. This total normal curvature regularization is capable of producing solutions with sharp edges and precise isotropic properties. To tackle the resulting high-order nonlinear optimization problem, we reformulate it as the task of finding the steady-state solution of a time-dependent partial differential equation (PDE) system. Time discretization is achieved through operator splitting, where each subproblem at the fractional steps either has a closed-form solution or can be efficiently solved using advanced algorithms. Our method circumvents the need for complex parameter tuning and demonstrates robustness to parameter choices. The efficiency and effectiveness of our approach have been rigorously validated in the context of surface and image smoothing problems.
Contour Field based Elliptical Shape Prior for the Segment Anything Model
Apr 17, 2025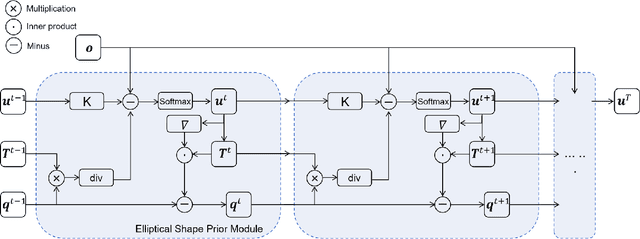
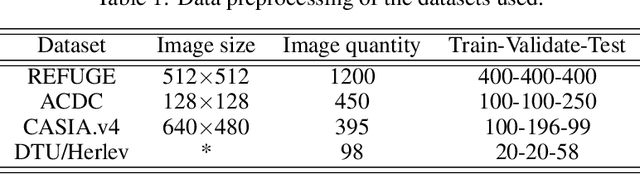

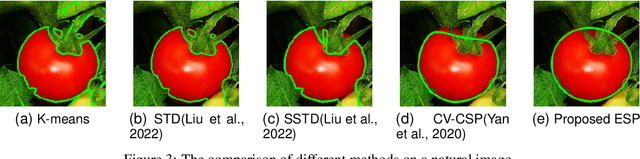
The elliptical shape prior information plays a vital role in improving the accuracy of image segmentation for specific tasks in medical and natural images. Existing deep learning-based segmentation methods, including the Segment Anything Model (SAM), often struggle to produce segmentation results with elliptical shapes efficiently. This paper proposes a new approach to integrate the prior of elliptical shapes into the deep learning-based SAM image segmentation techniques using variational methods. The proposed method establishes a parameterized elliptical contour field, which constrains the segmentation results to align with predefined elliptical contours. Utilizing the dual algorithm, the model seamlessly integrates image features with elliptical priors and spatial regularization priors, thereby greatly enhancing segmentation accuracy. By decomposing SAM into four mathematical sub-problems, we integrate the variational ellipse prior to design a new SAM network structure, ensuring that the segmentation output of SAM consists of elliptical regions. Experimental results on some specific image datasets demonstrate an improvement over the original SAM.
