 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards General and Efficient Online Tuning for Spark
Sep 05, 2023The distributed data analytic system -- Spark is a common choice for processing massive volumes of heterogeneous data, while it is challenging to tune its parameters to achieve high performance. Recent studies try to employ auto-tuning techniques to solve this problem but suffer from three issues: limited functionality, high overhead, and inefficient search. In this paper, we present a general and efficient Spark tuning framework that can deal with the three issues simultaneously. First, we introduce a generalized tuning formulation, which can support multiple tuning goals and constraints conveniently, and a Bayesian optimization (BO) based solution to solve this generalized optimization problem. Second, to avoid high overhead from additional offline evaluations in existing methods, we propose to tune parameters along with the actual periodic executions of each job (i.e., online evaluations). To ensure safety during online job executions, we design a safe configuration acquisition method that models the safe region. Finally, three innovative techniques are leveraged to further accelerate the search process: adaptive sub-space generation, approximate gradient descent, and meta-learning method. We have implemented this framework as an independent cloud service, and applied it to the data platform in Tencent. The empirical results on both public benchmarks and large-scale production tasks demonstrate its superiority in terms of practicality, generality, and efficiency. Notably, this service saves an average of 57.00% memory cost and 34.93% CPU cost on 25K in-production tasks within 20 iterations, respectively.
OpenBox: A Python Toolkit for Generalized Black-box Optimization
Apr 26, 2023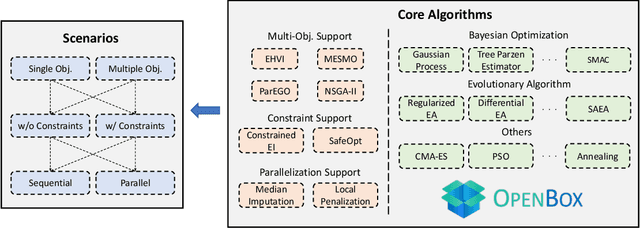

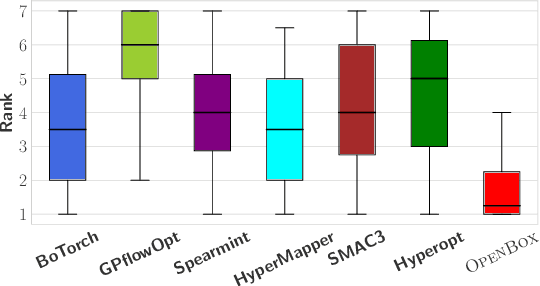
Black-box optimization (BBO) has a broad range of applications, including automatic machine learning, experimental design, and database knob tuning. However, users still face challenges when applying BBO methods to their problems at hand with existing software packages in terms of applicability, performance, and efficiency. This paper presents OpenBox, an open-source BBO toolkit with improved usability. It implements user-friendly inferfaces and visualization for users to define and manage their tasks. The modular design behind OpenBox facilitates its flexible deployment in existing systems. Experimental results demonstrate the effectiveness and efficiency of OpenBox over existing systems. The source code of OpenBox is available at https://github.com/PKU-DAIR/open-box.
Rover: An online Spark SQL tuning service via generalized transfer learning
Feb 08, 2023



