 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoFEH: LLM-driven Feature Engineering Empowered by Collaborative Bayesian Hyperparameter Optimization
Feb 10, 2026Feature Engineering (FE) is pivotal in automated machine learning (AutoML) but remains a bottleneck for traditional methods, which treat it as a black-box search, operating within rigid, predefined search spaces and lacking domain awareness. While Large Language Models (LLMs) offer a promising alternative by leveraging semantic reasoning to generate unbounded operators, existing methods fail to construct free-form FE pipelines, remaining confined to isolated subtasks such as feature generation. Most importantly, they are rarely optimized jointly with hyperparameter optimization (HPO) of the ML model, leading to greedy "FE-then-HPO" workflows that cannot capture strong FE-HPO interactions. In this paper, we present CoFEH, a collaborative framework that interleaves LLM-based FE and Bayesian HPO for robust end-to-end AutoML. CoFEH uses an LLM-driven FE optimizer powered by Tree of Thought (ToT) to explore flexible FE pipelines, a Bayesian optimization (BO) module to solve HPO, and a dynamic optimizer selector that realizes interleaved optimization by adaptively scheduling FE and HPO steps. Crucially, we introduce a mutual conditioning mechanism that shares context between LLM and BO, enabling mutually informed decisions. Experiments show that CoFEH not only outperforms traditional and LLM-based FE baselines, but also achieves superior end-to-end performance under joint optimization.
LB-MCTS: Synergizing Large Language Models and Bayesian Optimization for Efficient CASH
Jan 18, 2026To lower the expertise barrier in machine learning, the AutoML community has focused on the CASH problem, a fundamental challenge that automates the process of algorithm selection and hyperparameter tuning. While traditional methods like Bayesian Optimization (BO) struggle with cold-start issues, Large Language Models (LLMs) can mitigate these via semantic priors. However, existing LLM-based optimizers generalize poorly to the high-dimensional, structured CASH space. We propose LB-MCTS, a framework synergizing LLMs and BO within a Monte Carlo Tree Search structure. It maximizes LLM reasoning with Selective Tuning Memory (STM) and explicit exploration-exploitation trade-off. It combines the strengths of both paradigms by dynamically shifting from LLM-driven to BO-driven proposals as data accumulates. Experiments on 104 AMLB datasets demonstrate the superiority of LB-MCTS over the competitive baselines.
PSEO: Optimizing Post-hoc Stacking Ensemble Through Hyperparameter Tuning
Aug 07, 2025The Combined Algorithm Selection and Hyperparameter Optimization (CASH) problem is fundamental in Automated Machine Learning (AutoML). Inspired by the success of ensemble learning, recent AutoML systems construct post-hoc ensembles for final predictions rather than relying on the best single model. However, while most CASH methods conduct extensive searches for the optimal single model, they typically employ fixed strategies during the ensemble phase that fail to adapt to specific task characteristics. To tackle this issue, we propose PSEO, a framework for post-hoc stacking ensemble optimization. First, we conduct base model selection through binary quadratic programming, with a trade-off between diversity and performance. Furthermore, we introduce two mechanisms to fully realize the potential of multi-layer stacking. Finally, PSEO builds a hyperparameter space and searches for the optimal post-hoc ensemble strategy within it. Empirical results on 80 public datasets show that \sys achieves the best average test rank (2.96) among 16 methods, including post-hoc designs in recent AutoML systems and state-of-the-art ensemble learning methods.
Rover: An online Spark SQL tuning service via generalized transfer learning
Feb 08, 2023



Distributed data analytic engines like Spark are common choices to process massive data in industry. However, the performance of Spark SQL highly depends on the choice of configurations, where the optimal ones vary with the executed workloads. Among various alternatives for Spark SQL tuning, Bayesian optimization (BO) is a popular framework that finds near-optimal configurations given sufficient budget, but it suffers from the re-optimization issue and is not practical in real production. When applying transfer learning to accelerate the tuning process, we notice two domain-specific challenges: 1) most previous work focus on transferring tuning history, while expert knowledge from Spark engineers is of great potential to improve the tuning performance but is not well studied so far; 2) history tasks should be carefully utilized, where using dissimilar ones lead to a deteriorated performance in production. In this paper, we present Rover, a deployed online Spark SQL tuning service for efficient and safe search on industrial workloads. To address the challenges, we propose generalized transfer learning to boost the tuning performance based on external knowledge, including expert-assisted Bayesian optimization and controlled history transfer. Experiments on public benchmarks and real-world tasks show the superiority of Rover over competitive baselines. Notably, Rover saves an average of 50.1% of the memory cost on 12k real-world Spark SQL tasks in 20 iterations, among which 76.2% of the tasks achieve a significant memory reduction of over 60%.
DivBO: Diversity-aware CASH for Ensemble Learning
Feb 07, 2023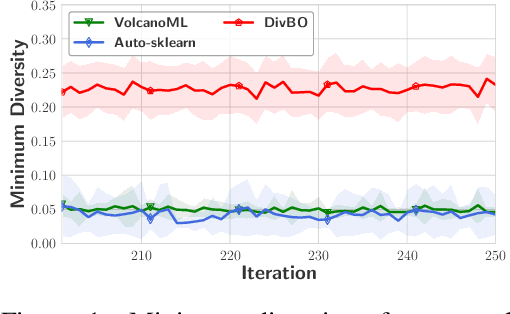
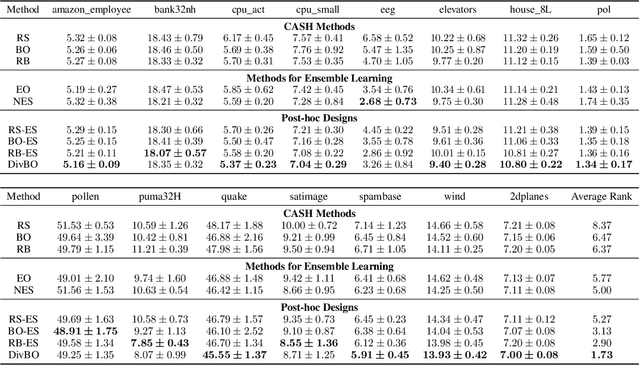
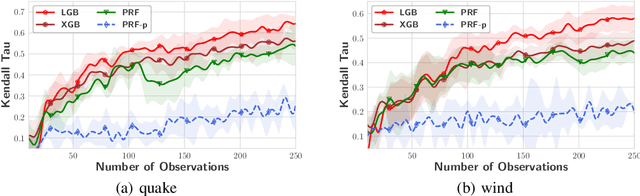

The Combined Algorithm Selection and Hyperparameters optimization (CASH) problem is one of the fundamental problems in Automated Machine Learning (AutoML). Motivated by the success of ensemble learning, recent AutoML systems build post-hoc ensembles to output the final predictions instead of using the best single learner. However, while most CASH methods focus on searching for a single learner with the best performance, they neglect the diversity among base learners (i.e., they may suggest similar configurations to previously evaluated ones), which is also a crucial consideration when building an ensemble. To tackle this issue and further enhance the ensemble performance, we propose DivBO, a diversity-aware framework to inject explicit search of diversity into the CASH problems. In the framework, we propose to use a diversity surrogate to predict the pair-wise diversity of two unseen configurations. Furthermore, we introduce a temporary pool and a weighted acquisition function to guide the search of both performance and diversity based on Bayesian optimization. Empirical results on 15 public datasets show that DivBO achieves the best average ranks (1.82 and 1.73) on both validation and test errors among 10 compared methods, including post-hoc designs in recent AutoML systems and state-of-the-art baselines for ensemble learning on CASH problems.