LUIEO: A Lightweight Model for Integrating Underwater Image Enhancement and Object Detection
Dec 01, 2024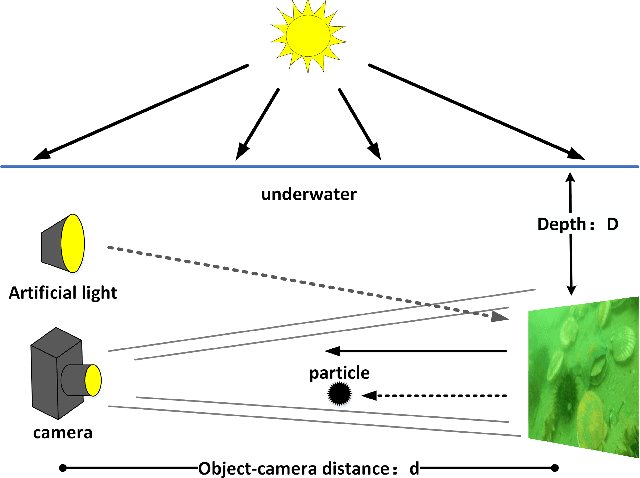
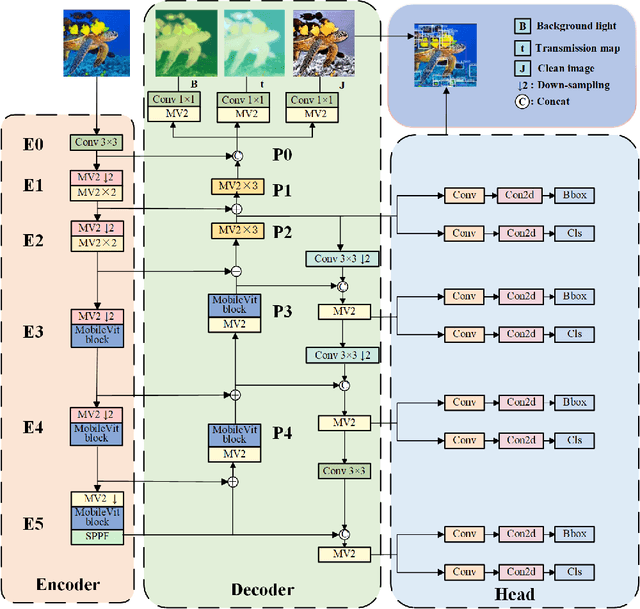
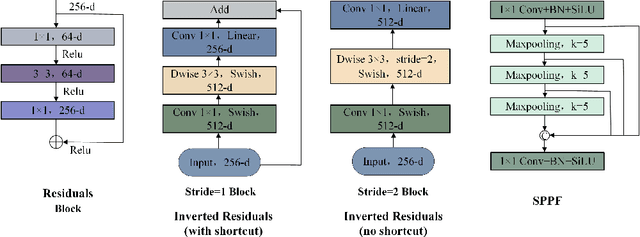
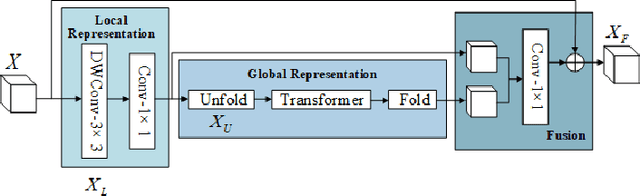
Underwater optical images inevitably suffer from various degradation factors such as blurring, low contrast, and color distortion, which hinder the accuracy of object detection tasks. Due to the lack of paired underwater/clean images, most research methods adopt a strategy of first enhancing and then detecting, resulting in a lack of feature communication between the two learning tasks. On the other hand, due to the contradiction between the diverse degradation factors of underwater images and the limited number of samples, existing underwater enhancement methods are difficult to effectively enhance degraded images of unknown water bodies, thereby limiting the improvement of object detection accuracy. Therefore, most underwater target detection results are still displayed on degraded images, making it difficult to visually judge the correctness of the detection results. To address the above issues, this paper proposes a multi-task learning method that simultaneously enhances underwater images and improves detection accuracy. Compared with single-task learning, the integrated model allows for the dynamic adjustment of information communication and sharing between different tasks. Due to the fact that real underwater images can only provide annotated object labels, this paper introduces physical constraints to ensure that object detection tasks do not interfere with image enhancement tasks. Therefore, this article introduces a physical module to decompose underwater images into clean images, background light, and transmission images and uses a physical model to calculate underwater images for self-supervision. Numerical experiments demonstrate that the proposed model achieves satisfactory results in visual performance, object detection accuracy, and detection efficiency compared to state-of-the-art comparative methods.
