 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePARD: Accelerating LLM Inference with Low-Cost PARallel Draft Model Adaptation
Apr 29, 2025



The autoregressive nature of large language models (LLMs) limits inference speed. Each forward pass generates only a single token and is often bottlenecked by memory bandwidth. Speculative decoding alleviates this issue using a draft-then-verify approach to accelerate token generation. However, the overhead introduced during the draft phase and the training cost of the draft model limit the efficiency and adaptability of speculative decoding. In this work, we introduce PARallel Draft (PARD), a novel speculative decoding method that enables low-cost adaptation of autoregressive draft models into parallel draft models. PARD enhances inference efficiency by predicting multiple future tokens in a single forward pass of the draft phase, and incorporates a conditional drop token method to accelerate training. Its target-independence property allows a single draft model to be applied to an entire family of different models, minimizing the adaptation cost. Our proposed conditional drop token method can improves draft model training efficiency by 3x. On our optimized inference framework, PARD accelerates LLaMA3.1-8B inference by 4.08x, achieving 311.5 tokens per second.
FACE: Evaluating Natural Language Generation with Fourier Analysis of Cross-Entropy
May 18, 2023Measuring the distance between machine-produced and human language is a critical open problem. Inspired by empirical findings from psycholinguistics on the periodicity of entropy in language, we propose FACE, a set of metrics based on Fourier Analysis of the estimated Cross-Entropy of language, for measuring the similarity between model-generated and human-written languages. Based on an open-ended generation task and the experimental data from previous studies, we find that FACE can effectively identify the human-model gap, scales with model size, reflects the outcomes of different sampling methods for decoding, correlates well with other evaluation metrics and with human judgment scores. FACE is computationally efficient and provides intuitive interpretations.
PaCaNet: A Study on CycleGAN with Transfer Learning for Diversifying Fused Chinese Painting and Calligraphy
Feb 01, 2023

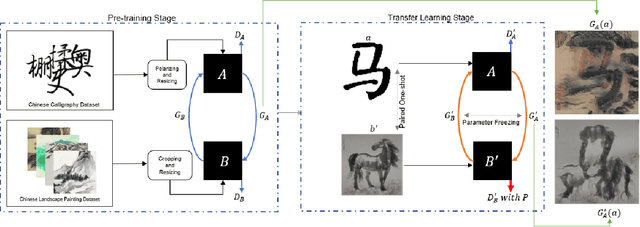

AI-Generated Content (AIGC) has recently gained a surge in popularity, powered by its high efficiency and consistency in production, and its capability of being customized and diversified. The cross-modality nature of the representation learning mechanism in most AIGC technology allows for more freedom and flexibility in exploring new types of art that would be impossible in the past. Inspired by the pictogram subset of Chinese characters, we proposed PaCaNet, a CycleGAN-based pipeline for producing novel artworks that fuse two different art types, traditional Chinese painting and calligraphy. In an effort to produce stable and diversified output, we adopted three main technical innovations: 1. Using one-shot learning to increase the creativity of pre-trained models and diversify the content of the fused images. 2. Controlling the preference over generated Chinese calligraphy by freezing randomly sampled parameters in pre-trained models. 3. Using a regularization method to encourage the models to produce images similar to Chinese paintings. Furthermore, we conducted a systematic study to explore the performance of PaCaNet in diversifying fused Chinese painting and calligraphy, which showed satisfying results. In conclusion, we provide a new direction of creating arts by fusing the visual information in paintings and the stroke features in Chinese calligraphy. Our approach creates a unique aesthetic experience rooted in the origination of Chinese hieroglyph characters. It is also a unique opportunity to delve deeper into traditional artwork and, in doing so, to create a meaningful impact on preserving and revitalizing traditional heritage.
A Corpus for Reasoning About Natural Language Grounded in Photographs
Nov 01, 2018


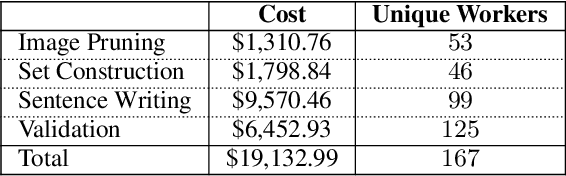
We introduce a new dataset for joint reasoning about language and vision. The data contains 107,296 examples of English sentences paired with web photographs. The task is to determine whether a natural language caption is true about a photograph. We present an approach for finding visually complex images and crowdsourcing linguistically diverse captions. Qualitative analysis shows the data requires complex reasoning about quantities, comparisons, and relationships between objects. Evaluation of state-of-the-art visual reasoning methods shows the data is a challenge for current methods.