 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLingma SWE-GPT: An Open Development-Process-Centric Language Model for Automated Software Improvement
Paper and Code
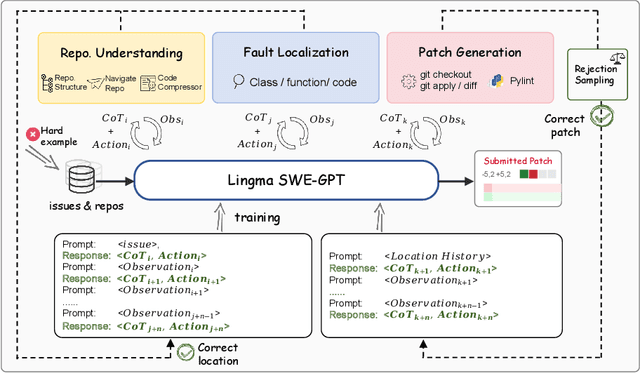


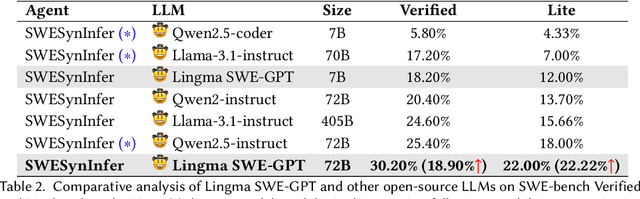
Recent advancements in LLM-based agents have led to significant progress in automatic software engineering, particularly in software maintenance and evolution. Despite these encouraging advances, current research faces two major challenges. First, SOTA performance primarily depends on closed-source models, which significantly limits the technology's accessibility, and potential for customization in diverse SE tasks. Second, these models are predominantly trained on static code data, lacking a deep understanding of the dynamic interactions, iterative problem-solving processes, and evolutionary characteristics inherent in software development. To address these challenges, our study adopts a software engineering perspective. We recognize that real-world software maintenance and evolution processes encompass not only static code data but also developers' thought processes, utilization of external tools, and the interaction between different functional personnel. Consequently, we introduce the Lingma SWE-GPT series, comprising Lingma SWE-GPT 7B and 72B. By learning from and simulating real-world code submission activities, Lingma SWE-GPT systematically incorporates the dynamic interactions and iterative problem-solving inherent in software development process, thereby achieving a more comprehensive understanding of software improvement processes. We conducted experimental evaluations using SWE-bench Verified benchmark. The results demonstrate that Lingma SWE-GPT 72B successfully resolves 30.20% of the GitHub issues, marking a significant improvement in automatic issue resolution (22.76% relative improvement compared to Llama 3.1 405B), approaching the performance of closed-source models (31.80\% issues of GPT-4o resolved). Notably, Lingma SWE-GPT 7B resolves 18.20% of the issues, highlighting the potential for applying smaller models to ASE tasks.