 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSceneExpander: Expanding 3D Scenes with Free-Form Inserted Views
Mar 31, 2026World building with 3D scene representations is increasingly important for content creation, simulation, and interactive experiences, yet real workflows are inherently iterative: creators must repeatedly extend an existing scene under user control. Motivated by this research gap, we study 3D scene expansion in a user-centric workflow: starting from a real scene captured by multi-view images, we extend its coverage by inserting an additional view synthesized by a generative model. Unlike simple object editing or style transfer in a fixed scene, the inserted view is often 3D-misaligned with the original reconstruction, introducing geometry shifts, hallucinated content, or view-dependent artifacts that break global multi-view consistency. To address the challenge, we propose SceneExpander, which applies test-time adaptation to a parametric feed-forward 3D reconstruction model with two complementary distillation signals: anchor distillation stabilizes the original scene by distilling geometric cues from the captured views, while inserted-view self-distillation preserves observation-supported predictions yet adapts latent geometry and appearance to accommodate the misaligned inserted view. Experiments on ETH scenes and online data demonstrate improved expansion behavior and reconstruction quality under misalignment.
MoBA: Mixture of Block Attention for Long-Context LLMs
Feb 18, 2025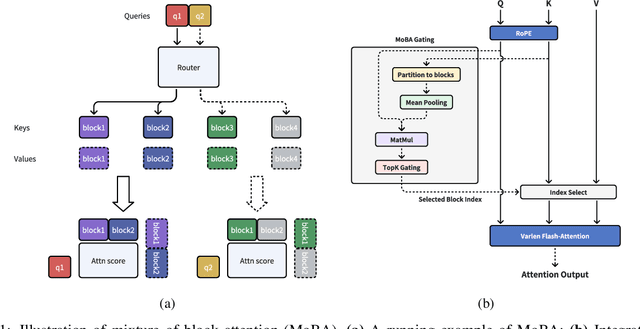
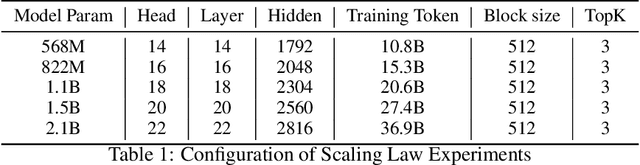
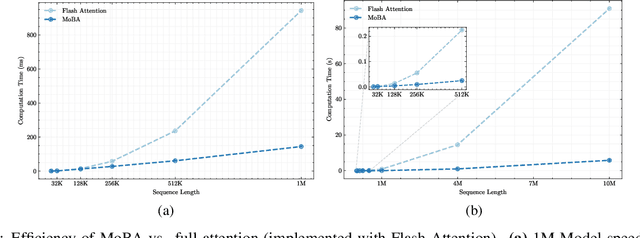
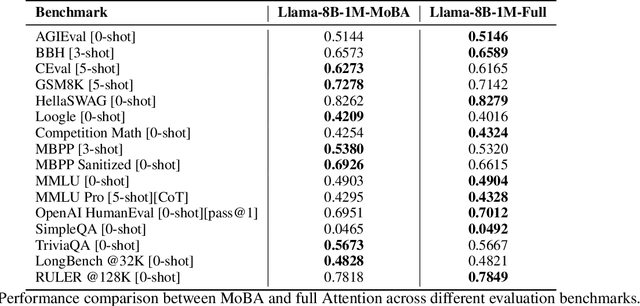
Scaling the effective context length is essential for advancing large language models (LLMs) toward artificial general intelligence (AGI). However, the quadratic increase in computational complexity inherent in traditional attention mechanisms presents a prohibitive overhead. Existing approaches either impose strongly biased structures, such as sink or window attention which are task-specific, or radically modify the attention mechanism into linear approximations, whose performance in complex reasoning tasks remains inadequately explored. In this work, we propose a solution that adheres to the ``less structure'' principle, allowing the model to determine where to attend autonomously, rather than introducing predefined biases. We introduce Mixture of Block Attention (MoBA), an innovative approach that applies the principles of Mixture of Experts (MoE) to the attention mechanism. This novel architecture demonstrates superior performance on long-context tasks while offering a key advantage: the ability to seamlessly transition between full and sparse attention, enhancing efficiency without the risk of compromising performance. MoBA has already been deployed to support Kimi's long-context requests and demonstrates significant advancements in efficient attention computation for LLMs. Our code is available at https://github.com/MoonshotAI/MoBA.
