 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWindow-based Channel Attention for Wavelet-enhanced Learned Image Compression
Sep 21, 2024
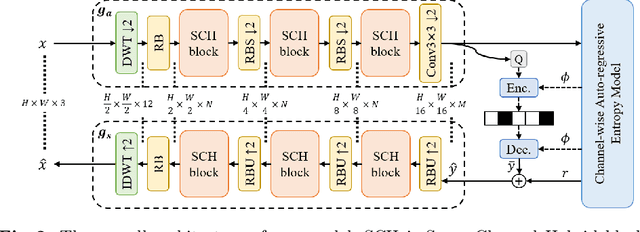
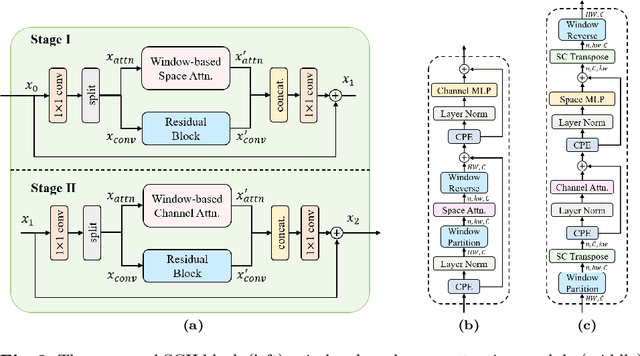
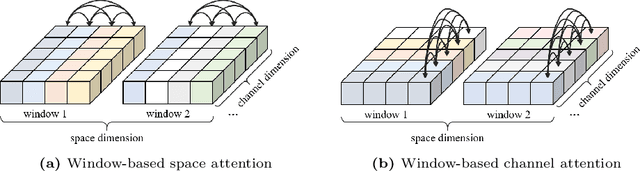
Learned Image Compression (LIC) models have achieved superior rate-distortion performance than traditional codecs. Existing LIC models use CNN, Transformer, or Mixed CNN-Transformer as basic blocks. However, limited by the shifted window attention, Swin-Transformer-based LIC exhibits a restricted growth of receptive fields, affecting the ability to model large objects in the image. To address this issue, we incorporate window partition into channel attention for the first time to obtain large receptive fields and capture more global information. Since channel attention hinders local information learning, it is important to extend existing attention mechanisms in Transformer codecs to the space-channel attention to establish multiple receptive fields, being able to capture global correlations with large receptive fields while maintaining detailed characterization of local correlations with small receptive fields. We also incorporate the discrete wavelet transform into our Spatial-Channel Hybrid (SCH) framework for efficient frequency-dependent down-sampling and further enlarging receptive fields. Experiment results demonstrate that our method achieves state-of-the-art performances, reducing BD-rate by 18.54%, 23.98%, 22.33%, and 24.71% on four standard datasets compared to VTM-23.1.
Learning to Adapt CLIP for Few-Shot Monocular Depth Estimation
Nov 02, 2023



Pre-trained Vision-Language Models (VLMs), such as CLIP, have shown enhanced performance across a range of tasks that involve the integration of visual and linguistic modalities. When CLIP is used for depth estimation tasks, the patches, divided from the input images, can be combined with a series of semantic descriptions of the depth information to obtain similarity results. The coarse estimation of depth is then achieved by weighting and summing the depth values, called depth bins, corresponding to the predefined semantic descriptions. The zero-shot approach circumvents the computational and time-intensive nature of traditional fully-supervised depth estimation methods. However, this method, utilizing fixed depth bins, may not effectively generalize as images from different scenes may exhibit distinct depth distributions. To address this challenge, we propose a few-shot-based method which learns to adapt the VLMs for monocular depth estimation to balance training costs and generalization capabilities. Specifically, it assigns different depth bins for different scenes, which can be selected by the model during inference. Additionally, we incorporate learnable prompts to preprocess the input text to convert the easily human-understood text into easily model-understood vectors and further enhance the performance. With only one image per scene for training, our extensive experiment results on the NYU V2 and KITTI dataset demonstrate that our method outperforms the previous state-of-the-art method by up to 10.6\% in terms of MARE.