 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntermediate Domain-guided Adaptation for Unsupervised Chorioallantoic Membrane Vessel Segmentation
Mar 06, 2025



The chorioallantoic membrane (CAM) model is widely employed in angiogenesis research, and distribution of growing blood vessels is the key evaluation indicator. As a result, vessel segmentation is crucial for quantitative assessment based on topology and morphology. However, manual segmentation is extremely time-consuming, labor-intensive, and prone to inconsistency due to its subjective nature. Moreover, research on CAM vessel segmentation algorithms remains limited, and the lack of public datasets contributes to poor prediction performance. To address these challenges, we propose an innovative Intermediate Domain-guided Adaptation (IDA) method, which utilizes the similarity between CAM images and retinal images, along with existing public retinal datasets, to perform unsupervised training on CAM images. Specifically, we introduce a Multi-Resolution Asymmetric Translation (MRAT) strategy to generate intermediate images to promote image-level interaction. Then, an Intermediate Domain-guided Contrastive Learning (IDCL) module is developed to disentangle cross-domain feature representations. This method overcomes the limitations of existing unsupervised domain adaptation (UDA) approaches, which primarily concentrate on directly source-target alignment while neglecting intermediate domain information. Notably, we create the first CAM dataset to validate the proposed algorithm. Extensive experiments on this dataset show that our method outperforms compared approaches. Moreover, it achieves superior performance in UDA tasks across retinal datasets, highlighting its strong generalization capability. The CAM dataset and source codes are available at https://github.com/Light-47/IDA.
Label-free Prediction of Vascular Connectivity in Perfused Microvascular Networks in vitro
Feb 25, 2025



Continuous monitoring and in-situ assessment of microvascular connectivity have significant implications for culturing vascularized organoids and optimizing the therapeutic strategies. However, commonly used methods for vascular connectivity assessment heavily rely on fluorescent labels that may either raise biocompatibility concerns or interrupt the normal cell growth process. To address this issue, a Vessel Connectivity Network (VC-Net) was developed for label-free assessment of vascular connectivity. To validate the VC-Net, microvascular networks (MVNs) were cultured in vitro and their microscopic images were acquired at different culturing conditions as a training dataset. The VC-Net employs a Vessel Queue Contrastive Learning (VQCL) method and a class imbalance algorithm to address the issues of limited sample size, indistinctive class features and imbalanced class distribution in the dataset. The VC-Net successfully evaluated the vascular connectivity with no significant deviation from that by fluorescence imaging. In addition, the proposed VC-Net successfully differentiated the connectivity characteristics between normal and tumor-related MVNs. In comparison with those cultured in the regular microenvironment, the averaged connectivity of MVNs cultured in the tumor-related microenvironment decreased by 30.8%, whereas the non-connected area increased by 37.3%. This study provides a new avenue for label-free and continuous assessment of organoid or tumor vascularization in vitro.
