 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards LLM Agents for Earth Observation
Apr 16, 2025Earth Observation (EO) provides critical planetary data for environmental monitoring, disaster management, climate science, and other scientific domains. Here we ask: Are AI systems ready for reliable Earth Observation? We introduce \datasetnamenospace, a benchmark of 140 yes/no questions from NASA Earth Observatory articles across 13 topics and 17 satellite sensors. Using Google Earth Engine API as a tool, LLM agents can only achieve an accuracy of 33% because the code fails to run over 58% of the time. We improve the failure rate for open models by fine-tuning synthetic data, allowing much smaller models (Llama-3.1-8B) to achieve comparable accuracy to much larger ones (e.g., DeepSeek-R1). Taken together, our findings identify significant challenges to be solved before AI agents can automate earth observation, and suggest paths forward. The project page is available at https://iandrover.github.io/UnivEarth.
Scale-Aware Recognition in Satellite Images under Resource Constraint
Oct 31, 2024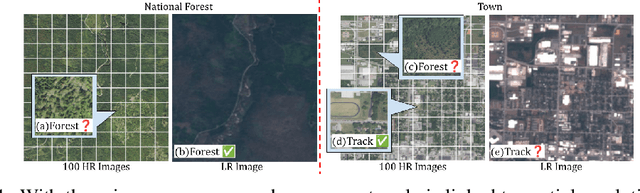



Recognition of features in satellite imagery (forests, swimming pools, etc.) depends strongly on the spatial scale of the concept and therefore the resolution of the images. This poses two challenges: Which resolution is best suited for recognizing a given concept, and where and when should the costlier higher-resolution (HR) imagery be acquired? We present a novel scheme to address these challenges by introducing three components: (1) A technique to distill knowledge from models trained on HR imagery to recognition models that operate on imagery of lower resolution (LR), (2) a sampling strategy for HR imagery based on model disagreement, and (3) an LLM-based approach for inferring concept "scale". With these components we present a system to efficiently perform scale-aware recognition in satellite imagery, improving accuracy over single-scale inference while following budget constraints. Our novel approach offers up to a 26.3% improvement over entirely HR baselines, using 76.3% fewer HR images.
Sensitivity-Informed Augmentation for Robust Segmentation
Jun 04, 2024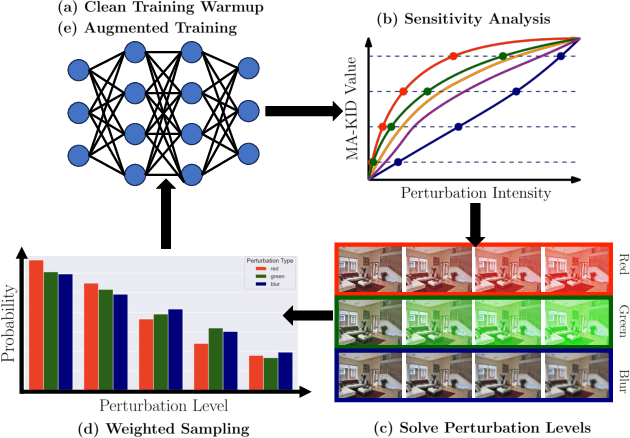
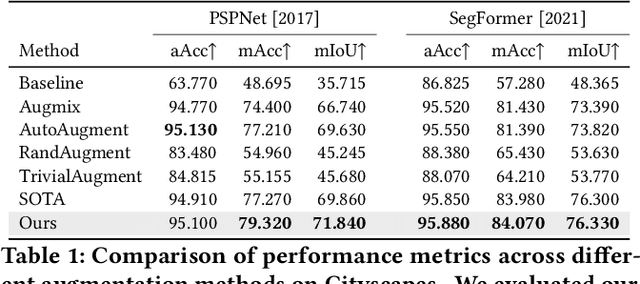
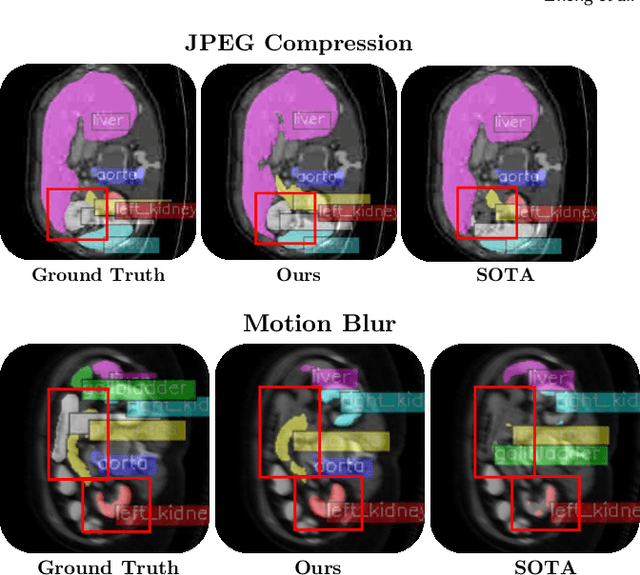
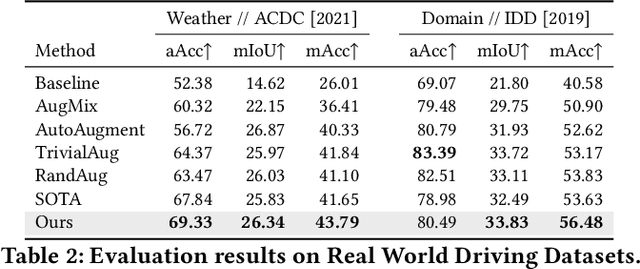
Segmentation is an integral module in many visual computing applications such as virtual try-on, medical imaging, autonomous driving, and agricultural automation. These applications often involve either widespread consumer use or highly variable environments, both of which can degrade the quality of visual sensor data, whether from a common mobile phone or an expensive satellite imaging camera. In addition to external noises like user difference or weather conditions, internal noises such as variations in camera quality or lens distortion can affect the performance of segmentation models during both development and deployment. In this work, we present an efficient, adaptable, and gradient-free method to enhance the robustness of learning-based segmentation models across training. First, we introduce a novel adaptive