 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyper-Tune: Towards Efficient Hyper-parameter Tuning at Scale
Paper and Code



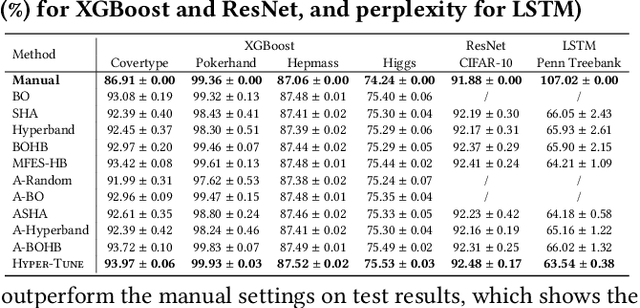
The ever-growing demand and complexity of machine learning are putting pressure on hyper-parameter tuning systems: while the evaluation cost of models continues to increase, the scalability of state-of-the-arts starts to become a crucial bottleneck. In this paper, inspired by our experience when deploying hyper-parameter tuning in a real-world application in production and the limitations of existing systems, we propose Hyper-Tune, an efficient and robust distributed hyper-parameter tuning framework. Compared with existing systems, Hyper-Tune highlights multiple system optimizations, including (1) automatic resource allocation, (2) asynchronous scheduling, and (3) multi-fidelity optimizer. We conduct extensive evaluations on benchmark datasets and a large-scale real-world dataset in production. Empirically, with the aid of these optimizations, Hyper-Tune outperforms competitive hyper-parameter tuning systems on a wide range of scenarios, including XGBoost, CNN, RNN, and some architectural hyper-parameters for neural networks. Compared with the state-of-the-art BOHB and A-BOHB, Hyper-Tune achieves up to 11.2x and 5.1x speedups, respectively.