 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePARD: Accelerating LLM Inference with Low-Cost PARallel Draft Model Adaptation
Apr 29, 2025The autoregressive nature of large language models (LLMs) limits inference speed. Each forward pass generates only a single token and is often bottlenecked by memory bandwidth. Speculative decoding alleviates this issue using a draft-then-verify approach to accelerate token generation. However, the overhead introduced during the draft phase and the training cost of the draft model limit the efficiency and adaptability of speculative decoding. In this work, we introduce PARallel Draft (PARD), a novel speculative decoding method that enables low-cost adaptation of autoregressive draft models into parallel draft models. PARD enhances inference efficiency by predicting multiple future tokens in a single forward pass of the draft phase, and incorporates a conditional drop token method to accelerate training. Its target-independence property allows a single draft model to be applied to an entire family of different models, minimizing the adaptation cost. Our proposed conditional drop token method can improves draft model training efficiency by 3x. On our optimized inference framework, PARD accelerates LLaMA3.1-8B inference by 4.08x, achieving 311.5 tokens per second.
Semantics-Consistent Feature Search for Self-Supervised Visual Representation Learning
Dec 13, 2022
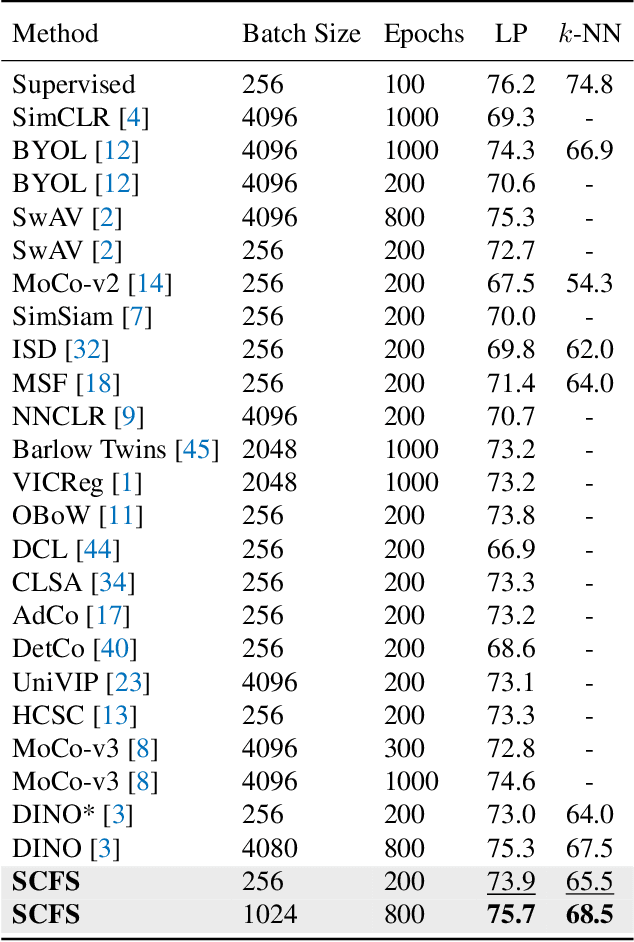


In contrastive self-supervised learning, the common way to learn discriminative representation is to pull different augmented "views" of the same image closer while pushing all other images further apart, which has been proven to be effective. However, it is unavoidable to construct undesirable views containing different semantic concepts during the augmentation procedure. It would damage the semantic consistency of representation to pull these augmentations closer in the feature space indiscriminately. In this study, we introduce feature-level augmentation and propose a novel semantics-consistent feature search (SCFS) method to mitigate this negative effect. The main idea of SCFS is to adaptively search semantics-consistent features to enhance the contrast between semantics-consistent regions in different augmentations. Thus, the trained model can learn to focus on meaningful object regions, improving the semantic representation ability. Extensive experiments conducted on different datasets and tasks demonstrate that SCFS effectively improves the performance of self-supervised learning and achieves state-of-the-art performance on different downstream tasks.