USDC: Unified Static and Dynamic Compression for Visual Transformer
Oct 17, 2023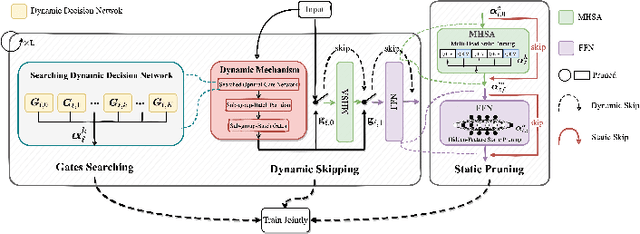
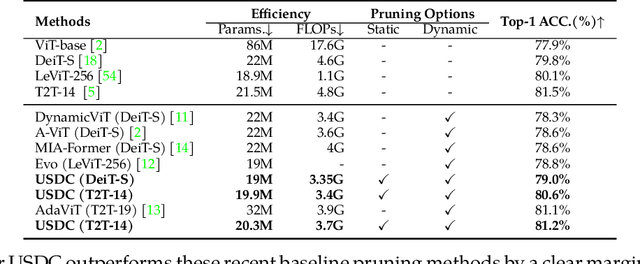
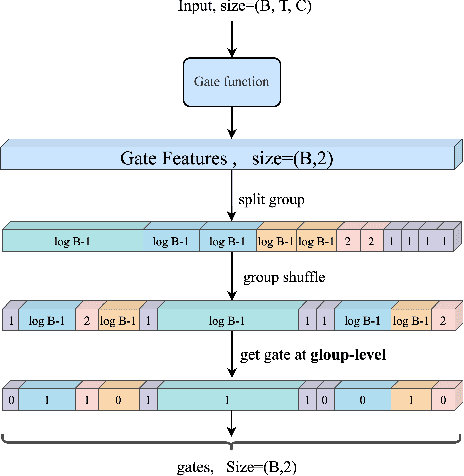
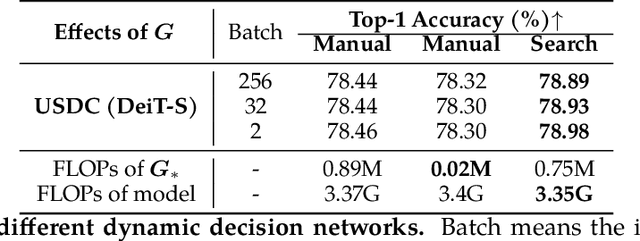
Visual Transformers have achieved great success in almost all vision tasks, such as classification, detection, and so on. However, the model complexity and the inference speed of the visual transformers hinder their deployments in industrial products. Various model compression techniques focus on directly compressing the visual transformers into a smaller one while maintaining the model performance, however, the performance drops dramatically when the compression ratio is large. Furthermore, several dynamic network techniques have also been applied to dynamically compress the visual transformers to obtain input-adaptive efficient sub-structures during the inference stage, which can achieve a better trade-off between the compression ratio and the model performance. The upper bound of memory of dynamic models is not reduced in the practical deployment since the whole original visual transformer model and the additional control gating modules should be loaded onto devices together for inference. To alleviate two disadvantages of two categories of methods, we propose to unify the static compression and dynamic compression techniques jointly to obtain an input-adaptive compressed model, which can further better balance the total compression ratios and the model performances. Moreover, in practical deployment, the batch sizes of the training and inference stage are usually different, which will cause the model inference performance to be worse than the model training performance, which is not touched by all previous dynamic network papers. We propose a sub-group gates augmentation technique to solve this performance drop problem. Extensive experiments demonstrate the superiority of our method on various baseline visual transformers such as DeiT, T2T-ViT, and so on.
Resource Constrained Model Compression via Minimax Optimization for Spiking Neural Networks
Aug 09, 2023



Brain-inspired Spiking Neural Networks (SNNs) have the characteristics of event-driven and high energy-efficient, which are different from traditional Artificial Neural Networks (ANNs) when deployed on edge devices such as neuromorphic chips. Most previous work focuses on SNNs training strategies to improve model performance and brings larger and deeper network architectures. It is difficult to deploy these complex networks on resource-limited edge devices directly. To meet such demand, people compress SNNs very cautiously to balance the performance and the computation efficiency. Existing compression methods either iteratively pruned SNNs using weights norm magnitude or formulated the problem as a sparse learning optimization. We propose an improved end-to-end Minimax optimization method for this sparse learning problem to better balance the model performance and the computation efficiency. We also demonstrate that jointly applying compression and finetuning on SNNs is better than sequentially, especially for extreme compression ratios. The compressed SNN models achieved state-of-the-art (SOTA) performance on various benchmark datasets and architectures. Our code is available at https://github.com/chenjallen/Resource-Constrained-Compression-on-SNN.