Distributed data analytic engines like Spark are common choices to process massive data in industry. However, the performance of Spark SQL highly depends on the choice of configurations, where the optimal ones vary with the executed workloads. Among various alternatives for Spark SQL tuning, Bayesian optimization (BO) is a popular framework that finds near-optimal configurations given sufficient budget, but it suffers from the re-optimization issue and is not practical in real production. When applying transfer learning to accelerate the tuning process, we notice two domain-specific challenges: 1) most previous work focus on transferring tuning history, while expert knowledge from Spark engineers is of great potential to improve the tuning performance but is not well studied so far; 2) history tasks should be carefully utilized, where using dissimilar ones lead to a deteriorated performance in production. In this paper, we present Rover, a deployed online Spark SQL tuning service for efficient and safe search on industrial workloads. To address the challenges, we propose generalized transfer learning to boost the tuning performance based on external knowledge, including expert-assisted Bayesian optimization and controlled history transfer. Experiments on public benchmarks and real-world tasks show the superiority of Rover over competitive baselines. Notably, Rover saves an average of 50.1% of the memory cost on 12k real-world Spark SQL tasks in 20 iterations, among which 76.2% of the tasks achieve a significant memory reduction of over 60%.
TransBO: Hyperparameter Optimization via Two-Phase Transfer Learning
Jun 06, 2022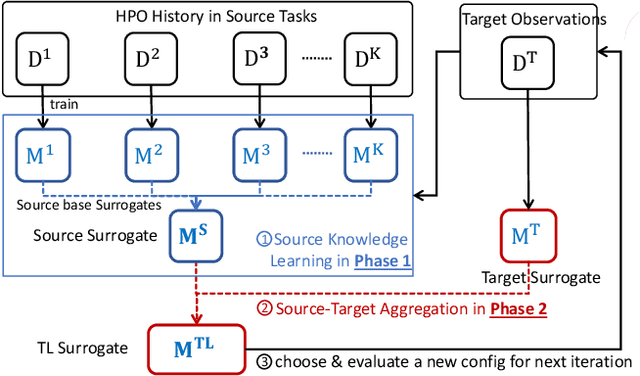



With the extensive applications of machine learning models, automatic hyperparameter optimization (HPO) has become increasingly important. Motivated by the tuning behaviors of human experts, it is intuitive to leverage auxiliary knowledge from past HPO tasks to accelerate the current HPO task. In this paper, we propose TransBO, a novel two-phase transfer learning framework for HPO, which can deal with the complementary nature among source tasks and dynamics during knowledge aggregation issues simultaneously. This framework extracts and aggregates source and target knowledge jointly and adaptively, where the weights can be learned in a principled manner. The extensive experiments, including static and dynamic transfer learning settings and neural architecture search, demonstrate the superiority of TransBO over the state-of-the-arts.
* 9 pages and 2 extra pages of appendix
Transfer Learning based Search Space Design for Hyperparameter Tuning
Jun 06, 2022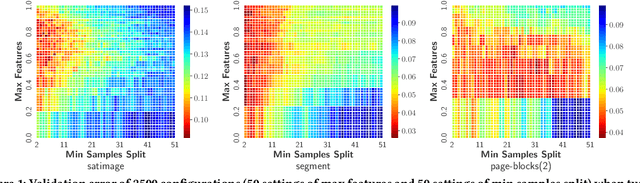



The tuning of hyperparameters becomes increasingly important as machine learning (ML) models have been extensively applied in data mining applications. Among various approaches, Bayesian optimization (BO) is a successful methodology to tune hyper-parameters automatically. While traditional methods optimize each tuning task in isolation, there has been recent interest in speeding up BO by transferring knowledge across previous tasks. In this work, we introduce an automatic method to design the BO search space with the aid of tuning history from past tasks. This simple yet effective approach can be used to endow many existing BO methods with transfer learning capabilities. In addition, it enjoys the three advantages: universality, generality, and safeness. The extensive experiments show that our approach considerably boosts BO by designing a promising and compact search space instead of using the entire space, and outperforms the state-of-the-arts on a wide range of benchmarks, including machine learning and deep learning tuning tasks, and neural architecture search.
* 9 pages and 2 extra pages for appendix
Hyper-Tune: Towards Efficient Hyper-parameter Tuning at Scale
Jan 18, 2022