ASP: Automatic Selection of Proxy dataset for efficient AutoML
Oct 17, 2023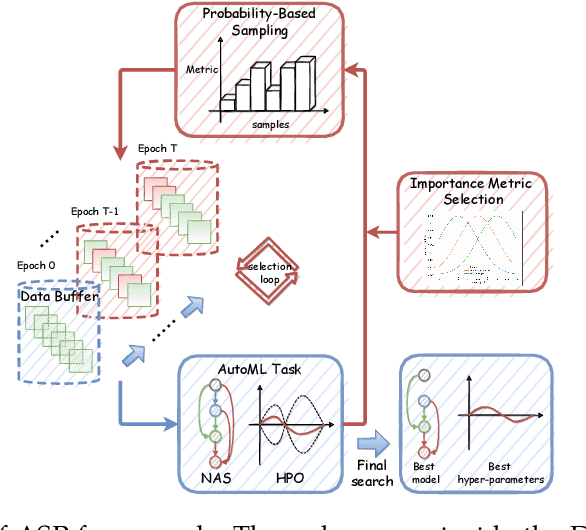
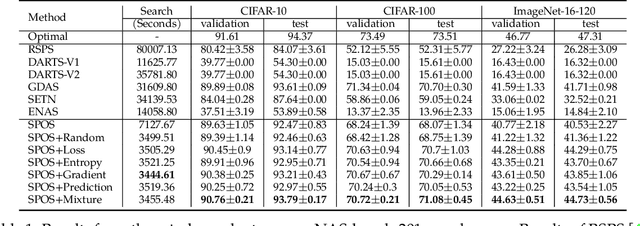
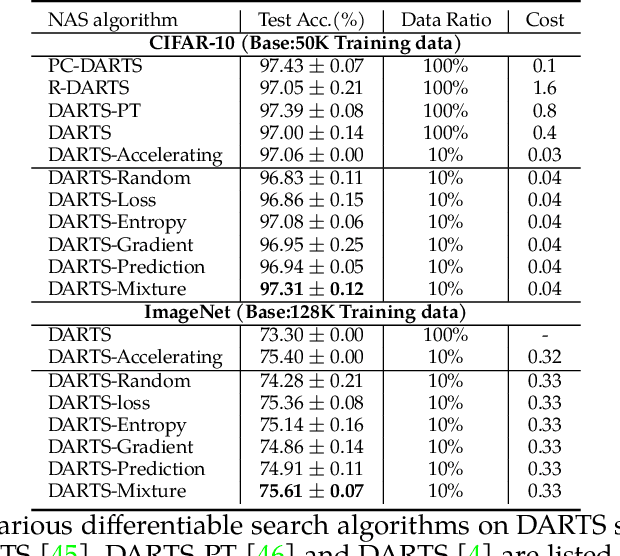
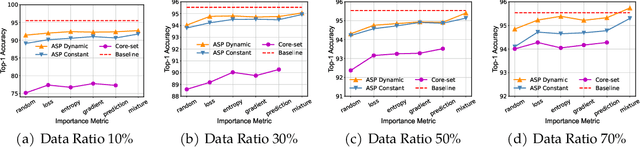
Deep neural networks have gained great success due to the increasing amounts of data, and diverse effective neural network designs. However, it also brings a heavy computing burden as the amount of training data is proportional to the training time. In addition, a well-behaved model requires repeated trials of different structure designs and hyper-parameters, which may take a large amount of time even with state-of-the-art (SOTA) hyper-parameter optimization (HPO) algorithms and neural architecture search (NAS) algorithms. In this paper, we propose an Automatic Selection of Proxy dataset framework (ASP) aimed to dynamically find the informative proxy subsets of training data at each epoch, reducing the training data size as well as saving the AutoML processing time. We verify the effectiveness and generalization of ASP on CIFAR10, CIFAR100, ImageNet16-120, and ImageNet-1k, across various public model benchmarks. The experiment results show that ASP can obtain better results than other data selection methods at all selection ratios. ASP can also enable much more efficient AutoML processing with a speedup of 2x-20x while obtaining better architectures and better hyper-parameters compared to utilizing the entire dataset.
USDC: Unified Static and Dynamic Compression for Visual Transformer
Oct 17, 2023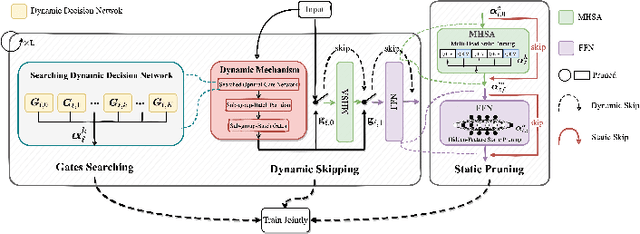
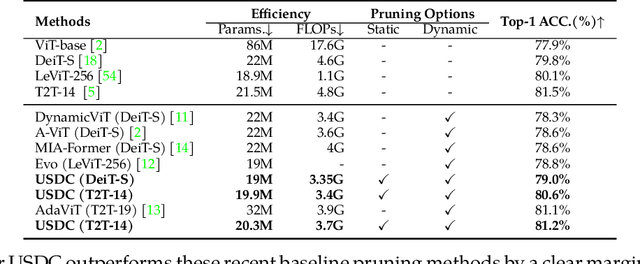
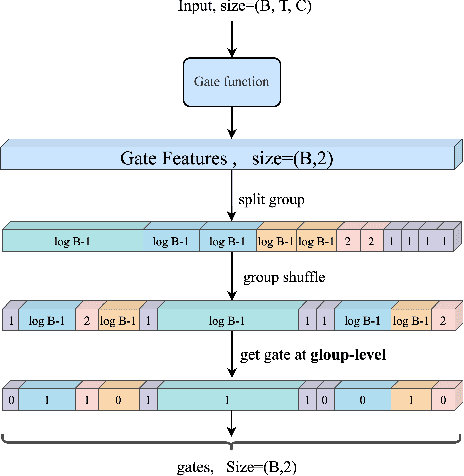
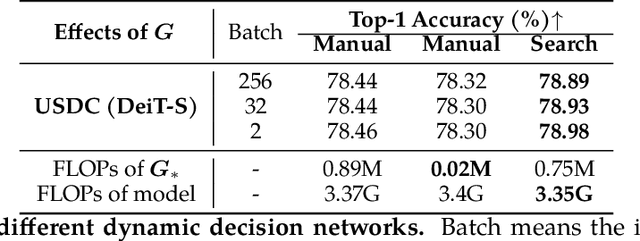
Visual Transformers have achieved great success in almost all vision tasks, such as classification, detection, and so on. However, the model complexity and the inference speed of the visual transformers hinder their deployments in industrial products. Various model compression techniques focus on directly compressing the visual transformers into a smaller one while maintaining the model performance, however, the performance drops dramatically when the compression ratio is large. Furthermore, several dynamic network techniques have also been applied to dynamically compress the visual transformers to obtain input-adaptive efficient sub-structures during the inference stage, which can achieve a better trade-off between the compression ratio and the model performance. The upper bound of memory of dynamic models is not reduced in the practical deployment since the whole original visual transformer model and the additional control gating modules should be loaded onto devices together for inference. To alleviate two disadvantages of two categories of methods, we propose to unify the static compression and dynamic compression techniques jointly to obtain an input-adaptive compressed model, which can further better balance the total compression ratios and the model performances. Moreover, in practical deployment, the batch sizes of the training and inference stage are usually different, which will cause the model inference performance to be worse than the model training performance, which is not touched by all previous dynamic network papers. We propose a sub-group gates augmentation technique to solve this performance drop problem. Extensive experiments demonstrate the superiority of our method on various baseline visual transformers such as DeiT, T2T-ViT, and so on.
