 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProc3D: Procedural 3D Generation and Parametric Editing of 3D Shapes with Large Language Models
Jan 18, 2026Generating 3D models has traditionally been a complex task requiring specialized expertise. While recent advances in generative AI have sought to automate this process, existing methods produce non-editable representation, such as meshes or point clouds, limiting their adaptability for iterative design. In this paper, we introduce Proc3D, a system designed to generate editable 3D models while enabling real-time modifications. At its core, Proc3D introduces procedural compact graph (PCG), a graph representation of 3D models, that encodes the algorithmic rules and structures necessary for generating the model. This representation exposes key parameters, allowing intuitive manual adjustments via sliders and checkboxes, as well as real-time, automated modifications through natural language prompts using Large Language Models (LLMs). We demonstrate Proc3D's capabilities using two generative approaches: GPT-4o with in-context learning (ICL) and a fine-tuned LLAMA-3 model. Experimental results show that Proc3D outperforms existing methods in editing efficiency, achieving more than 400x speedup over conventional approaches that require full regeneration for each modification. Additionally, Proc3D improves ULIP scores by 28%, a metric that evaluates the alignment between generated 3D models and text prompts. By enabling text-aligned 3D model generation along with precise, real-time parametric edits, Proc3D facilitates highly accurate text-based image editing applications.
PRISM: Learning Design Knowledge from Data for Stylistic Design Improvement
Jan 16, 2026Graphic design often involves exploring different stylistic directions, which can be time-consuming for non-experts. We address this problem of stylistically improving designs based on natural language instructions. While VLMs have shown initial success in graphic design, their pretrained knowledge on styles is often too general and misaligned with specific domain data. For example, VLMs may associate minimalism with abstract designs, whereas designers emphasize shape and color choices. Our key insight is to leverage design data -- a collection of real-world designs that implicitly capture designer's principles -- to learn design knowledge and guide stylistic improvement. We propose PRISM (PRior-Informed Stylistic Modification) that constructs and applies a design knowledge base through three stages: (1) clustering high-variance designs to capture diversity within a style, (2) summarizing each cluster into actionable design knowledge, and (3) retrieving relevant knowledge during inference to enable style-aware improvement. Experiments on the Crello dataset show that PRISM achieves the highest average rank of 1.49 (closer to 1 is better) over baselines in style alignment. User studies further validate these results, showing that PRISM is consistently preferred by designers.
Shape My Moves: Text-Driven Shape-Aware Synthesis of Human Motions
Apr 04, 2025



We explore how body shapes influence human motion synthesis, an aspect often overlooked in existing text-to-motion generation methods due to the ease of learning a homogenized, canonical body shape. However, this homogenization can distort the natural correlations between different body shapes and their motion dynamics. Our method addresses this gap by generating body-shape-aware human motions from natural language prompts. We utilize a finite scalar quantization-based variational autoencoder (FSQ-VAE) to quantize motion into discrete tokens and then leverage continuous body shape information to de-quantize these tokens back into continuous, detailed motion. Additionally, we harness the capabilities of a pretrained language model to predict both continuous shape parameters and motion tokens, facilitating the synthesis of text-aligned motions and decoding them into shape-aware motions. We evaluate our method quantitatively and qualitatively, and also conduct a comprehensive perceptual study to demonstrate its efficacy in generating shape-aware motions.
ScreenLLM: Stateful Screen Schema for Efficient Action Understanding and Prediction
Mar 26, 2025Graphical User Interface (GUI) agents are autonomous systems that interpret and generate actions, enabling intelligent user assistance and automation. Effective training of these agent presents unique challenges, such as sparsity in supervision signals, scalability for large datasets, and the need for nuanced user understanding. We propose stateful screen schema, an efficient representation of GUI interactions that captures key user actions and intentions over time. Building on this foundation, we introduce ScreenLLM, a set of multimodal large language models (MLLMs) tailored for advanced UI understanding and action prediction. Extensive experiments on both open-source and proprietary models show that ScreenLLM accurately models user behavior and predicts actions. Our work lays the foundation for scalable, robust, and intelligent GUI agents that enhance user interaction in diverse software environments.
AUKT: Adaptive Uncertainty-Guided Knowledge Transfer with Conformal Prediction
Feb 25, 2025Knowledge transfer between teacher and student models has proven effective across various machine learning applications. However, challenges arise when the teacher's predictions are noisy, or the data domain during student training shifts from the teacher's pretraining data. In such scenarios, blindly relying on the teacher's predictions can lead to suboptimal knowledge transfer. To address these challenges, we propose a novel and universal framework, Adaptive Uncertainty-guided Knowledge Transfer ($\textbf{AUKT}$), which leverages Conformal Prediction (CP) to dynamically adjust the student's reliance on the teacher's guidance based on the teacher's prediction uncertainty. CP is a distribution-free, model-agnostic approach that provides reliable prediction sets with statistical coverage guarantees and minimal computational overhead. This adaptive mechanism mitigates the risk of learning undesirable or incorrect knowledge. We validate the proposed framework across diverse applications, including image classification, imitation-guided reinforcement learning, and autonomous driving. Experimental results consistently demonstrate that our approach improves performance, robustness and transferability, offering a promising direction for enhanced knowledge transfer in real-world applications.