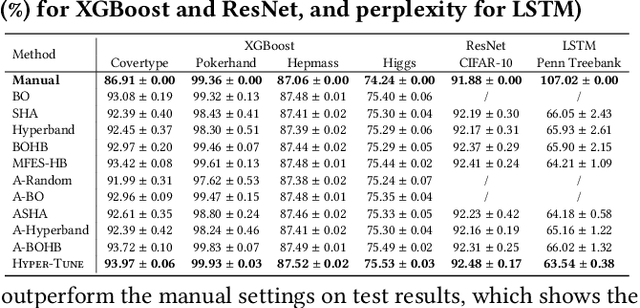
The ever-growing demand and complexity of machine learning are putting pressure on hyper-parameter tuning systems: while the evaluation cost of models continues to increase, the scalability of state-of-the-arts starts to become a crucial bottleneck. In this paper, inspired by our experience when deploying hyper-parameter tuning in a real-world application in production and the limitations of existing systems, we propose Hyper-Tune, an efficient and robust distributed hyper-parameter tuning framework. Compared with existing systems, Hyper-Tune highlights multiple system optimizations, including (1) automatic resource allocation, (2) asynchronous scheduling, and (3) multi-fidelity optimizer. We conduct extensive evaluations on benchmark datasets and a large-scale real-world dataset in production. Empirically, with the aid of these optimizations, Hyper-Tune outperforms competitive hyper-parameter tuning systems on a wide range of scenarios, including XGBoost, CNN, RNN, and some architectural hyper-parameters for neural networks. Compared with the state-of-the-art BOHB and A-BOHB, Hyper-Tune achieves up to 11.2x and 5.1x speedups, respectively.
Automated Hyperparameter Optimization Challenge at CIKM 2021 AnalyticCup
Oct 31, 2021
In this paper, we describe our method for tackling the automated hyperparameter optimization challenge in QQ Browser 2021 AI Algorithm Competiton (ACM CIKM 2021 AnalyticCup Track 2). The competition organizers provide anonymized realistic industrial tasks and datasets for black-box optimization. Based on our open-sourced package OpenBox, we adopt the Bayesian optimization framework for configuration sampling and a heuristic early stopping strategy. We won first place in both the preliminary and final contests with the results of 0.938291 and 0.918753, respectively.
OpenBox: A Generalized Black-box Optimization Service
Jun 06, 2021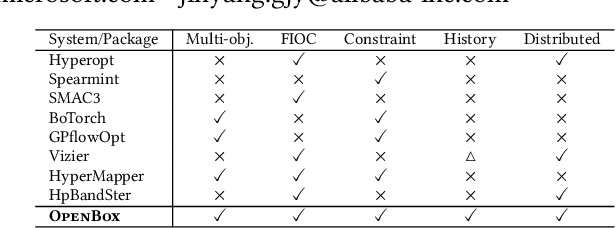

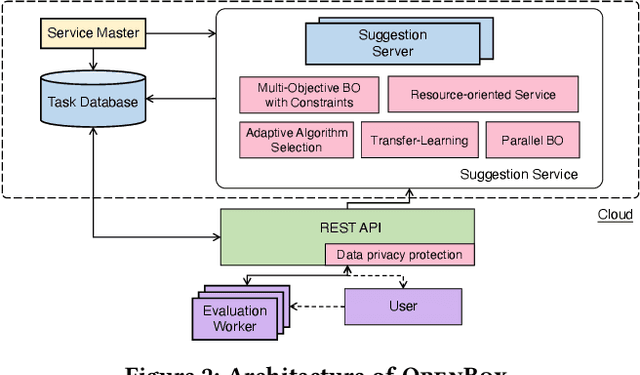

Black-box optimization (BBO) has a broad range of applications, including automatic machine learning, engineering, physics, and experimental design. However, it remains a challenge for users to apply BBO methods to their problems at hand with existing software packages, in terms of applicability, performance, and efficiency. In this paper, we build OpenBox, an open-source and general-purpose BBO service with improved usability. The modular design behind OpenBox also facilitates flexible abstraction and optimization of basic BBO components that are common in other existing systems. OpenBox is distributed, fault-tolerant, and scalable. To improve efficiency, OpenBox further utilizes "algorithm agnostic" parallelization and transfer learning. Our experimental results demonstrate the effectiveness and efficiency of OpenBox compared to existing systems.