 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Soft Robotic Interface for Chick-Robot Affective Interactions
Apr 09, 2026The potential of Animal-Robot Interaction (ARI) in welfare applications depends on how much an animal perceives a robotic agent as socially relevant, non-threatening and potentially attractive (acceptance). Here, we present an animal-centered soft robotic affective interface for newly hatched chicks (Gallus gallus). The soft interface provides safe and controllable cues, including warmth, breathing-like rhythmic deformation, and face-like visual stimuli. We evaluated chick acceptance of the interface and chick-robot interactions by measuring spontaneous approach and touch responses during video tracking. Overall, chicks approached and spent increasing time on or near the interface, demonstrating acceptance of the device. Across different layouts, chicks showed strong preference for warm thermal stimulation, which increased over time. Face-like visual cues elicited a swift and stable preference, speeding up the initial approach to the tactile interface. Although the breathing cue did not elicit any preference, neither did it trigger avoidance, paving the way for further exploration. These findings translate affective interface concepts to ARI, demonstrating that appropriate soft, thermal and visual stimuli can sustain early chick-robot interactions. This work establishes a reliable evaluation protocol and a safe baseline for designing multimodal robotic devices for animal welfare and neuroscientific research.
DVGBench: Implicit-to-Explicit Visual Grounding Benchmark in UAV Imagery with Large Vision-Language Models
Jan 02, 2026Remote sensing (RS) large vision-language models (LVLMs) have shown strong promise across visual grounding (VG) tasks. However, existing RS VG datasets predominantly rely on explicit referring expressions-such as relative position, relative size, and color cues-thereby constraining performance on implicit VG tasks that require scenario-specific domain knowledge. This article introduces DVGBench, a high-quality implicit VG benchmark for drones, covering six major application scenarios: traffic, disaster, security, sport, social activity, and productive activity. Each object provides both explicit and implicit queries. Based on the dataset, we design DroneVG-R1, an LVLM that integrates the novel Implicit-to-Explicit Chain-of-Thought (I2E-CoT) within a reinforcement learning paradigm. This enables the model to take advantage of scene-specific expertise, converting implicit references into explicit ones and thus reducing grounding difficulty. Finally, an evaluation of mainstream models on both explicit and implicit VG tasks reveals substantial limitations in their reasoning capabilities. These findings provide actionable insights for advancing the reasoning capacity of LVLMs for drone-based agents. The code and datasets will be released at https://github.com/zytx121/DVGBench
Two Heads are Better than One: Distilling Large Language Model Features Into Small Models with Feature Decomposition and Mixture
Nov 11, 2025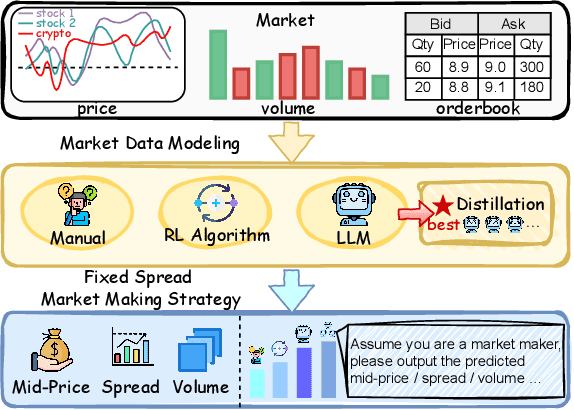

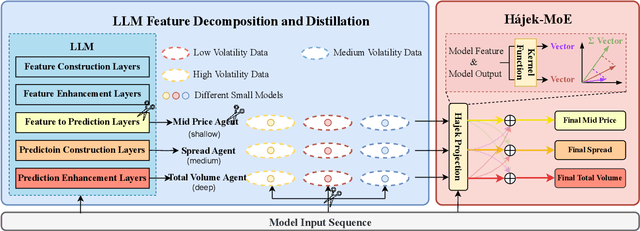

Market making (MM) through Reinforcement Learning (RL) has attracted significant attention in financial trading. With the development of Large Language Models (LLMs), more and more attempts are being made to apply LLMs to financial areas. A simple, direct application of LLM as an agent shows significant performance. Such methods are hindered by their slow inference speed, while most of the current research has not studied LLM distillation for this specific task. To address this, we first propose the normalized fluorescent probe to study the mechanism of the LLM's feature. Based on the observation found by our investigation, we propose Cooperative Market Making (CMM), a novel framework that decouples LLM features across three orthogonal dimensions: layer, task, and data. Various student models collaboratively learn simple LLM features along with different dimensions, with each model responsible for a distinct feature to achieve knowledge distillation. Furthermore, CMM introduces an Hájek-MoE to integrate the output of the student models by investigating the contribution of different models in a kernel function-generated common feature space. Extensive experimental results on four real-world market datasets demonstrate the superiority of CMM over the current distillation method and RL-based market-making strategies.