Unified Visual Transformer Compression
Mar 15, 2022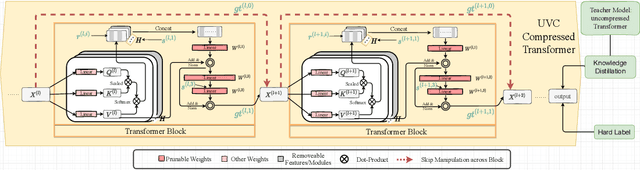
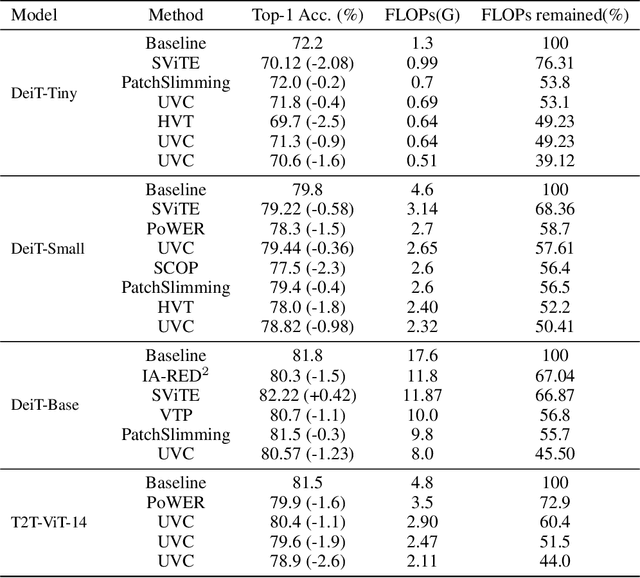
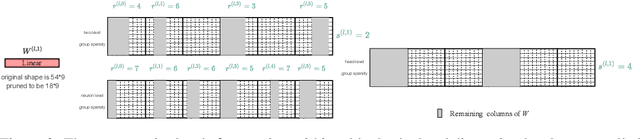
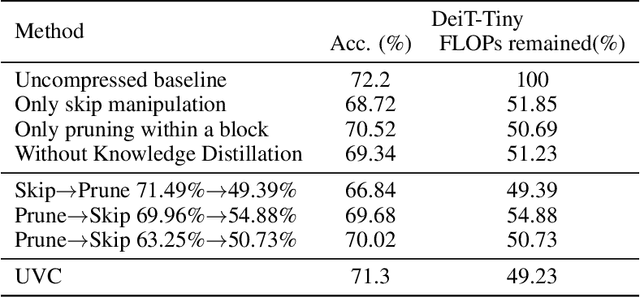
Vision transformers (ViTs) have gained popularity recently. Even without customized image operators such as convolutions, ViTs can yield competitive performance when properly trained on massive data. However, the computational overhead of ViTs remains prohibitive, due to stacking multi-head self-attention modules and else. Compared to the vast literature and prevailing success in compressing convolutional neural networks, the study of Vision Transformer compression has also just emerged, and existing works focused on one or two aspects of compression. This paper proposes a unified ViT compression framework that seamlessly assembles three effective techniques: pruning, layer skipping, and knowledge distillation. We formulate a budget-constrained, end-to-end optimization framework, targeting jointly learning model weights, layer-wise pruning ratios/masks, and skip configurations, under a distillation loss. The optimization problem is then solved using the primal-dual algorithm. Experiments are conducted with several ViT variants, e.g. DeiT and T2T-ViT backbones on the ImageNet dataset, and our approach consistently outperforms recent competitors. For example, DeiT-Tiny can be trimmed down to 50\% of the original FLOPs almost without losing accuracy. Codes are available online:~\url{https://github.com/VITA-Group/UVC}.
