 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Mode Online Knowledge Distillation for Self-Supervised Visual Representation Learning
Apr 13, 2023
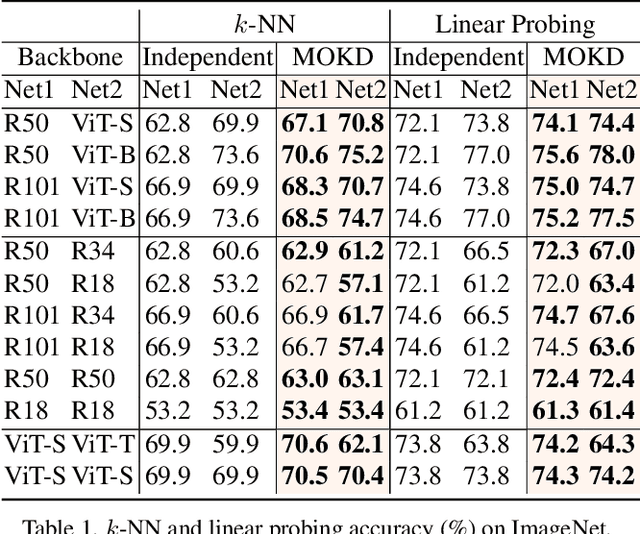

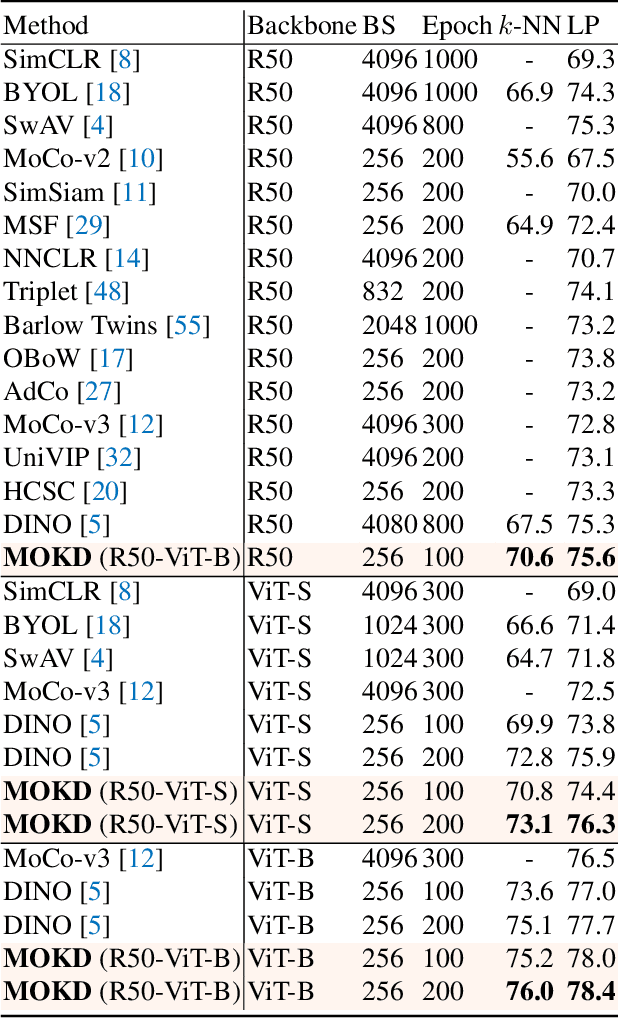
Self-supervised learning (SSL) has made remarkable progress in visual representation learning. Some studies combine SSL with knowledge distillation (SSL-KD) to boost the representation learning performance of small models. In this study, we propose a Multi-mode Online Knowledge Distillation method (MOKD) to boost self-supervised visual representation learning. Different from existing SSL-KD methods that transfer knowledge from a static pre-trained teacher to a student, in MOKD, two different models learn collaboratively in a self-supervised manner. Specifically, MOKD consists of two distillation modes: self-distillation and cross-distillation modes. Among them, self-distillation performs self-supervised learning for each model independently, while cross-distillation realizes knowledge interaction between different models. In cross-distillation, a cross-attention feature search strategy is proposed to enhance the semantic feature alignment between different models. As a result, the two models can absorb knowledge from each other to boost their representation learning performance. Extensive experimental results on different backbones and datasets demonstrate that two heterogeneous models can benefit from MOKD and outperform their independently trained baseline. In addition, MOKD also outperforms existing SSL-KD methods for both the student and teacher models.
Semantics-Consistent Feature Search for Self-Supervised Visual Representation Learning
Dec 13, 2022
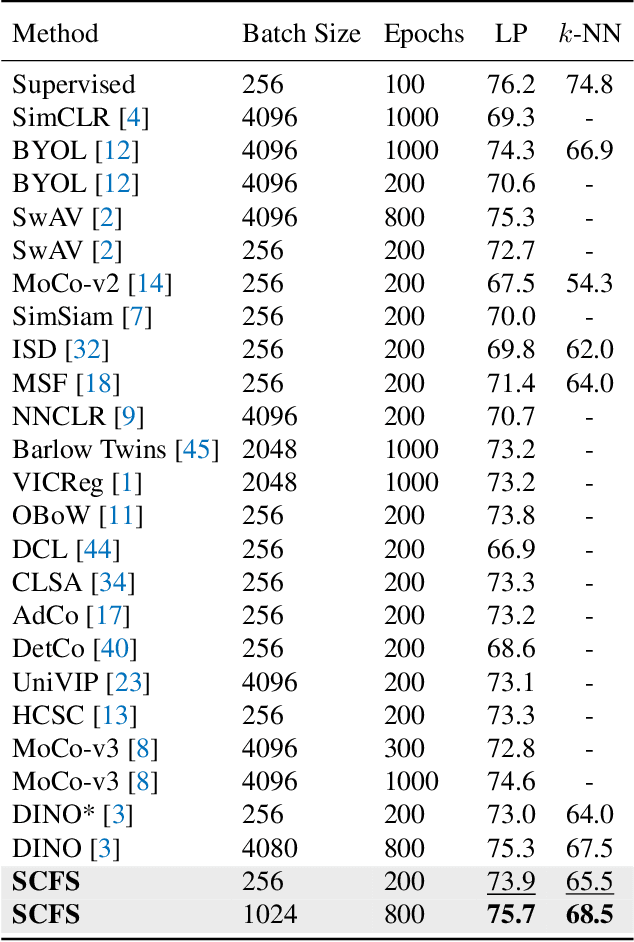


In contrastive self-supervised learning, the common way to learn discriminative representation is to pull different augmented "views" of the same image closer while pushing all other images further apart, which has been proven to be effective. However, it is unavoidable to construct undesirable views containing different semantic concepts during the augmentation procedure. It would damage the semantic consistency of representation to pull these augmentations closer in the feature space indiscriminately. In this study, we introduce feature-level augmentation and propose a novel semantics-consistent feature search (SCFS) method to mitigate this negative effect. The main idea of SCFS is to adaptively search semantics-consistent features to enhance the contrast between semantics-consistent regions in different augmentations. Thus, the trained model can learn to focus on meaningful object regions, improving the semantic representation ability. Extensive experiments conducted on different datasets and tasks demonstrate that SCFS effectively improves the performance of self-supervised learning and achieves state-of-the-art performance on different downstream tasks.