FPTQ: Fine-grained Post-Training Quantization for Large Language Models
Aug 30, 2023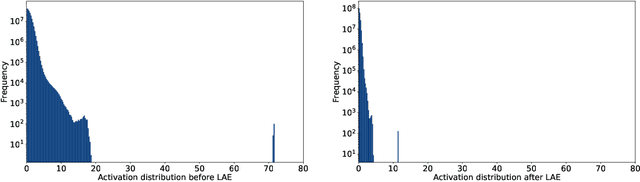



In the era of large-scale language models, the substantial parameter size poses significant challenges for deployment. Being a prevalent compression technique, quantization has emerged as the mainstream practice to tackle this issue, which is mainly centered on two recipes W8A8 and W4A16 (i.e. weights and activations in such bit widths). In this study, we propose a novel W4A8 post-training quantization method for the available open-sourced LLMs, which combines the advantages of both two recipes. Therefore, we can leverage the benefit in the I/O utilization of 4-bit weight quantization and the acceleration due to 8-bit matrix computation. Nevertheless, the W4A8 faces notorious performance degradation. As a remedy, we involve layerwise activation quantization strategies which feature a novel logarithmic equalization for most intractable layers, and we combine them with fine-grained weight quantization. Without whistles and bells, we eliminate the necessity for further fine-tuning and obtain the state-of-the-art W4A8 quantized performance on BLOOM, LLaMA, and LLaMA-2 on standard benchmarks. We confirm that the W4A8 quantization is achievable for the deployment of large language models, fostering their wide-spreading real-world applications.
MCPA: Multi-scale Cross Perceptron Attention Network for 2D Medical Image Segmentation
Jul 27, 2023The UNet architecture, based on Convolutional Neural Networks (CNN), has demonstrated its remarkable performance in medical image analysis. However, it faces challenges in capturing long-range dependencies due to the limited receptive fields and inherent bias of convolutional operations. Recently, numerous transformer-based techniques have been incorporated into the UNet architecture to overcome this limitation by effectively capturing global feature correlations. However, the integration of the Transformer modules may result in the loss of local contextual information during the global feature fusion process. To overcome these challenges, we propose a 2D medical image segmentation model called Multi-scale Cross Perceptron Attention Network (MCPA). The MCPA consists of three main components: an encoder, a decoder, and a Cross Perceptron. The Cross Perceptron first captures the local correlations using multiple Multi-scale Cross Perceptron modules, facilitating the fusion of features across scales. The resulting multi-scale feature vectors are then spatially unfolded, concatenated, and fed through a Global Perceptron module to model global dependencies. Furthermore, we introduce a Progressive Dual-branch Structure to address the semantic segmentation of the image involving finer tissue structures. This structure gradually shifts the segmentation focus of MCPA network training from large-scale structural features to more sophisticated pixel-level features. We evaluate our proposed MCPA model on several publicly available medical image datasets from different tasks and devices, including the open large-scale dataset of CT (Synapse), MRI (ACDC), fundus camera (DRIVE, CHASE_DB1, HRF), and OCTA (ROSE). The experimental results show that our MCPA model achieves state-of-the-art performance. The code is available at https://github.com/simonustc/MCPA-for-2D-Medical-Image-Segmentation.
