 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Corpus for Reasoning About Natural Language Grounded in Photographs
Nov 01, 2018


We introduce a new dataset for joint reasoning about language and vision. The data contains 107,296 examples of English sentences paired with web photographs. The task is to determine whether a natural language caption is true about a photograph. We present an approach for finding visually complex images and crowdsourcing linguistically diverse captions. Qualitative analysis shows the data requires complex reasoning about quantities, comparisons, and relationships between objects. Evaluation of state-of-the-art visual reasoning methods shows the data is a challenge for current methods.
Visual Reasoning with Natural Language
Oct 02, 2017
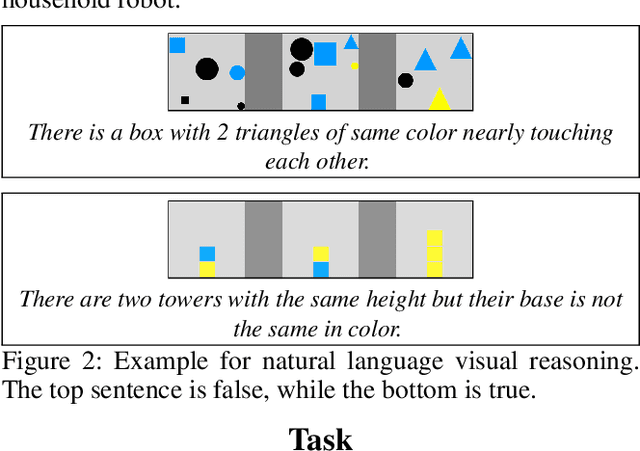
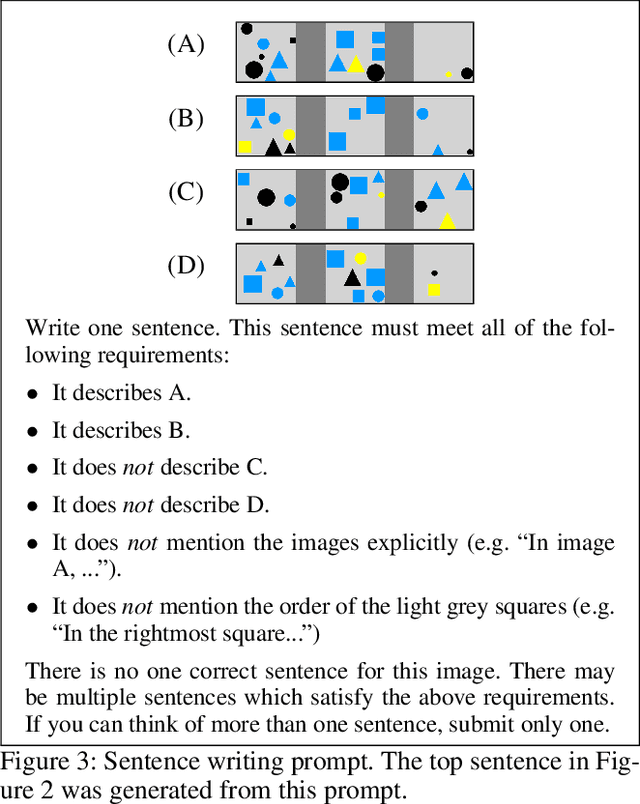

Natural language provides a widely accessible and expressive interface for robotic agents. To understand language in complex environments, agents must reason about the full range of language inputs and their correspondence to the world. Such reasoning over language and vision is an open problem that is receiving increasing attention. While existing data sets focus on visual diversity, they do not display the full range of natural language expressions, such as counting, set reasoning, and comparisons. We propose a simple task for natural language visual reasoning, where images are paired with descriptive statements. The task is to predict if a statement is true for the given scene. This abstract describes our existing synthetic images corpus and our current work on collecting real vision data.