 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcT2I: Evaluating and Improving Action Depiction in Text-to-Image Models
Sep 19, 2025Text-to-Image (T2I) models have recently achieved remarkable success in generating images from textual descriptions. However, challenges still persist in accurately rendering complex scenes where actions and interactions form the primary semantic focus. Our key observation in this work is that T2I models frequently struggle to capture nuanced and often implicit attributes inherent in action depiction, leading to generating images that lack key contextual details. To enable systematic evaluation, we introduce AcT2I, a benchmark designed to evaluate the performance of T2I models in generating images from action-centric prompts. We experimentally validate that leading T2I models do not fare well on AcT2I. We further hypothesize that this shortcoming arises from the incomplete representation of the inherent attributes and contextual dependencies in the training corpora of existing T2I models. We build upon this by developing a training-free, knowledge distillation technique utilizing Large Language Models to address this limitation. Specifically, we enhance prompts by incorporating dense information across three dimensions, observing that injecting prompts with temporal details significantly improves image generation accuracy, with our best model achieving an increase of 72%. Our findings highlight the limitations of current T2I methods in generating images that require complex reasoning and demonstrate that integrating linguistic knowledge in a systematic way can notably advance the generation of nuanced and contextually accurate images.
TextInVision: Text and Prompt Complexity Driven Visual Text Generation Benchmark
Mar 17, 2025Generating images with embedded text is crucial for the automatic production of visual and multimodal documents, such as educational materials and advertisements. However, existing diffusion-based text-to-image models often struggle to accurately embed text within images, facing challenges in spelling accuracy, contextual relevance, and visual coherence. Evaluating the ability of such models to embed text within a generated image is complicated due to the lack of comprehensive benchmarks. In this work, we introduce TextInVision, a large-scale, text and prompt complexity driven benchmark designed to evaluate the ability of diffusion models to effectively integrate visual text into images. We crafted a diverse set of prompts and texts that consider various attributes and text characteristics. Additionally, we prepared an image dataset to test Variational Autoencoder (VAE) models across different character representations, highlighting that VAE architectures can also pose challenges in text generation within diffusion frameworks. Through extensive analysis of multiple models, we identify common errors and highlight issues such as spelling inaccuracies and contextual mismatches. By pinpointing the failure points across different prompts and texts, our research lays the foundation for future advancements in AI-generated multimodal content.
Steering Rectified Flow Models in the Vector Field for Controlled Image Generation
Nov 27, 2024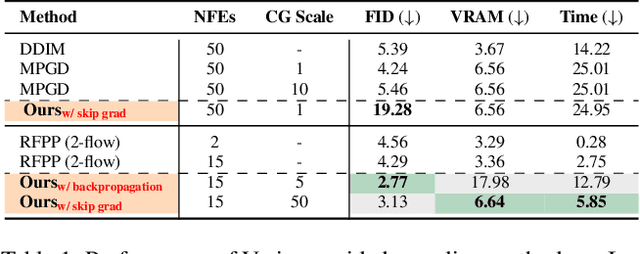
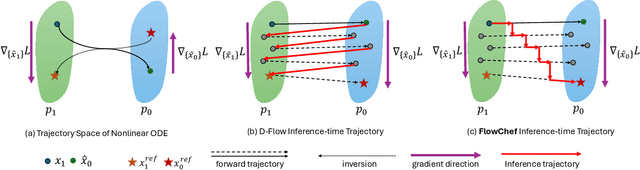
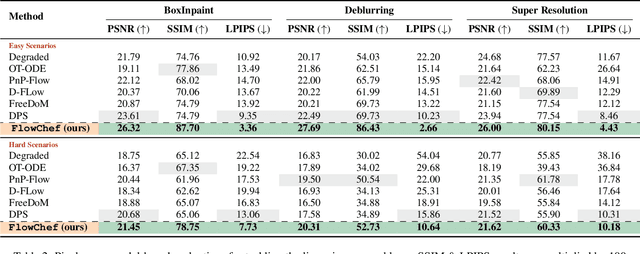

