 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClass Machine Unlearning for Complex Data via Concepts Inference and Data Poisoning
Paper and Code
May 24, 2024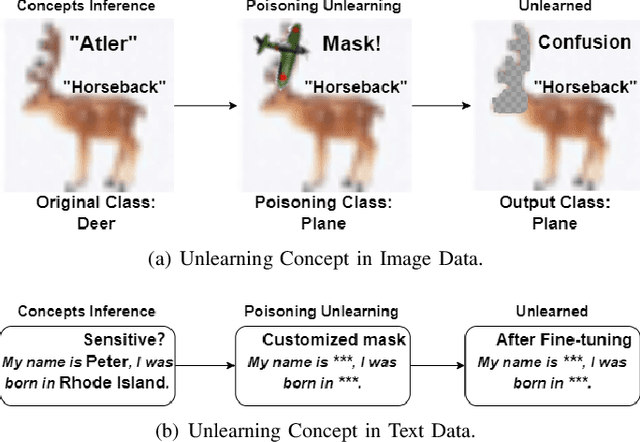
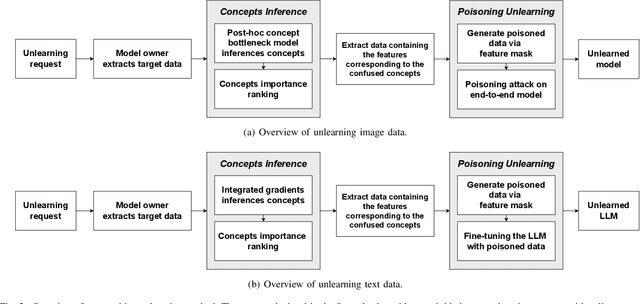


In current AI era, users may request AI companies to delete their data from the training dataset due to the privacy concerns. As a model owner, retraining a model will consume significant computational resources. Therefore, machine unlearning is a new emerged technology to allow model owner to delete requested training data or a class with little affecting on the model performance. However, for large-scaling complex data, such as image or text data, unlearning a class from a model leads to a inferior performance due to the difficulty to identify the link between classes and model. An inaccurate class deleting may lead to over or under unlearning. In this paper, to accurately defining the unlearning class of complex data, we apply the definition of Concept, rather than an image feature or a token of text data, to represent the semantic information of unlearning class. This new representation can cut the link between the model and the class, leading to a complete erasing of the impact of a class. To analyze the impact of the concept of complex data, we adopt a Post-hoc Concept Bottleneck Model, and Integrated Gradients to precisely identify concepts across different classes. Next, we take advantage of data poisoning with random and targeted labels to propose unlearning methods. We test our methods on both image classification models and large language models (LLMs). The results consistently show that the proposed methods can accurately erase targeted information from models and can largely maintain the performance of the models.