 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSVAgent: Storyline-Guided Long Video Understanding via Cross-Modal Multi-Agent Collaboration
Apr 06, 2026Video question answering (VideoQA) is a challenging task that requires integrating spatial, temporal, and semantic information to capture the complex dynamics of video sequences. Although recent advances have introduced various approaches for video understanding, most existing methods still rely on locating relevant frames to answer questions rather than reasoning through the evolving storyline as humans do. Humans naturally interpret videos through coherent storylines, an ability that is crucial for making robust and contextually grounded predictions. To address this gap, we propose SVAgent, a storyline-guided cross-modal multi-agent framework for VideoQA. The storyline agent progressively constructs a narrative representation based on frames suggested by a refinement suggestion agent that analyzes historical failures. In addition, cross-modal decision agents independently predict answers from visual and textual modalities under the guidance of the evolving storyline. Their outputs are then evaluated by a meta-agent to align cross-modal predictions and enhance reasoning robustness and answer consistency. Experimental results demonstrate that SVAgent achieves superior performance and interpretability by emulating human-like storyline reasoning in video understanding.
STProtein: predicting spatial protein expression from multi-omics data
Feb 05, 2026The integration of spatial multi-omics data from single tissues is crucial for advancing biological research. However, a significant data imbalance impedes progress: while spatial transcriptomics data is relatively abundant, spatial proteomics data remains scarce due to technical limitations and high costs. To overcome this challenge we propose STProtein, a novel framework leveraging graph neural networks with multi-task learning strategy. STProtein is designed to accurately predict unknown spatial protein expression using more accessible spatial multi-omics data, such as spatial transcriptomics. We believe that STProtein can effectively addresses the scarcity of spatial proteomics, accelerating the integration of spatial multi-omics and potentially catalyzing transformative breakthroughs in life sciences. This tool enables scientists to accelerate discovery by identifying complex and previously hidden spatial patterns of proteins within tissues, uncovering novel relationships between different marker genes, and exploring the biological "Dark Matter".
From Scalar Rewards to Potential Trends: Shaping Potential Landscapes for Model-Based Reinforcement Learning
Feb 03, 2026Model-based reinforcement learning (MBRL) achieves high sample efficiency by simulating future trajectories with learned dynamics and reward models. However, its effectiveness is severely compromised in sparse reward settings. The core limitation lies in the standard paradigm of regressing ground-truth scalar rewards: in sparse environments, this yields a flat, gradient-free landscape that fails to provide directional guidance for planning. To address this challenge, we propose Shaping Landscapes with Optimistic Potential Estimates (SLOPE), a novel framework that shifts reward modeling from predicting scalars to constructing informative potential landscapes. SLOPE employs optimistic distributional regression to estimate high-confidence upper bounds, which amplifies rare success signals and ensures sufficient exploration gradients. Evaluations on 30+ tasks across 5 benchmarks demonstrate that SLOPE consistently outperforms leading baselines in fully sparse, semi-sparse, and dense rewards.
XR: Cross-Modal Agents for Composed Image Retrieval
Jan 20, 2026Retrieval is being redefined by agentic AI, demanding multimodal reasoning beyond conventional similarity-based paradigms. Composed Image Retrieval (CIR) exemplifies this shift as each query combines a reference image with textual modifications, requiring compositional understanding across modalities. While embedding-based CIR methods have achieved progress, they remain narrow in perspective, capturing limited cross-modal cues and lacking semantic reasoning. To address these limitations, we introduce XR, a training-free multi-agent framework that reframes retrieval as a progressively coordinated reasoning process. It orchestrates three specialized types of agents: imagination agents synthesize target representations through cross-modal generation, similarity agents perform coarse filtering via hybrid matching, and question agents verify factual consistency through targeted reasoning for fine filtering. Through progressive multi-agent coordination, XR iteratively refines retrieval to meet both semantic and visual query constraints, achieving up to a 38% gain over strong training-free and training-based baselines on FashionIQ, CIRR, and CIRCO, while ablations show each agent is essential. Code is available: https://01yzzyu.github.io/xr.github.io/.
Navigating Public Sentiment in the Circular Economy through Topic Modelling and Hyperparameter Optimisation
May 16, 2024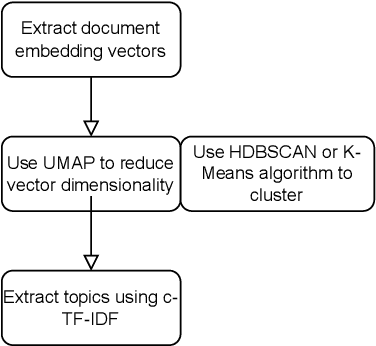

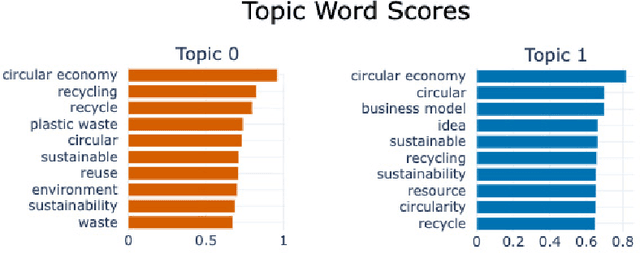
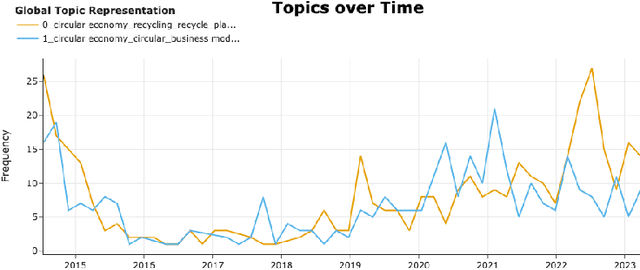
To advance the circular economy (CE), it is crucial to gain insights into the evolution of public sentiments, cognitive pathways of the masses concerning circular products and digital technology, and recognise the primary concerns. To achieve this, we collected data related to the CE from diverse platforms including Twitter, Reddit, and The Guardian. This comprehensive data collection spanned across three distinct strata of the public: the general public, professionals, and official sources. Subsequently, we utilised three topic models on the collected data. Topic modelling represents a type of data-driven and machine learning approach for text mining, capable of automatically categorising a large number of documents into distinct semantic groups. Simultaneously, these groups are described by topics, and these topics can aid in understanding the semantic content of documents at a high level. However, the performance of topic modelling may vary depending on different hyperparameter values. Therefore, in this study, we proposed a framework for topic modelling with hyperparameter optimisation for CE and conducted a series of systematic experiments to ensure that topic models are set with appropriate hyperparameters and to gain insights into the correlations between the CE and public opinion based on well-established models. The results of this study indicate that concerns about sustainability and economic impact persist across all three datasets. Official sources demonstrate a higher level of engagement with the application and regulation of CE. To the best of our knowledge, this study is pioneering in investigating various levels of public opinions concerning CE through topic modelling with the exploration of hyperparameter optimisation.
