 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsynchronous Remote Sensing Time-Series Fusion for Cloud Removal and Anytime Reconstruction
May 26, 2026Frequent cloud cover severely limits the usability of Sentinel-2 (S2) optical time series for Earth surface monitoring. Sentinel-1 (S1) SAR provides all-weather complementary observations, but practical S1/S2 fusion remains difficult because acquisitions are irregular and asynchronous. Many existing approaches assume temporally aligned inputs (or require external nearest-date matching) and typically restore only observed timestamps, limiting reconstruction under long gaps and preventing on-demand synthesis. We propose AGFlow (Time Aligned Generative Flow Matching), a spatiotemporal flow-matching model for S1/S2 cloud removal and time-series reconstruction with three capabilities: (1) timestamp-conditioned internal alignment that fuses asynchronous S1 and cloudy S2 observations without preprocessing-based pairing; (2) spatiotemporal, context-aware denoising that models spatial structure jointly with temporal dynamics (rather than independent per-pixel time series); and (3) anytime querying, enabling generation of cloud-free S2 frames at both observed and user-specified timestamps within the monitoring window. We evaluate on the RESTORE-DiT benchmark protocol with quantitative metrics, qualitative comparisons, and component ablations. AGFlow notably improves fully missing-frame reconstruction (MAE and RMSE reduce by 16-19% over RESTORE-DiT) and provides reliable reconstructions under persistent gaps, while also yielding competitive cloud removal performance and flexible temporal querying for downstream tasks such as dense vegetation monitoring.
TextInVision: Text and Prompt Complexity Driven Visual Text Generation Benchmark
Mar 17, 2025Generating images with embedded text is crucial for the automatic production of visual and multimodal documents, such as educational materials and advertisements. However, existing diffusion-based text-to-image models often struggle to accurately embed text within images, facing challenges in spelling accuracy, contextual relevance, and visual coherence. Evaluating the ability of such models to embed text within a generated image is complicated due to the lack of comprehensive benchmarks. In this work, we introduce TextInVision, a large-scale, text and prompt complexity driven benchmark designed to evaluate the ability of diffusion models to effectively integrate visual text into images. We crafted a diverse set of prompts and texts that consider various attributes and text characteristics. Additionally, we prepared an image dataset to test Variational Autoencoder (VAE) models across different character representations, highlighting that VAE architectures can also pose challenges in text generation within diffusion frameworks. Through extensive analysis of multiple models, we identify common errors and highlight issues such as spelling inaccuracies and contextual mismatches. By pinpointing the failure points across different prompts and texts, our research lays the foundation for future advancements in AI-generated multimodal content.
Deep Reinforcement Learning for Online Error Detection in Cyber-Physical Systems
Feb 03, 2023Reliability is one of the major design criteria in Cyber-Physical Systems (CPSs). This is because of the existence of some critical applications in CPSs and their failure is catastrophic. Therefore, employing strong error detection and correction mechanisms in CPSs is inevitable. CPSs are composed of a variety of units, including sensors, networks, and microcontrollers. Each of these units is probable to be in a faulty state at any time and the occurred fault can result in erroneous output. The fault may cause the units of CPS to malfunction and eventually crash. Traditional fault-tolerant approaches include redundancy time, hardware, information, and/or software. However, these approaches impose significant overheads besides their low error coverage, which limits their applicability. In addition, the interval between error occurrence and detection is too long in these approaches. In this paper, based on Deep Reinforcement Learning (DRL), a new error detection approach is proposed that not only detects errors with high accuracy but also can perform error detection at the moment due to very low inference time. The proposed approach can categorize different types of errors from normal data and predict whether the system will fail. The evaluation results illustrate that the proposed approach has improved more than 2x in terms of accuracy and more than 5x in terms of inference time compared to other approaches.