CAML: Collaborative Auxiliary Modality Learning for Multi-Agent Systems
Feb 25, 2025Multi-modality learning has become a crucial technique for improving the performance of machine learning applications across domains such as autonomous driving, robotics, and perception systems. While existing frameworks such as Auxiliary Modality Learning (AML) effectively utilize multiple data sources during training and enable inference with reduced modalities, they primarily operate in a single-agent context. This limitation is particularly critical in dynamic environments, such as connected autonomous vehicles (CAV), where incomplete data coverage can lead to decision-making blind spots. To address these challenges, we propose Collaborative Auxiliary Modality Learning ($\textbf{CAML}$), a novel multi-agent multi-modality framework that enables agents to collaborate and share multimodal data during training while allowing inference with reduced modalities per agent during testing. We systematically analyze the effectiveness of $\textbf{CAML}$ from the perspective of uncertainty reduction and data coverage, providing theoretical insights into its advantages over AML. Experimental results in collaborative decision-making for CAV in accident-prone scenarios demonstrate that \ours~achieves up to a ${\bf 58.13}\%$ improvement in accident detection. Additionally, we validate $\textbf{CAML}$ on real-world aerial-ground robot data for collaborative semantic segmentation, achieving up to a ${\bf 10.61}\%$ improvement in mIoU.
GUI-Bee: Align GUI Action Grounding to Novel Environments via Autonomous Exploration
Jan 27, 2025

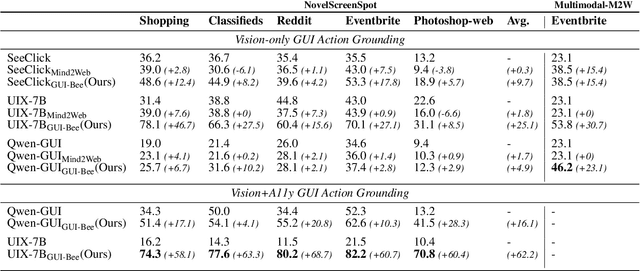

Graphical User Interface (GUI) action grounding is a critical step in GUI automation that maps language instructions to actionable elements on GUI screens. Most recent works of GUI action grounding leverage large GUI datasets to fine-tune MLLMs. However, the fine-tuning data always covers limited GUI environments, and we find the performance of the resulting model deteriorates in novel environments. We argue that the GUI grounding models should be further aligned to the novel environments to reveal their full potential, when the inference is known to involve novel environments, i.e., environments not used during the previous fine-tuning. To realize this, we first propose GUI-Bee, an MLLM-based autonomous agent, to collect high-quality, environment-specific data through exploration and then continuously fine-tune GUI grounding models with the collected data. Our agent leverages a novel Q-value-Incentive In-Context Reinforcement Learning (Q-ICRL) method to optimize exploration efficiency and data quality. Additionally, we introduce NovelScreenSpot, a benchmark for testing how well the data can help align GUI action grounding models to novel environments and demonstrate the effectiveness of data collected by GUI-Bee in the experiments. Furthermore, we conduct an ablation study to validate the Q-ICRL method in enhancing the efficiency of GUI-Bee. Project page: https://gui-bee.github.io
Sensitivity-Informed Augmentation for Robust Segmentation
Jun 04, 2024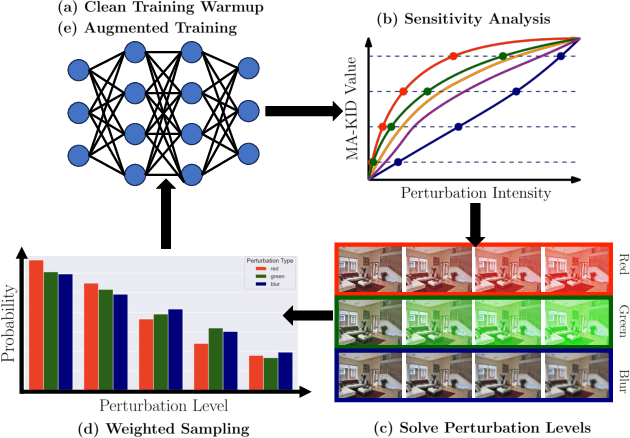
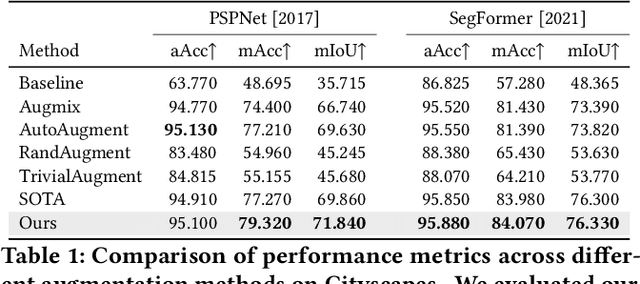
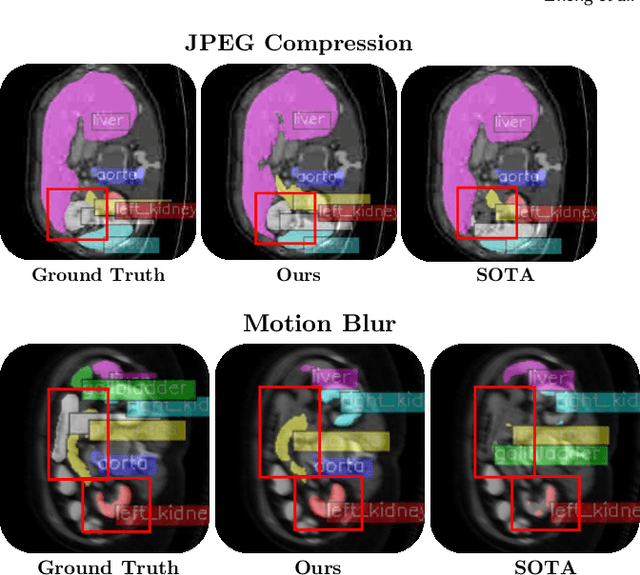
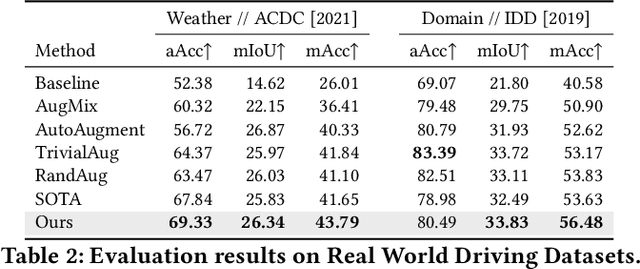
Segmentation is an integral module in many visual computing applications such as virtual try-on, medical imaging, autonomous driving, and agricultural automation. These applications often involve either widespread consumer use or highly variable environments, both of which can degrade the quality of visual sensor data, whether from a common mobile phone or an expensive satellite imaging camera. In addition to external noises like user difference or weather conditions, internal noises such as variations in camera quality or lens distortion can affect the performance of segmentation models during both development and deployment. In