Diffusion models (DMs) excel in photorealism, image editing, and solving inverse problems, aided by classifier-free guidance and image inversion techniques. However, rectified flow models (RFMs) remain underexplored for these tasks. Existing DM-based methods often require additional training, lack generalization to pretrained latent models, underperform, and demand significant computational resources due to extensive backpropagation through ODE solvers and inversion processes. In this work, we first develop a theoretical and empirical understanding of the vector field dynamics of RFMs in efficiently guiding the denoising trajectory. Our findings reveal that we can navigate the vector field in a deterministic and gradient-free manner. Utilizing this property, we propose FlowChef, which leverages the vector field to steer the denoising trajectory for controlled image generation tasks, facilitated by gradient skipping. FlowChef is a unified framework for controlled image generation that, for the first time, simultaneously addresses classifier guidance, linear inverse problems, and image editing without the need for extra training, inversion, or intensive backpropagation. Finally, we perform extensive evaluations and show that FlowChef significantly outperforms baselines in terms of performance, memory, and time requirements, achieving new state-of-the-art results. Project Page: \url{https://flowchef.github.io}.
Precision or Recall? An Analysis of Image Captions for Training Text-to-Image Generation Model
Nov 07, 2024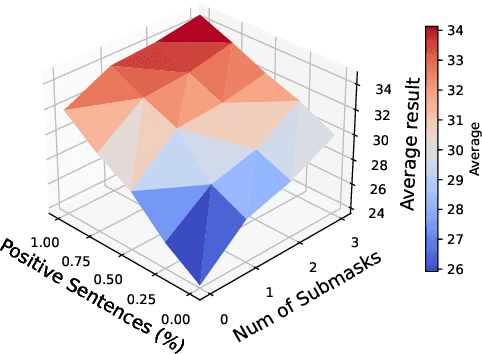

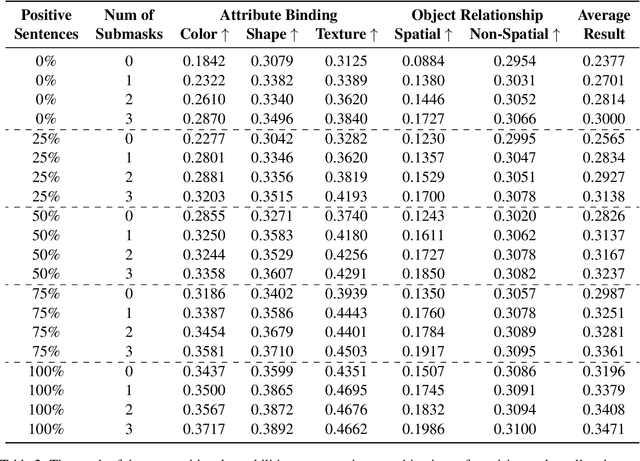

Despite advancements in text-to-image models, generating images that precisely align with textual descriptions remains challenging due to misalignment in training data. In this paper, we analyze the critical role of caption precision and recall in text-to-image model training. Our analysis of human-annotated captions shows that both precision and recall are important for text-image alignment, but precision has a more significant impact. Leveraging these insights, we utilize Large Vision Language Models to generate synthetic captions for training. Models trained with these synthetic captions show similar behavior to those trained on human-annotated captions, underscores the potential for synthetic data in text-to-image training.
TripletCLIP: Improving Compositional Reasoning of CLIP via Synthetic Vision-Language Negatives
Nov 04, 2024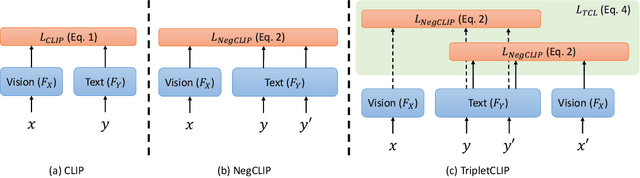