GDP: Stabilized Neural Network Pruning via Gates with Differentiable Polarization
Sep 08, 2021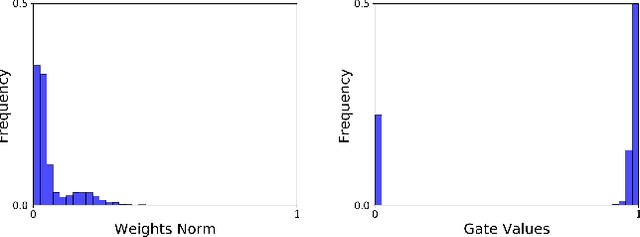

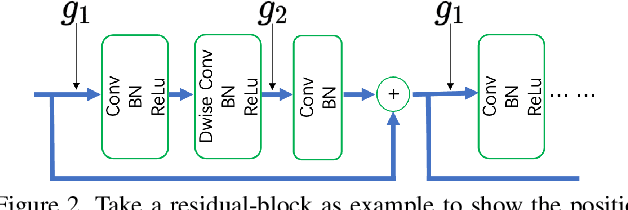

Model compression techniques are recently gaining explosive attention for obtaining efficient AI models for various real-time applications. Channel pruning is one important compression strategy and is widely used in slimming various DNNs. Previous gate-based or importance-based pruning methods aim to remove channels whose importance is smallest. However, it remains unclear what criteria the channel importance should be measured on, leading to various channel selection heuristics. Some other sampling-based pruning methods deploy sampling strategies to train sub-nets, which often causes the training instability and the compressed model's degraded performance. In view of the research gaps, we present a new module named Gates with Differentiable Polarization (GDP), inspired by principled optimization ideas. GDP can be plugged before convolutional layers without bells and whistles, to control the on-and-off of each channel or whole layer block. During the training process, the polarization effect will drive a subset of gates to smoothly decrease to exact zero, while other gates gradually stay away from zero by a large margin. When training terminates, those zero-gated channels can be painlessly removed, while other non-zero gates can be absorbed into the succeeding convolution kernel, causing completely no interruption to training nor damage to the trained model. Experiments conducted over CIFAR-10 and ImageNet datasets show that the proposed GDP algorithm achieves the state-of-the-art performance on various benchmark DNNs at a broad range of pruning ratios. We also apply GDP to DeepLabV3Plus-ResNet50 on the challenging Pascal VOC segmentation task, whose test performance sees no drop (even slightly improved) with over 60% FLOPs saving.