Can Large Language Models Logically Predict Myocardial Infarction? Evaluation based on UK Biobank Cohort
Sep 22, 2024
Background: Large language models (LLMs) have seen extraordinary advances with applications in clinical decision support. However, high-quality evidence is urgently needed on the potential and limitation of LLMs in providing accurate clinical decisions based on real-world medical data. Objective: To evaluate quantitatively whether universal state-of-the-art LLMs (ChatGPT and GPT-4) can predict the incidence risk of myocardial infarction (MI) with logical inference, and to further make comparison between various models to assess the performance of LLMs comprehensively. Methods: In this retrospective cohort study, 482,310 participants recruited from 2006 to 2010 were initially included in UK Biobank database and later on resampled into a final cohort of 690 participants. For each participant, tabular data of the risk factors of MI were transformed into standardized textual descriptions for ChatGPT recognition. Responses were generated by asking ChatGPT to select a score ranging from 0 to 10 representing the risk. Chain of Thought (CoT) questioning was used to evaluate whether LLMs make prediction logically. The predictive performance of ChatGPT was compared with published medical indices, traditional machine learning models and other large language models. Conclusions: Current LLMs are not ready to be applied in clinical medicine fields. Future medical LLMs are suggested to be expert in medical domain knowledge to understand both natural languages and quantified medical data, and further make logical inferences.
Anisotropic Diffusion Probabilistic Model for Imbalanced Image Classification
Sep 22, 2024



Real-world data often has a long-tailed distribution, where the scarcity of tail samples significantly limits the model's generalization ability. Denoising Diffusion Probabilistic Models (DDPM) are generative models based on stochastic differential equation theory and have demonstrated impressive performance in image classification tasks. However, existing diffusion probabilistic models do not perform satisfactorily in classifying tail classes. In this work, we propose the Anisotropic Diffusion Probabilistic Model (ADPM) for imbalanced image classification problems. We utilize the data distribution to control the diffusion speed of different class samples during the forward process, effectively improving the classification accuracy of the denoiser in the reverse process. Specifically, we provide a theoretical strategy for selecting noise levels for different categories in the diffusion process based on error analysis theory to address the imbalanced classification problem. Furthermore, we integrate global and local image prior in the forward process to enhance the model's discriminative ability in the spatial dimension, while incorporate semantic-level contextual information in the reverse process to boost the model's discriminative power and robustness. Through comparisons with state-of-the-art methods on four medical benchmark datasets, we validate the effectiveness of the proposed method in handling long-tail data. Our results confirm that the anisotropic diffusion model significantly improves the classification accuracy of rare classes while maintaining the accuracy of head classes. On the skin lesion datasets, PAD-UFES and HAM10000, the F1-scores of our method improved by 4% and 3%, respectively compared to the original diffusion probabilistic model.
Low-resolution Prior Equilibrium Network for CT Reconstruction
Jan 28, 2024The unrolling method has been investigated for learning variational models in X-ray computed tomography. However, it has been observed that directly unrolling the regularization model through gradient descent does not produce satisfactory results. In this paper, we present a novel deep learning-based CT reconstruction model, where the low-resolution image is introduced to obtain an effective regularization term for improving the network`s robustness. Our approach involves constructing the backbone network architecture by algorithm unrolling that is realized using the deep equilibrium architecture. We theoretically discuss the convergence of the proposed low-resolution prior equilibrium model and provide the conditions to guarantee convergence. Experimental results on both sparse-view and limited-angle reconstruction problems are provided, demonstrating that our end-to-end low-resolution prior equilibrium model outperforms other state-of-the-art methods in terms of noise reduction, contrast-to-noise ratio, and preservation of edge details.
ParaTransCNN: Parallelized TransCNN Encoder for Medical Image Segmentation
Jan 27, 2024The convolutional neural network-based methods have become more and more popular for medical image segmentation due to their outstanding performance. However, they struggle with capturing long-range dependencies, which are essential for accurately modeling global contextual correlations. Thanks to the ability to model long-range dependencies by expanding the receptive field, the transformer-based methods have gained prominence. Inspired by this, we propose an advanced 2D feature extraction method by combining the convolutional neural network and Transformer architectures. More specifically, we introduce a parallelized encoder structure, where one branch uses ResNet to extract local information from images, while the other branch uses Transformer to extract global information. Furthermore, we integrate pyramid structures into the Transformer to extract global information at varying resolutions, especially in intensive prediction tasks. To efficiently utilize the different information in the parallelized encoder at the decoder stage, we use a channel attention module to merge the features of the encoder and propagate them through skip connections and bottlenecks. Intensive numerical experiments are performed on both aortic vessel tree, cardiac, and multi-organ datasets. By comparing with state-of-the-art medical image segmentation methods, our method is shown with better segmentation accuracy, especially on small organs. The code is publicly available on https://github.com/HongkunSun/ParaTransCNN.