Phased Progressive Learning with Coupling-Regulation-Imbalance Loss for Imbalanced Classification
May 24, 2022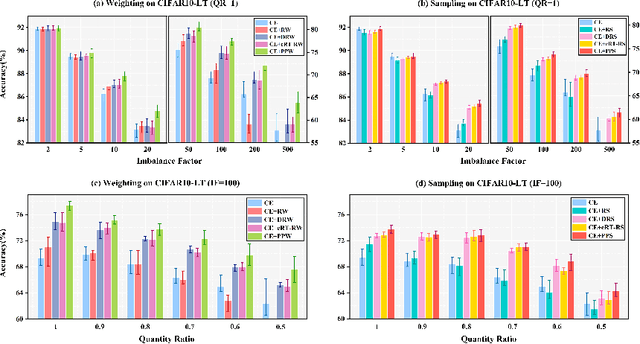
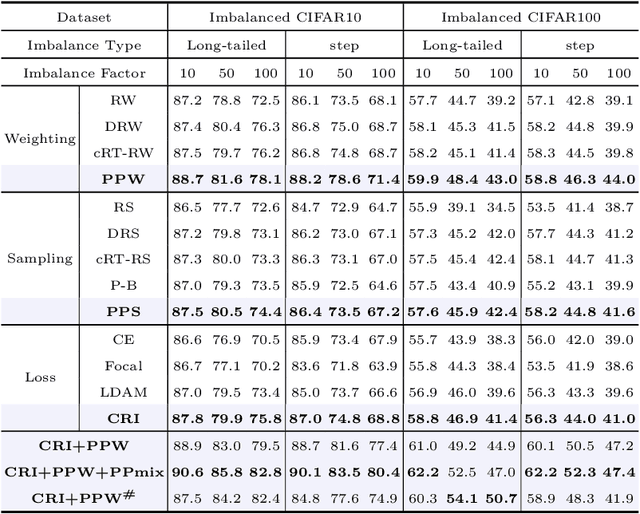
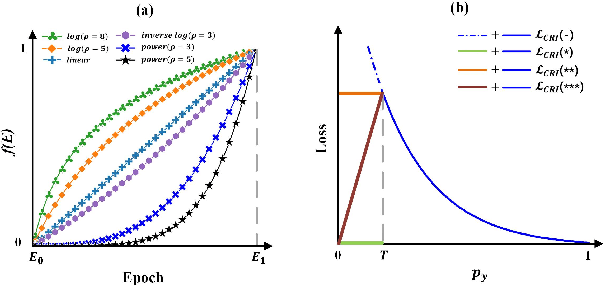
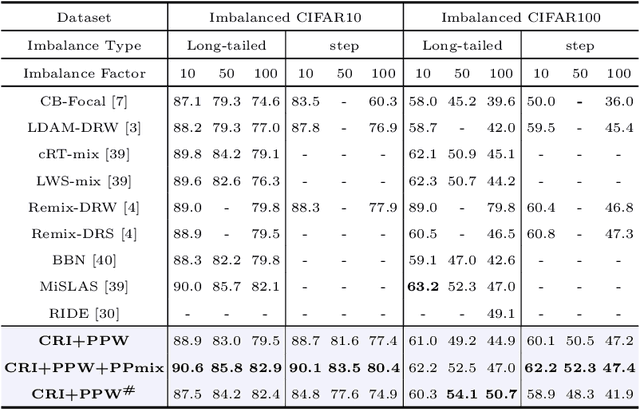
Deep neural networks generally perform poorly with datasets that suffer from quantity imbalance and classification difficulty imbalance between different classes. In order to alleviate the problem of dataset bias or domain shift in the existing two-stage approaches, a phased progressive learning schedule was proposed for smoothly transferring the training emphasis from representation learning to upper classifier training. This has greater effectivity on datasets that have more severe imbalances or smaller scales. A coupling-regulation-imbalance loss function was designed, coupling a correction term, Focal loss and LDAM loss. Coupling-regulation-imbalance loss can better deal with quantity imbalance and outliers, while regulating focus-of-attention of samples with a variety of classification difficulties. Excellent results were achieved on multiple benchmark datasets using these approaches and they can be easily generalized for other imbalanced classification models. Our code will be open source soon.