Dual-Sampling Attention Network for Diagnosis of COVID-19 from Community Acquired Pneumonia
May 20, 2020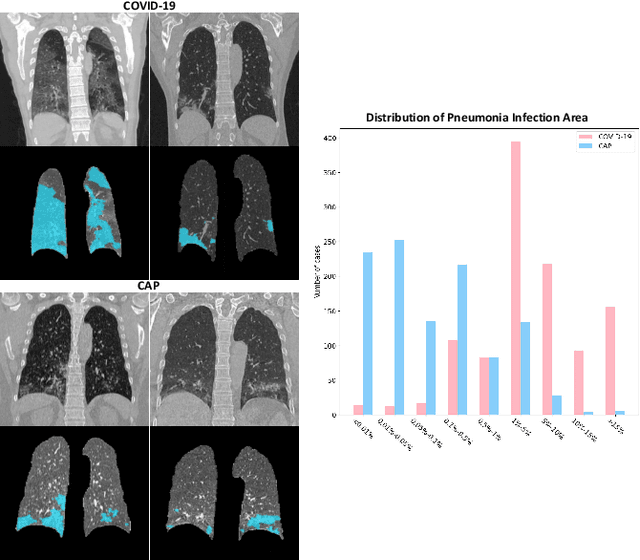
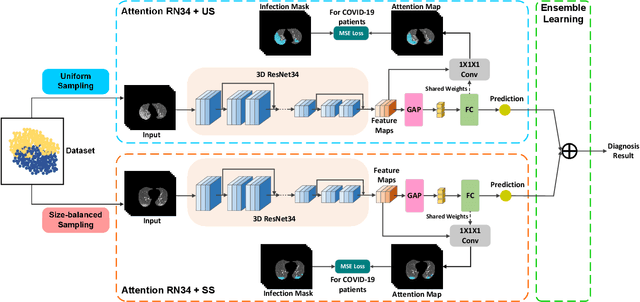
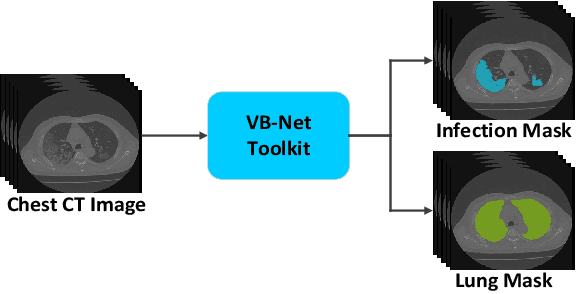
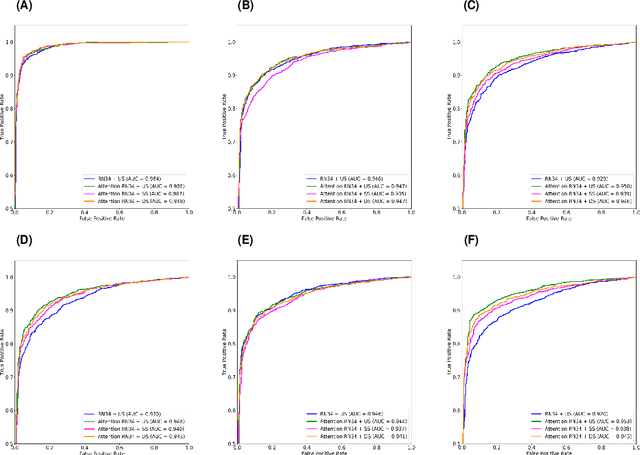
The coronavirus disease (COVID-19) is rapidly spreading all over the world, and has infected more than 1,436,000 people in more than 200 countries and territories as of April 9, 2020. Detecting COVID-19 at early stage is essential to deliver proper healthcare to the patients and also to protect the uninfected population. To this end, we develop a dual-sampling attention network to automatically diagnose COVID- 19 from the community acquired pneumonia (CAP) in chest computed tomography (CT). In particular, we propose a novel online attention module with a 3D convolutional network (CNN) to focus on the infection regions in lungs when making decisions of diagnoses. Note that there exists imbalanced distribution of the sizes of the infection regions between COVID-19 and CAP, partially due to fast progress of COVID-19 after symptom onset. Therefore, we develop a dual-sampling strategy to mitigate the imbalanced learning. Our method is evaluated (to our best knowledge) upon the largest multi-center CT data for COVID-19 from 8 hospitals. In the training-validation stage, we collect 2186 CT scans from 1588 patients for a 5-fold cross-validation. In the testing stage, we employ another independent large-scale testing dataset including 2796 CT scans from 2057 patients. Results show that our algorithm can identify the COVID-19 images with the area under the receiver operating characteristic curve (AUC) value of 0.944, accuracy of 87.5%, sensitivity of 86.9%, specificity of 90.1%, and F1-score of 82.0%. With this performance, the proposed algorithm could potentially aid radiologists with COVID-19 diagnosis from CAP, especially in the early stage of the COVID-19 outbreak.