RL-PLUS: Countering Capability Boundary Collapse of LLMs in Reinforcement Learning with Hybrid-policy Optimization
Jul 31, 2025Reinforcement Learning with Verifiable Reward (RLVR) has significantly advanced the complex reasoning abilities of Large Language Models (LLMs). However, it struggles to break through the inherent capability boundaries of the base LLM, due to its inherently on-policy strategy with LLM's immense action space and sparse reward. Further, RLVR can lead to the capability boundary collapse, narrowing the LLM's problem-solving scope. To address this problem, we propose RL-PLUS, a novel approach that synergizes internal exploitation (i.e., Thinking) with external data (i.e., Learning) to achieve stronger reasoning capabilities and surpass the boundaries of base models. RL-PLUS integrates two core components: Multiple Importance Sampling to address for distributional mismatch from external data, and an Exploration-Based Advantage Function to guide the model towards high-value, unexplored reasoning paths. We provide both theoretical analysis and extensive experiments to demonstrate the superiority and generalizability of our approach. The results show that RL-PLUS achieves state-of-the-art performance compared with existing RLVR methods on six math reasoning benchmarks and exhibits superior performance on six out-of-distribution reasoning tasks. It also achieves consistent and significant gains across diverse model families, with average relative improvements ranging from 21.1\% to 69.2\%. Moreover, Pass@k curves across multiple benchmarks indicate that RL-PLUS effectively resolves the capability boundary collapse problem.
Thinking Longer, Not Larger: Enhancing Software Engineering Agents via Scaling Test-Time Compute
Mar 31, 2025Recent advancements in software engineering agents have demonstrated promising capabilities in automating program improvements. However, their reliance on closed-source or resource-intensive models introduces significant deployment challenges in private environments, prompting a critical question: \textit{How can personally deployable open-source LLMs achieve comparable code reasoning performance?} To this end, we propose a unified Test-Time Compute scaling framework that leverages increased inference-time computation instead of larger models. Our framework incorporates two complementary strategies: internal TTC and external TTC. Internally, we introduce a \textit{development-contextualized trajectory synthesis} method leveraging real-world software repositories to bootstrap multi-stage reasoning processes, such as fault localization and patch generation. We further enhance trajectory quality through rejection sampling, rigorously evaluating trajectories along accuracy and complexity. Externally, we propose a novel \textit{development-process-based search} strategy guided by reward models and execution verification. This approach enables targeted computational allocation at critical development decision points, overcoming limitations of existing "end-point only" verification methods. Evaluations on SWE-bench Verified demonstrate our \textbf{32B model achieves a 46\% issue resolution rate}, surpassing significantly larger models such as DeepSeek R1 671B and OpenAI o1. Additionally, we provide the empirical validation of the test-time scaling phenomenon within SWE agents, revealing that \textbf{models dynamically allocate more tokens to increasingly challenging problems}, effectively enhancing reasoning capabilities. We publicly release all training data, models, and code to facilitate future research. https://github.com/yingweima2022/SWE-Reasoner
Lingma SWE-GPT: An Open Development-Process-Centric Language Model for Automated Software Improvement
Nov 01, 2024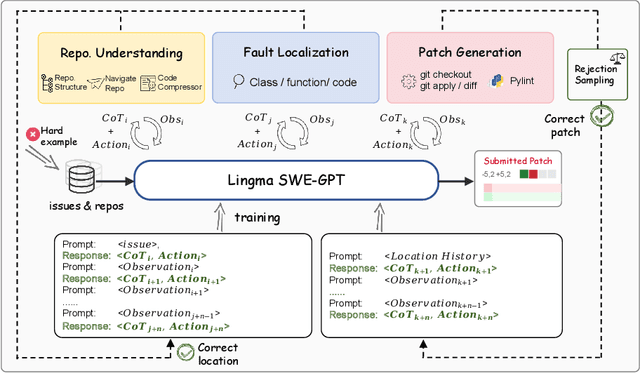


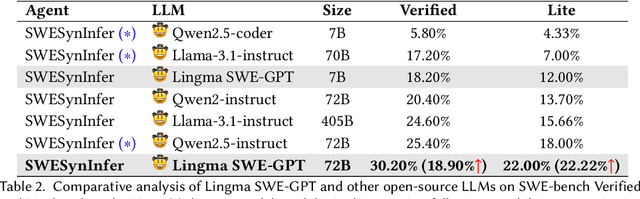