ProxyBO: Accelerating Neural Architecture Search via Bayesian Optimization with Zero-cost Proxies
Oct 26, 2021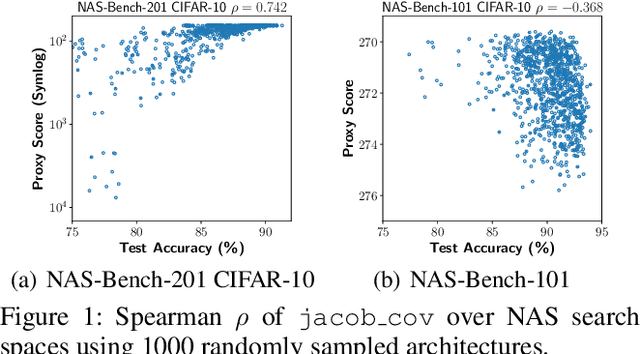
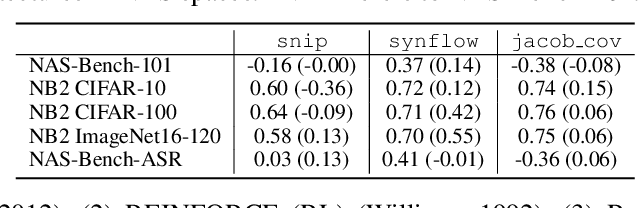
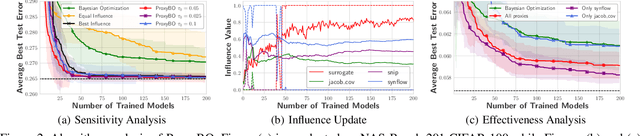
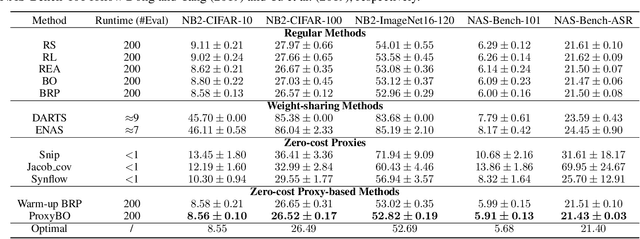
Designing neural architectures requires immense manual efforts. This has promoted the development of neural architecture search (NAS) to automate this design. While previous NAS methods achieve promising results but run slowly and zero-cost proxies run extremely fast but are less promising, recent work considers utilizing zero-cost proxies via a simple warm-up. The existing method has two limitations, which are unforeseeable reliability and one-shot usage. To address the limitations, we present ProxyBO, an efficient Bayesian optimization framework that utilizes the zero-cost proxies to accelerate neural architecture search. We propose the generalization ability measurement to estimate the fitness of proxies on the task during each iteration and then combine BO with zero-cost proxies via dynamic influence combination. Extensive empirical studies show that ProxyBO consistently outperforms competitive baselines on five tasks from three public benchmarks. Concretely, ProxyBO achieves up to 5.41x and 3.83x speedups over the state-of-the-art approach REA and BRP-NAS, respectively.