Adaptive Feature Selection Guided Deep Forest for COVID-19 Classification with Chest CT
May 07, 2020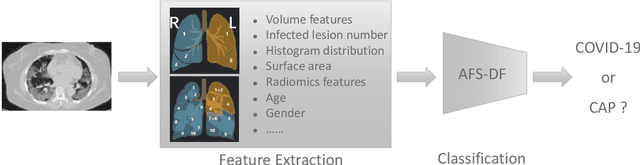
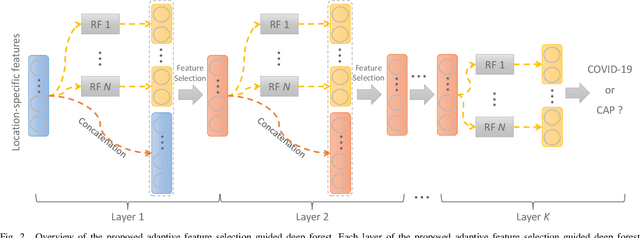
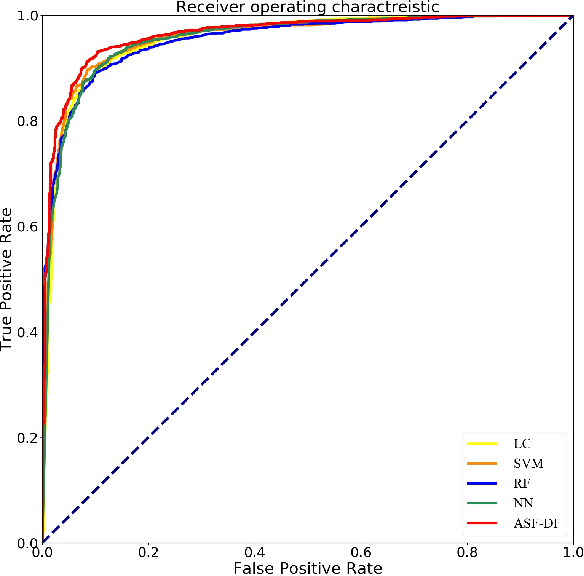
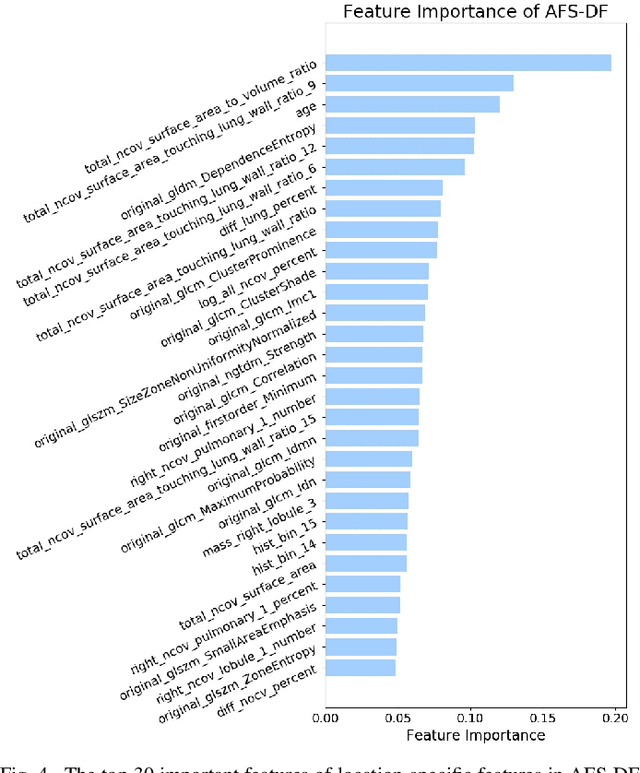
Chest computed tomography (CT) becomes an effective tool to assist the diagnosis of coronavirus disease-19 (COVID-19). Due to the outbreak of COVID-19 worldwide, using the computed-aided diagnosis technique for COVID-19 classification based on CT images could largely alleviate the burden of clinicians. In this paper, we propose an Adaptive Feature Selection guided Deep Forest (AFS-DF) for COVID-19 classification based on chest CT images. Specifically, we first extract location-specific features from CT images. Then, in order to capture the high-level representation of these features with the relatively small-scale data, we leverage a deep forest model to learn high-level representation of the features. Moreover, we propose a feature selection method based on the trained deep forest model to reduce the redundancy of features, where the feature selection could be adaptively incorporated with the COVID-19 classification model. We evaluated our proposed AFS-DF on COVID-19 dataset with 1495 patients of COVID-19 and 1027 patients of community acquired pneumonia (CAP). The accuracy (ACC), sensitivity (SEN), specificity (SPE) and AUC achieved by our method are 91.79%, 93.05%, 89.95% and 96.35%, respectively. Experimental results on the COVID-19 dataset suggest that the proposed AFS-DF achieves superior performance in COVID-19 vs. CAP classification, compared with 4 widely used machine learning methods.
