 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBaichuan-M3: Modeling Clinical Inquiry for Reliable Medical Decision-Making
Feb 06, 2026We introduce Baichuan-M3, a medical-enhanced large language model engineered to shift the paradigm from passive question-answering to active, clinical-grade decision support. Addressing the limitations of existing systems in open-ended consultations, Baichuan-M3 utilizes a specialized training pipeline to model the systematic workflow of a physician. Key capabilities include: (i) proactive information acquisition to resolve ambiguity; (ii) long-horizon reasoning that unifies scattered evidence into coherent diagnoses; and (iii) adaptive hallucination suppression to ensure factual reliability. Empirical evaluations demonstrate that Baichuan-M3 achieves state-of-the-art results on HealthBench, the newly introduced HealthBench-Hallu and ScanBench, significantly outperforming GPT-5.2 in clinical inquiry, advisory and safety. The models are publicly available at https://huggingface.co/collections/baichuan-inc/baichuan-m3.
Progressive Conditioned Scale-Shift Recalibration of Self-Attention for Online Test-time Adaptation
Dec 14, 2025
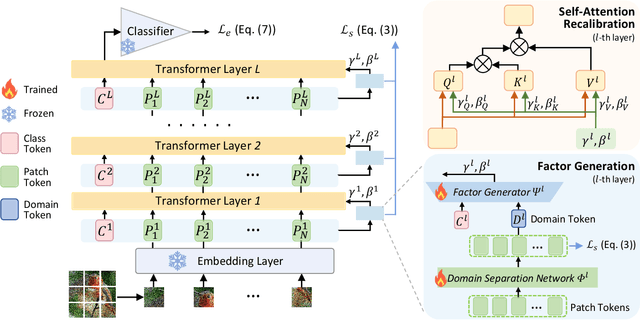


Online test-time adaptation aims to dynamically adjust a network model in real-time based on sequential input samples during the inference stage. In this work, we find that, when applying a transformer network model to a new target domain, the Query, Key, and Value features of its self-attention module often change significantly from those in the source domain, leading to substantial performance degradation of the transformer model. To address this important issue, we propose to develop a new approach to progressively recalibrate the self-attention at each layer using a local linear transform parameterized by conditioned scale and shift factors. We consider the online model adaptation from the source domain to the target domain as a progressive domain shift separation process. At each transformer network layer, we learn a Domain Separation Network to extract the domain shift feature, which is used to predict the scale and shift parameters for self-attention recalibration using a Factor Generator Network. These two lightweight networks are adapted online during inference. Experimental results on benchmark datasets demonstrate that the proposed progressive conditioned scale-shift recalibration (PCSR) method is able to significantly improve the online test-time domain adaptation performance by a large margin of up to 3.9\% in classification accuracy on the ImageNet-C dataset.
Domain-Conditioned Transformer for Fully Test-time Adaptation
Oct 14, 2024Fully test-time adaptation aims to adapt a network model online based on sequential analysis of input samples during the inference stage. We observe that, when applying a transformer network model into a new domain, the self-attention profiles of image samples in the target domain deviate significantly from those in the source domain, which results in large performance degradation during domain changes. To address this important issue, we propose a new structure for the self-attention modules in the transformer. Specifically, we incorporate three domain-conditioning vectors, called domain conditioners, into the query, key, and value components of the self-attention module. We learn a network to generate these three domain conditioners from the class token at each transformer network layer. We find that, during fully online test-time adaptation, these domain conditioners at each transform network layer are able to gradually remove the impact of domain shift and largely recover the original self-attention profile. Our extensive experimental results demonstrate that the proposed domain-conditioned transformer significantly improves the online fully test-time domain adaptation performance and outperforms existing state-of-the-art methods by large margins.