An explainable two-dimensional single model deep learning approach for Alzheimer's disease diagnosis and brain atrophy localization
Jul 28, 2021
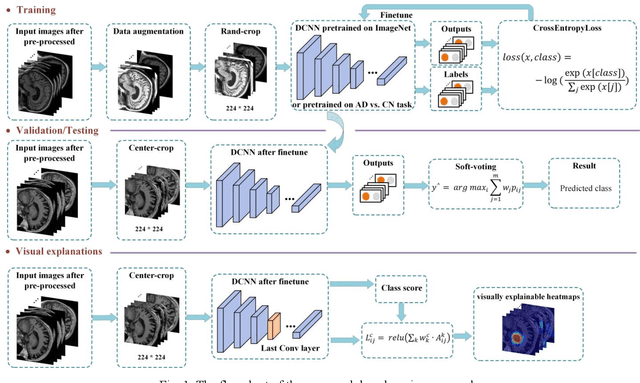


Early and accurate diagnosis of Alzheimer's disease (AD) and its prodromal period mild cognitive impairment (MCI) is essential for the delayed disease progression and the improved quality of patients'life. The emerging computer-aided diagnostic methods that combine deep learning with structural magnetic resonance imaging (sMRI) have achieved encouraging results, but some of them are limit of issues such as data leakage and unexplainable diagnosis. In this research, we propose a novel end-to-end deep learning approach for automated diagnosis of AD and localization of important brain regions related to the disease from sMRI data. This approach is based on a 2D single model strategy and has the following differences from the current approaches: 1) Convolutional Neural Network (CNN) models of different structures and capacities are evaluated systemically and the most suitable model is adopted for AD diagnosis; 2) a data augmentation strategy named Two-stage Random RandAugment (TRRA) is proposed to alleviate the overfitting issue caused by limited training data and to improve the classification performance in AD diagnosis; 3) an explainable method of Grad-CAM++ is introduced to generate the visually explainable heatmaps that localize and highlight the brain regions that our model focuses on and to make our model more transparent. Our approach has been evaluated on two publicly accessible datasets for two classification tasks of AD vs. cognitively normal (CN) and progressive MCI (pMCI) vs. stable MCI (sMCI). The experimental results indicate that our approach outperforms the state-of-the-art approaches, including those using multi-model and 3D CNN methods. The resultant localization heatmaps from our approach also highlight the lateral ventricle and some disease-relevant regions of cortex, coincident with the commonly affected regions during the development of AD.
Single Model Deep Learning on Imbalanced Small Datasets for Skin Lesion Classification
Feb 02, 2021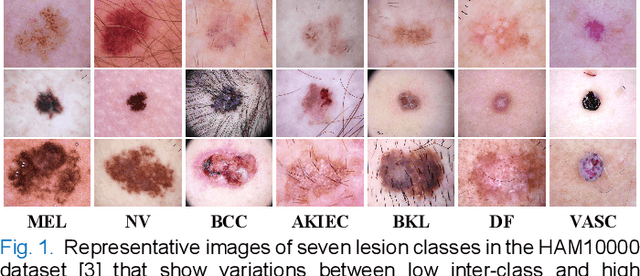
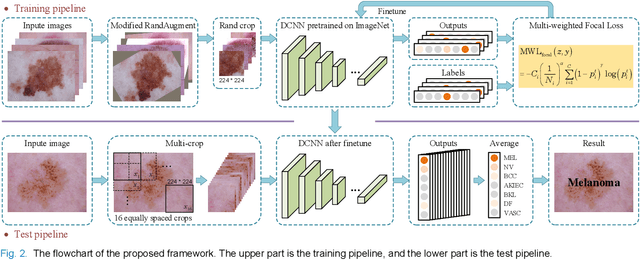
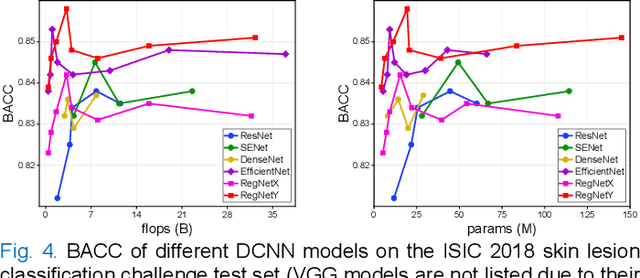
Deep convolutional neural network (DCNN) models have been widely explored for skin disease diagnosis and some of them have achieved the diagnostic outcomes comparable or even superior to those of dermatologists. However, broad implementation of DCNN in skin disease detection is hindered by small size and data imbalance of the publically accessible skin lesion datasets. This paper proposes a novel data augmentation strategy for single model classification of skin lesions based on a small and imbalanced dataset. First, various DCNNs are trained on this dataset to show that the models with moderate complexity outperform the larger models. Second, regularization DropOut and DropBlock are added to reduce overfitting and a Modified RandAugment augmentation strategy is proposed to address the defects of sample underrepresentation in the small dataset. Finally, a novel Multi-Weighted Focal Loss function is introduced to overcome the challenge of uneven sample size and classification difficulty. By combining Modified RandAugment and Multi-weighted Focal Loss in a single DCNN model, we have achieved the classification accuracy comparable to those of multiple ensembling models on the ISIC 2018 challenge test dataset. Our study shows that this method is able to achieve a high classification performance at a low cost of computational resources and inference time, potentially suitable to implement in mobile devices for automated screening of skin lesions and many other malignancies in low resource settings.