Diagnosis of Coronavirus Disease 2019 (COVID-19) with Structured Latent Multi-View Representation Learning
May 06, 2020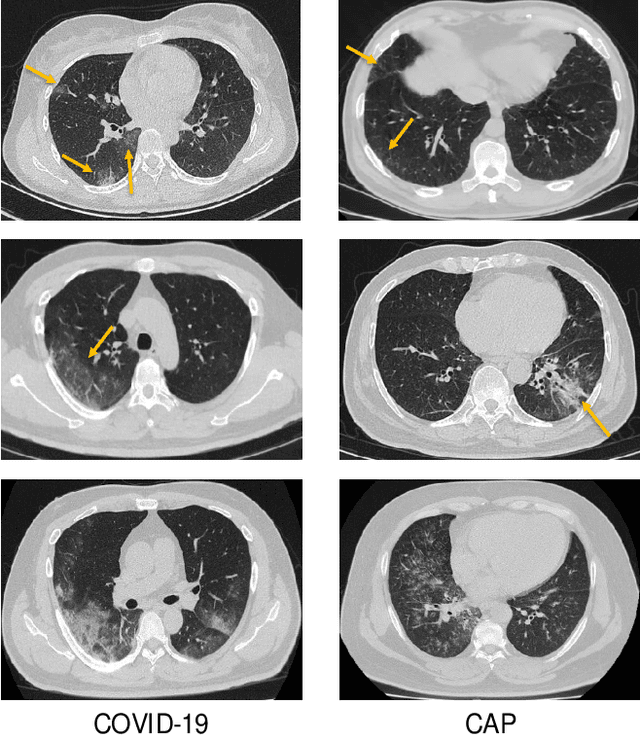
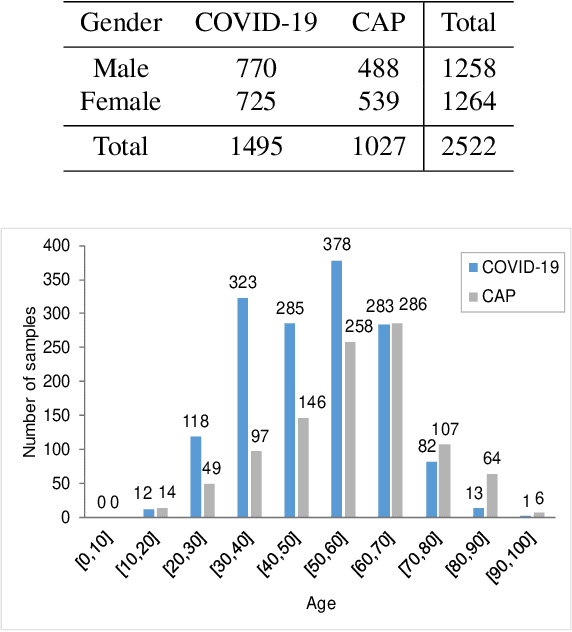
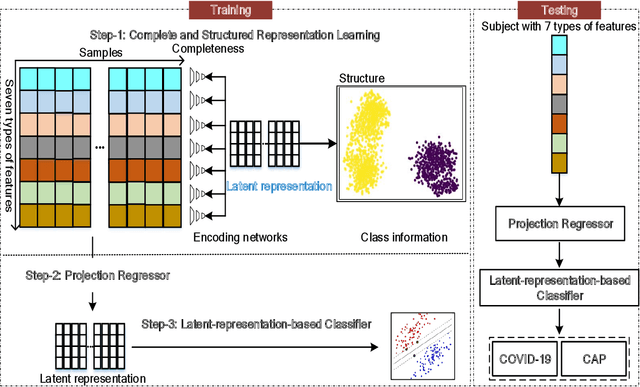
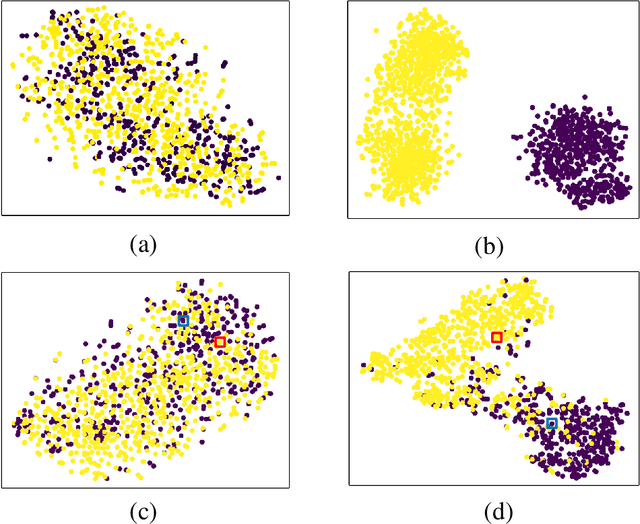
Recently, the outbreak of Coronavirus Disease 2019 (COVID-19) has spread rapidly across the world. Due to the large number of affected patients and heavy labor for doctors, computer-aided diagnosis with machine learning algorithm is urgently needed, and could largely reduce the efforts of clinicians and accelerate the diagnosis process. Chest computed tomography (CT) has been recognized as an informative tool for diagnosis of the disease. In this study, we propose to conduct the diagnosis of COVID-19 with a series of features extracted from CT images. To fully explore multiple features describing CT images from different views, a unified latent representation is learned which can completely encode information from different aspects of features and is endowed with promising class structure for separability. Specifically, the completeness is guaranteed with a group of backward neural networks (each for one type of features), while by using class labels the representation is enforced to be compact within COVID-19/community-acquired pneumonia (CAP) and also a large margin is guaranteed between different types of pneumonia. In this way, our model can well avoid overfitting compared to the case of directly projecting highdimensional features into classes. Extensive experimental results show that the proposed method outperforms all comparison methods, and rather stable performances are observed when varying the numbers of training data.