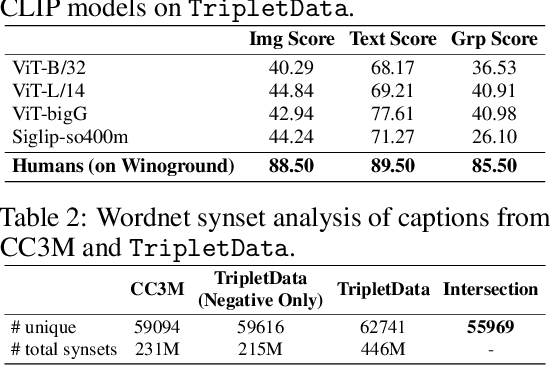

Contrastive Language-Image Pretraining (CLIP) models maximize the mutual information between text and visual modalities to learn representations. This makes the nature of the training data a significant factor in the efficacy of CLIP for downstream tasks. However, the lack of compositional diversity in contemporary image-text datasets limits the compositional reasoning ability of CLIP. We show that generating ``hard'' negative captions via in-context learning and synthesizing corresponding negative images with text-to-image generators offers a solution. We introduce a novel contrastive pre-training strategy that leverages these hard negative captions and images in an alternating fashion to train CLIP. We demonstrate that our method, named TripletCLIP, when applied to existing datasets such as CC3M and CC12M, enhances the compositional capabilities of CLIP, resulting in an absolute improvement of over 9% on the SugarCrepe benchmark on an equal computational budget, as well as improvements in zero-shot image classification and image retrieval. Our code, models, and data are available at: https://tripletclip.github.io
Help Me Identify: Is an LLM+VQA System All We Need to Identify Visual Concepts?
Oct 17, 2024



An ability to learn about new objects from a small amount of visual data and produce convincing linguistic justification about the presence/absence of certain concepts (that collectively compose the object) in novel scenarios is an important characteristic of human cognition. This is possible due to abstraction of attributes/properties that an object is composed of e.g. an object `bird' can be identified by the presence of a beak, feathers, legs, wings, etc. Inspired by this aspect of human reasoning, in this work, we present a zero-shot framework for fine-grained visual concept learning by leveraging large language model and Visual Question Answering (VQA) system. Specifically, we prompt GPT-3 to obtain a rich linguistic description of visual objects in the dataset. We convert the obtained concept descriptions into a set of binary questions. We pose these questions along with the query image to a VQA system and aggregate the answers to determine the presence or absence of an object in the test images. Our experiments demonstrate comparable performance with existing zero-shot visual classification methods and few-shot concept learning approaches, without substantial computational overhead, yet being fully explainable from the reasoning perspective.
$λ$-ECLIPSE: Multi-Concept Personalized Text-to-Image Diffusion Models by Leveraging CLIP Latent Space
Feb 07, 2024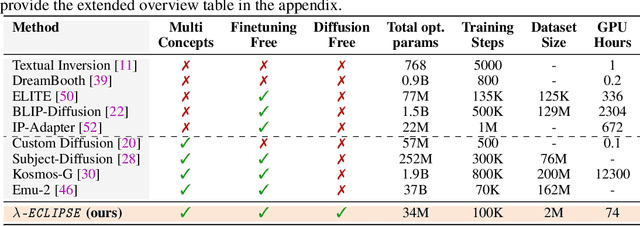


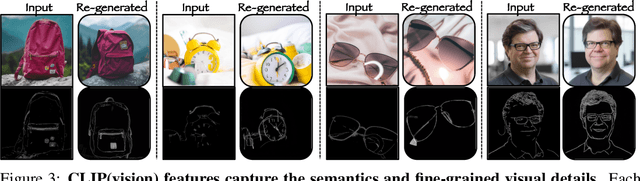
Despite the recent advances in personalized text-to-image (P-T2I) generative models, subject-driven T2I remains challenging. The primary bottlenecks include 1) Intensive training resource requirements, 2) Hyper-parameter sensitivity leading to inconsistent outputs, and 3) Balancing the intricacies of novel visual concept and composition alignment. We start by re-iterating the core philosophy of T2I diffusion models to address the above limitations. Predominantly, contemporary subject-driven T2I approaches hinge on Latent Diffusion Models (LDMs), which facilitate T2I mapping through cross-attention layers. While LDMs offer distinct advantages, P-T2I methods' reliance on the latent space of these diffusion models significantly escalates resource demands, leading to inconsistent results and necessitating numerous iterations for a single desired image. Recently, ECLIPSE has demonstrated a more resource-efficient pathway for training UnCLIP-based T2I models, circumventing the need for diffusion text-to-image priors. Building on this, we introduce $\lambda$-ECLIPSE. Our method illustrates that effective P-T2I does not necessarily depend on the latent space of diffusion models. $\lambda$-ECLIPSE achieves single, multi-subject, and edge-guided T2I personalization with just 34M parameters and is trained on a mere 74 GPU hours using 1.6M image-text interleaved data. Through extensive experiments, we also establish that $\lambda$-ECLIPSE surpasses existing baselines in composition alignment while preserving concept alignment performance, even with significantly lower resource utilization.
ECLIPSE: A Resource-Efficient Text-to-Image Prior for Image Generations
Dec 07, 2023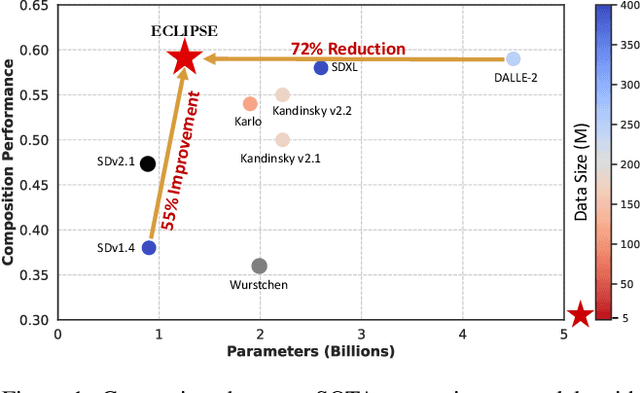