sensitivity analysis (ASA) using Kernel Inception Distance (KID) on basis perturbations to benchmark perturbation sensitivity of pre-trained segmentation models. Then, we model the sensitivity curve using the adaptive SA and sample perturbation hyperparameter values accordingly. Finally, we conduct adversarial training with the selected perturbation values and dynamically re-evaluate robustness during online training. Our method, implemented end-to-end with minimal fine-tuning required, consistently outperforms state-of-the-art data augmentation techniques for segmentation. It shows significant improvement in both clean data evaluation and real-world adverse scenario evaluation across various segmentation datasets used in visual computing and computer graphics applications.
SHARE: Single-view Human Adversarial REconstruction
Dec 30, 2023The accuracy of 3D Human Pose and Shape reconstruction (HPS) from an image is progressively improving. Yet, no known method is robust across all image distortion. To address issues due to variations of camera poses, we introduce SHARE, a novel fine-tuning method that utilizes adversarial data augmentation to enhance the robustness of existing HPS techniques. We perform a comprehensive analysis on the impact of camera poses on HPS reconstruction outcomes. We first generated large-scale image datasets captured systematically from diverse camera perspectives. We then established a mapping between camera poses and reconstruction errors as a continuous function that characterizes the relationship between camera poses and HPS quality. Leveraging this representation, we introduce RoME (Regions of Maximal Error), a novel sampling technique for our adversarial fine-tuning method. The SHARE framework is generalizable across various single-view HPS methods and we demonstrate its performance on HMR, SPIN, PARE, CLIFF and ExPose. Our results illustrate a reduction in mean joint errors across single-view HPS techniques, for images captured from multiple camera positions without compromising their baseline performance. In many challenging cases, our method surpasses the performance of existing models, highlighting its practical significance for diverse real-world applications.
Towards Driving Policies with Personality: Modeling Behavior and Style in Risky Scenarios via Data Collection in Virtual Reality
Mar 08, 2023Autonomous driving research currently faces data sparsity in representation of risky scenarios. Such data is both difficult to obtain ethically in the real world, and unreliable to obtain via simulation. Recent advances in virtual reality (VR) driving simulators lower barriers to tackling this problem in simulation. We propose the first data collection framework for risky scenario driving data from real humans using VR, as well as accompanying numerical driving personality characterizations. We validate the resulting dataset with statistical analyses and model driving behavior with an eight-factor personality vector based on the Multi-dimensional Driving Style Inventory (MDSI). Our method, dataset, and analyses show that realistic driving personalities can be modeled without deep learning or large datasets to complement autonomous driving research.