Large-Scale Screening of COVID-19 from Community Acquired Pneumonia using Infection Size-Aware Classification
Mar 22, 2020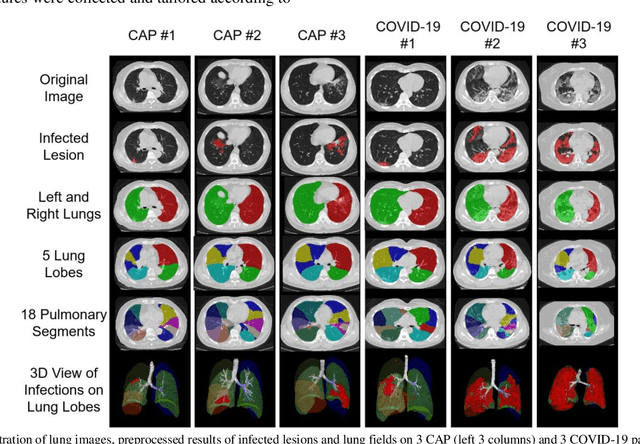

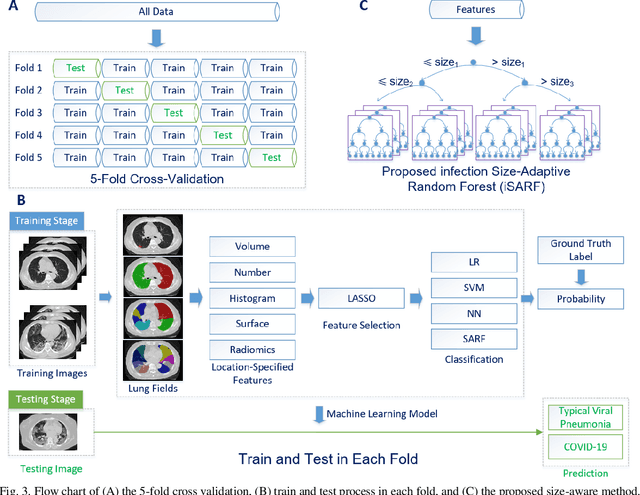
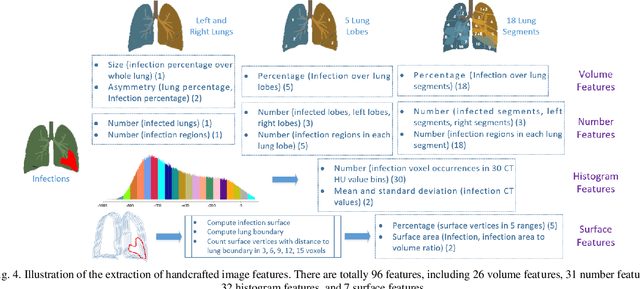
The worldwide spread of coronavirus disease (COVID-19) has become a threatening risk for global public health. It is of great importance to rapidly and accurately screen patients with COVID-19 from community acquired pneumonia (CAP). In this study, a total of 1658 patients with COVID-19 and 1027 patients of CAP underwent thin-section CT. All images were preprocessed to obtain the segmentations of both infections and lung fields, which were used to extract location-specific features. An infection Size Aware Random Forest method (iSARF) was proposed, in which subjects were automated categorized into groups with different ranges of infected lesion sizes, followed by random forests in each group for classification. Experimental results show that the proposed method yielded sensitivity of 0.907, specificity of 0.833, and accuracy of 0.879 under five-fold cross-validation. Large performance margins against comparison methods were achieved especially for the cases with infection size in the medium range, from 0.01% to 10%. The further inclusion of Radiomics features show slightly improvement. It is anticipated that our proposed framework could assist clinical decision making.