A Novel Neuromorphic Processors Realization of Spiking Deep Reinforcement Learning for Portfolio Management
Mar 26, 2022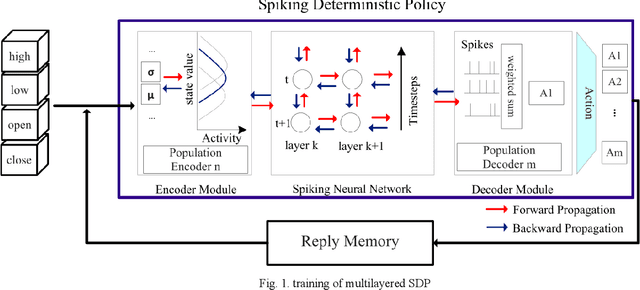
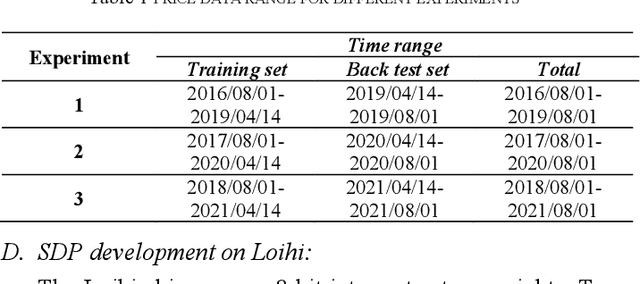
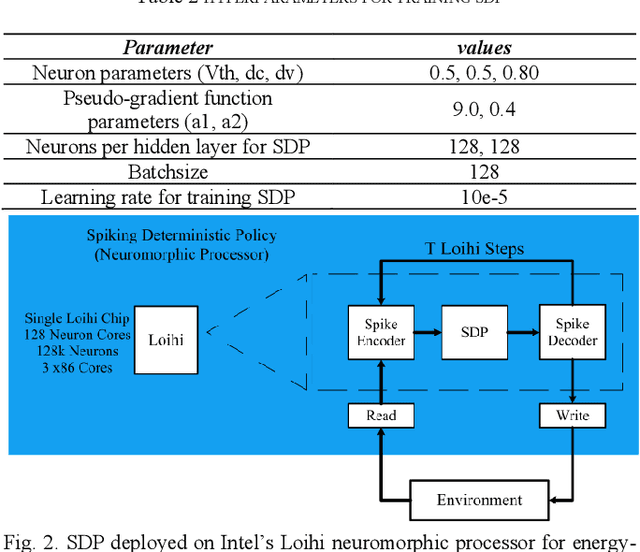
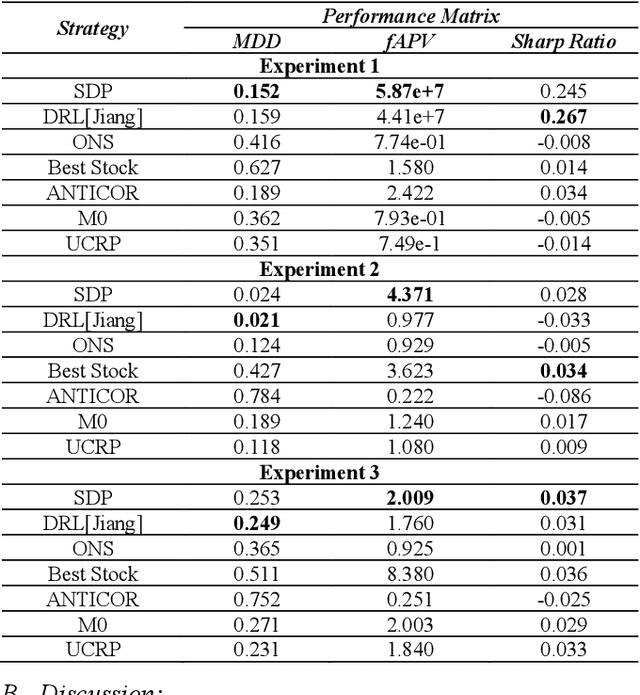
The process of continuously reallocating funds into financial assets, aiming to increase the expected return of investment and minimizing the risk, is known as portfolio management. Processing speed and energy consumption of portfolio management have become crucial as the complexity of their real-world applications increasingly involves high-dimensional observation and action spaces and environment uncertainty, which their limited onboard resources cannot offset. Emerging neuromorphic chips inspired by the human brain increase processing speed by up to 1000 times and reduce power consumption by several orders of magnitude. This paper proposes a spiking deep reinforcement learning (SDRL) algorithm that can predict financial markets based on unpredictable environments and achieve the defined portfolio management goal of profitability and risk reduction. This algorithm is optimized forIntel's Loihi neuromorphic processor and provides 186x and 516x energy consumption reduction is observed compared to the competitors, respectively. In addition, a 1.3x and 2.0x speed-up over the high-end processors and GPUs, respectively. The evaluations are performed on cryptocurrency market between 2016 and 2021 the benchmark.