ASP: Automatic Selection of Proxy dataset for efficient AutoML
Oct 17, 2023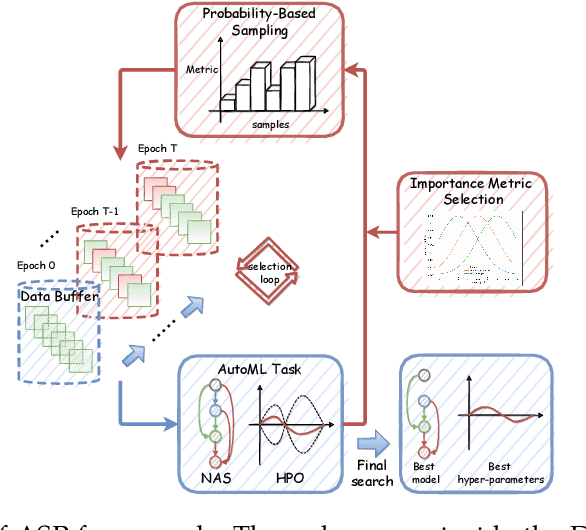
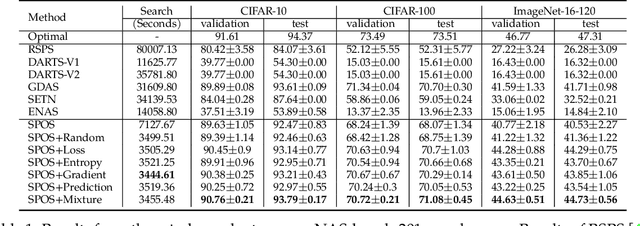
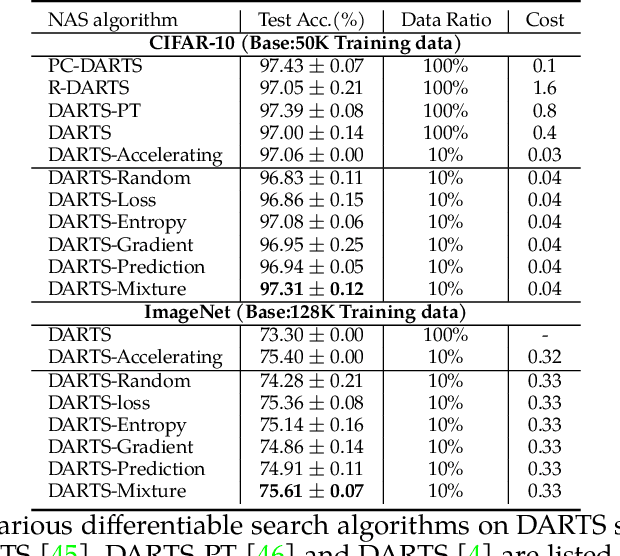
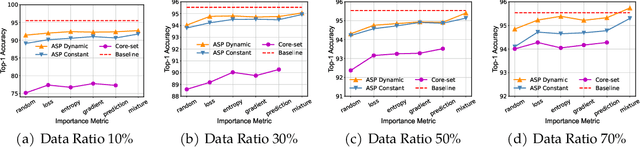
Deep neural networks have gained great success due to the increasing amounts of data, and diverse effective neural network designs. However, it also brings a heavy computing burden as the amount of training data is proportional to the training time. In addition, a well-behaved model requires repeated trials of different structure designs and hyper-parameters, which may take a large amount of time even with state-of-the-art (SOTA) hyper-parameter optimization (HPO) algorithms and neural architecture search (NAS) algorithms. In this paper, we propose an Automatic Selection of Proxy dataset framework (ASP) aimed to dynamically find the informative proxy subsets of training data at each epoch, reducing the training data size as well as saving the AutoML processing time. We verify the effectiveness and generalization of ASP on CIFAR10, CIFAR100, ImageNet16-120, and ImageNet-1k, across various public model benchmarks. The experiment results show that ASP can obtain better results than other data selection methods at all selection ratios. ASP can also enable much more efficient AutoML processing with a speedup of 2x-20x while obtaining better architectures and better hyper-parameters compared to utilizing the entire dataset.
USDC: Unified Static and Dynamic Compression for Visual Transformer
Oct 17, 2023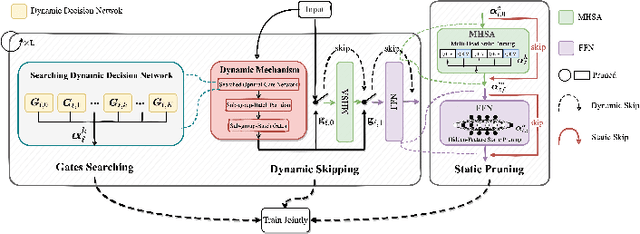
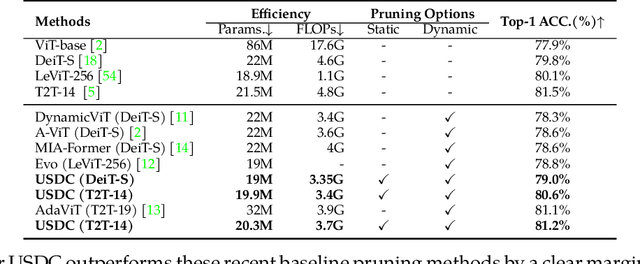
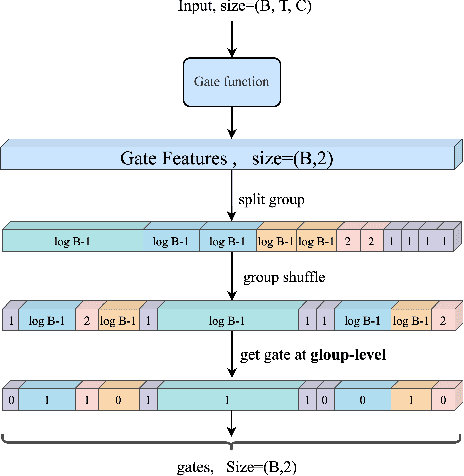
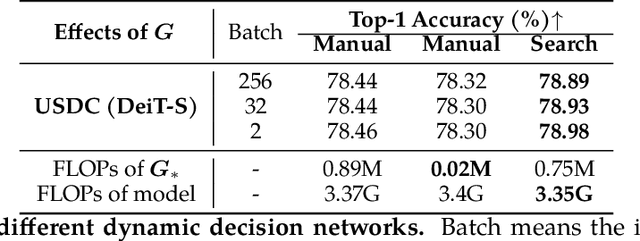
Visual Transformers have achieved great success in almost all vision tasks, such as classification, detection, and so on. However, the model complexity and the inference speed of the visual transformers hinder their deployments in industrial products. Various model compression techniques focus on directly compressing the visual transformers into a smaller one while maintaining the model performance, however, the performance drops dramatically when the compression ratio is large. Furthermore, several dynamic network techniques have also been applied to dynamically compress the visual transformers to obtain input-adaptive efficient sub-structures during the inference stage, which can achieve a better trade-off between the compression ratio and the model performance. The upper bound of memory of dynamic models is not reduced in the practical deployment since the whole original visual transformer model and the additional control gating modules should be loaded onto devices together for inference. To alleviate two disadvantages of two categories of methods, we propose to unify the static compression and dynamic compression techniques jointly to obtain an input-adaptive compressed model, which can further better balance the total compression ratios and the model performances. Moreover, in practical deployment, the batch sizes of the training and inference stage are usually different, which will cause the model inference performance to be worse than the model training performance, which is not touched by all previous dynamic network papers. We propose a sub-group gates augmentation technique to solve this performance drop problem. Extensive experiments demonstrate the superiority of our method on various baseline visual transformers such as DeiT, T2T-ViT, and so on.