A Novel Multi-Task Model Imitating Dermatologists for Accurate Differential Diagnosis of Skin Diseases in Clinical Images
Jul 17, 2023
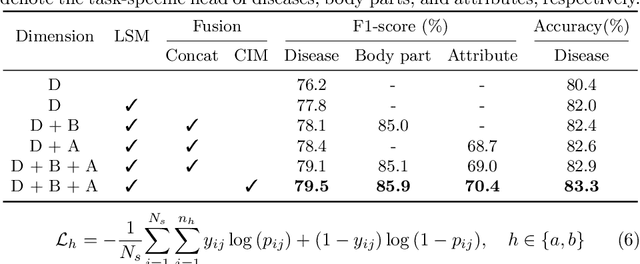
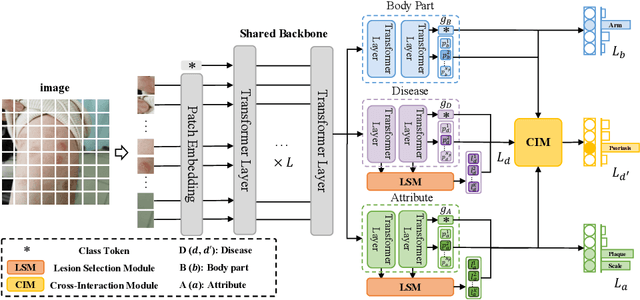
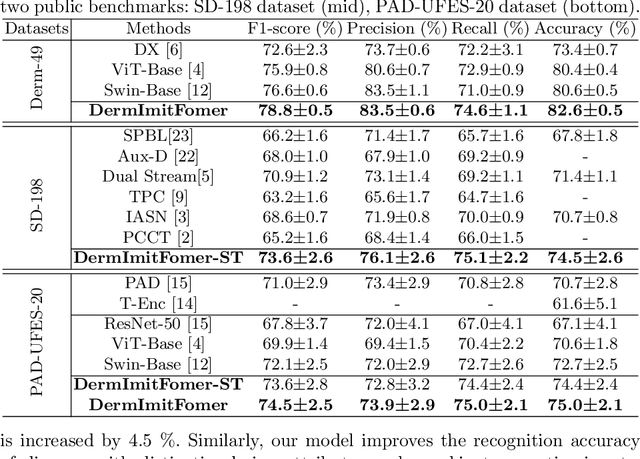
Skin diseases are among the most prevalent health issues, and accurate computer-aided diagnosis methods are of importance for both dermatologists and patients. However, most of the existing methods overlook the essential domain knowledge required for skin disease diagnosis. A novel multi-task model, namely DermImitFormer, is proposed to fill this gap by imitating dermatologists' diagnostic procedures and strategies. Through multi-task learning, the model simultaneously predicts body parts and lesion attributes in addition to the disease itself, enhancing diagnosis accuracy and improving diagnosis interpretability. The designed lesion selection module mimics dermatologists' zoom-in action, effectively highlighting the local lesion features from noisy backgrounds. Additionally, the presented cross-interaction module explicitly models the complicated diagnostic reasoning between body parts, lesion attributes, and diseases. To provide a more robust evaluation of the proposed method, a large-scale clinical image dataset of skin diseases with significantly more cases than existing datasets has been established. Extensive experiments on three different datasets consistently demonstrate the state-of-the-art recognition performance of the proposed approach.