this work, we present an efficient, adaptable, and gradient-free method to enhance the robustness of learning-based segmentation models across training. First, we introduce a novel adaptive sensitivity analysis (ASA) using Kernel Inception Distance (KID) on basis perturbations to benchmark perturbation sensitivity of pre-trained segmentation models. Then, we model the sensitivity curve using the adaptive SA and sample perturbation hyperparameter values accordingly. Finally, we conduct adversarial training with the selected perturbation values and dynamically re-evaluate robustness during online training. Our method, implemented end-to-end with minimal fine-tuning required, consistently outperforms state-of-the-art data augmentation techniques for segmentation. It shows significant improvement in both clean data evaluation and real-world adverse scenario evaluation across various segmentation datasets used in visual computing and computer graphics applications.
SHARE: Single-view Human Adversarial REconstruction
Dec 30, 2023The accuracy of 3D Human Pose and Shape reconstruction (HPS) from an image is progressively improving. Yet, no known method is robust across all image distortion. To address issues due to variations of camera poses, we introduce SHARE, a novel fine-tuning method that utilizes adversarial data augmentation to enhance the robustness of existing HPS techniques. We perform a comprehensive analysis on the impact of camera poses on HPS reconstruction outcomes. We first generated large-scale image datasets captured systematically from diverse camera perspectives. We then established a mapping between camera poses and reconstruction errors as a continuous function that characterizes the relationship between camera poses and HPS quality. Leveraging this representation, we introduce RoME (Regions of Maximal Error), a novel sampling technique for our adversarial fine-tuning method. The SHARE framework is generalizable across various single-view HPS methods and we demonstrate its performance on HMR, SPIN, PARE, CLIFF and ExPose. Our results illustrate a reduction in mean joint errors across single-view HPS techniques, for images captured from multiple camera positions without compromising their baseline performance. In many challenging cases, our method surpasses the performance of existing models, highlighting its practical significance for diverse real-world applications.
Collaborative Decision-Making Using Spatiotemporal Graphs in Connected Autonomy
Oct 31, 2023



Collaborative decision-making is an essential capability for multi-robot systems, such as connected vehicles, to collaboratively control autonomous vehicles in accident-prone scenarios. Under limited communication bandwidth, capturing comprehensive situational awareness by integrating connected agents' observation is very challenging. In this paper, we propose a novel collaborative decision-making method that efficiently and effectively integrates collaborators' representations to control the ego vehicle in accident-prone scenarios. Our approach formulates collaborative decision-making as a classification problem. We first represent sequences of raw observations as spatiotemporal graphs, which significantly reduce the package size to share among connected vehicles. Then we design a novel spatiotemporal graph neural network based on heterogeneous graph learning, which analyzes spatial and temporal connections of objects in a unified way for collaborative decision-making. We evaluate our approach using a high-fidelity simulator that considers realistic traffic, communication bandwidth, and vehicle sensing among connected autonomous vehicles. The experimental results show that our representation achieves over 100x reduction in the shared data size that meets the requirements of communication bandwidth for connected autonomous driving. In addition, our approach achieves over 30% improvements in driving safety.