Text-to-image (T2I) diffusion models, notably the unCLIP models (e.g., DALL-E-2), achieve state-of-the-art (SOTA) performance on various compositional T2I benchmarks, at the cost of significant computational resources. The unCLIP stack comprises T2I prior and diffusion image decoder. The T2I prior model alone adds a billion parameters compared to the Latent Diffusion Models, which increases the computational and high-quality data requirements. We introduce ECLIPSE, a novel contrastive learning method that is both parameter and data-efficient. ECLIPSE leverages pre-trained vision-language models (e.g., CLIP) to distill the knowledge into the prior model. We demonstrate that the ECLIPSE trained prior, with only 3.3% of the parameters and trained on a mere 2.8% of the data, surpasses the baseline T2I priors with an average of 71.6% preference score under resource-limited setting. It also attains performance on par with SOTA big models, achieving an average of 63.36% preference score in terms of the ability to follow the text compositions. Extensive experiments on two unCLIP diffusion image decoders, Karlo and Kandinsky, affirm that ECLIPSE priors consistently deliver high performance while significantly reducing resource dependency.
WOUAF: Weight Modulation for User Attribution and Fingerprinting in Text-to-Image Diffusion Models
Jun 07, 2023



The rapid advancement of generative models, facilitating the creation of hyper-realistic images from textual descriptions, has concurrently escalated critical societal concerns such as misinformation. Traditional fake detection mechanisms, although providing some mitigation, fall short in attributing responsibility for the malicious use of synthetic images. This paper introduces a novel approach to model fingerprinting that assigns responsibility for the generated images, thereby serving as a potential countermeasure to model misuse. Our method modifies generative models based on each user's unique digital fingerprint, imprinting a unique identifier onto the resultant content that can be traced back to the user. This approach, incorporating fine-tuning into Text-to-Image (T2I) tasks using the Stable Diffusion Model, demonstrates near-perfect attribution accuracy with a minimal impact on output quality. We rigorously scrutinize our method's secrecy under two distinct scenarios: one where a malicious user attempts to detect the fingerprint, and another where a user possesses a comprehensive understanding of our method. We also evaluate the robustness of our approach against various image post-processing manipulations typically executed by end-users. Through extensive evaluation of the Stable Diffusion models, our method presents a promising and novel avenue for accountable model distribution and responsible use.
ConceptBed: Evaluating Concept Learning Abilities of Text-to-Image Diffusion Models
Jun 07, 2023The ability to understand visual concepts and replicate and compose these concepts from images is a central goal for computer vision. Recent advances in text-to-image (T2I) models have lead to high definition and realistic image quality generation by learning from large databases of images and their descriptions. However, the evaluation of T2I models has focused on photorealism and limited qualitative measures of visual understanding. To quantify the ability of T2I models in learning and synthesizing novel visual concepts, we introduce ConceptBed, a large-scale dataset that consists of 284 unique visual concepts, 5K unique concept compositions, and 33K composite text prompts. Along with the dataset, we propose an evaluation metric, Concept Confidence Deviation (CCD), that uses the confidence of oracle concept classifiers to measure the alignment between concepts generated by T2I generators and concepts contained in ground truth images. We evaluate visual concepts that are either objects, attributes, or styles, and also evaluate four dimensions of compositionality: counting, attributes, relations, and actions. Our human study shows that CCD is highly correlated with human understanding of concepts. Our results point to a trade-off between learning the concepts and preserving the compositionality which existing approaches struggle to overcome.