Recent advancements in LLM-based agents have led to significant progress in automatic software engineering, particularly in software maintenance and evolution. Despite these encouraging advances, current research faces two major challenges. First, SOTA performance primarily depends on closed-source models, which significantly limits the technology's accessibility, and potential for customization in diverse SE tasks. Second, these models are predominantly trained on static code data, lacking a deep understanding of the dynamic interactions, iterative problem-solving processes, and evolutionary characteristics inherent in software development. To address these challenges, our study adopts a software engineering perspective. We recognize that real-world software maintenance and evolution processes encompass not only static code data but also developers' thought processes, utilization of external tools, and the interaction between different functional personnel. Consequently, we introduce the Lingma SWE-GPT series, comprising Lingma SWE-GPT 7B and 72B. By learning from and simulating real-world code submission activities, Lingma SWE-GPT systematically incorporates the dynamic interactions and iterative problem-solving inherent in software development process, thereby achieving a more comprehensive understanding of software improvement processes. We conducted experimental evaluations using SWE-bench Verified benchmark. The results demonstrate that Lingma SWE-GPT 72B successfully resolves 30.20% of the GitHub issues, marking a significant improvement in automatic issue resolution (22.76% relative improvement compared to Llama 3.1 405B), approaching the performance of closed-source models (31.80\% issues of GPT-4o resolved). Notably, Lingma SWE-GPT 7B resolves 18.20% of the issues, highlighting the potential for applying smaller models to ASE tasks.
Resource Constrained Model Compression via Minimax Optimization for Spiking Neural Networks
Aug 09, 2023



Brain-inspired Spiking Neural Networks (SNNs) have the characteristics of event-driven and high energy-efficient, which are different from traditional Artificial Neural Networks (ANNs) when deployed on edge devices such as neuromorphic chips. Most previous work focuses on SNNs training strategies to improve model performance and brings larger and deeper network architectures. It is difficult to deploy these complex networks on resource-limited edge devices directly. To meet such demand, people compress SNNs very cautiously to balance the performance and the computation efficiency. Existing compression methods either iteratively pruned SNNs using weights norm magnitude or formulated the problem as a sparse learning optimization. We propose an improved end-to-end Minimax optimization method for this sparse learning problem to better balance the model performance and the computation efficiency. We also demonstrate that jointly applying compression and finetuning on SNNs is better than sequentially, especially for extreme compression ratios. The compressed SNN models achieved state-of-the-art (SOTA) performance on various benchmark datasets and architectures. Our code is available at https://github.com/chenjallen/Resource-Constrained-Compression-on-SNN.
Razor SNN: Efficient Spiking Neural Network with Temporal Embeddings
Jun 30, 2023The event streams generated by dynamic vision sensors (DVS) are sparse and non-uniform in the spatial domain, while still dense and redundant in the temporal domain. Although spiking neural network (SNN), the event-driven neuromorphic model, has the potential to extract spatio-temporal features from the event streams, it is not effective and efficient. Based on the above, we propose an events sparsification spiking framework dubbed as Razor SNN, pruning pointless event frames progressively. Concretely, we extend the dynamic mechanism based on the global temporal embeddings, reconstruct the features, and emphasize the events effect adaptively at the training stage. During the inference stage, eliminate fruitless frames hierarchically according to a binary mask generated by the trained temporal embeddings. Comprehensive experiments demonstrate that our Razor SNN achieves competitive performance consistently on four events-based benchmarks: DVS 128 Gesture, N-Caltech 101, CIFAR10-DVS and SHD.