SAIS: A Novel Bio-Inspired Artificial Immune System Based on Symbiotic Paradigm
Feb 11, 2024
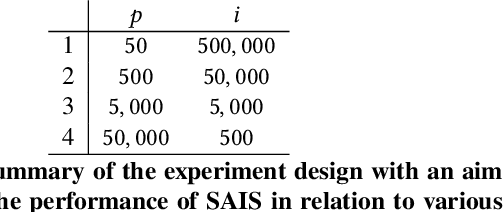
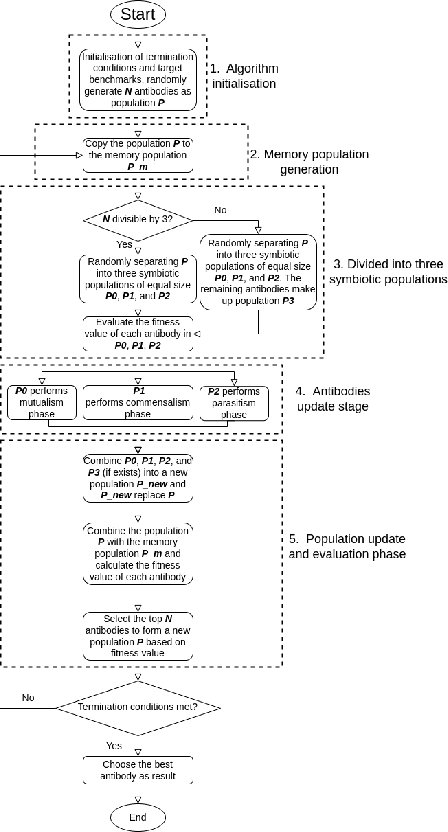
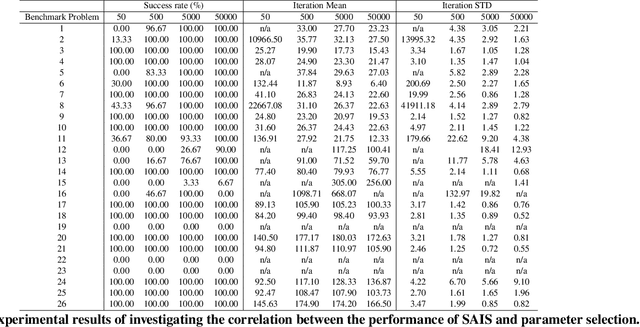
We propose a novel type of Artificial Immune System (AIS): Symbiotic Artificial Immune Systems (SAIS), drawing inspiration from symbiotic relationships in biology. SAIS parallels the three key stages (i.e., mutualism, commensalism and parasitism) of population updating from the Symbiotic Organisms Search (SOS) algorithm. This parallel approach effectively addresses the challenges of large population size and enhances population diversity in AIS, which traditional AIS and SOS struggle to resolve efficiently. We conducted a series of experiments, which demonstrated that our SAIS achieved comparable performance to the state-of-the-art approach SOS and outperformed other popular AIS approaches and evolutionary algorithms across 26 benchmark problems. Furthermore, we investigated the problem of parameter selection and found that SAIS performs better in handling larger population sizes while requiring fewer generations. Finally, we believe SAIS, as a novel bio-inspired and immune-inspired algorithm, paves the way for innovation in bio-inspired computing with the symbiotic paradigm.
FACE: Evaluating Natural Language Generation with Fourier Analysis of Cross-Entropy
May 18, 2023Measuring the distance between machine-produced and human language is a critical open problem. Inspired by empirical findings from psycholinguistics on the periodicity of entropy in language, we propose FACE, a set of metrics based on Fourier Analysis of the estimated Cross-Entropy of language, for measuring the similarity between model-generated and human-written languages. Based on an open-ended generation task and the experimental data from previous studies, we find that FACE can effectively identify the human-model gap, scales with model size, reflects the outcomes of different sampling methods for decoding, correlates well with other evaluation metrics and with human judgment scores. FACE is computationally efficient and provides intuitive interpretations.
PaCaNet: A Study on CycleGAN with Transfer Learning for Diversifying Fused Chinese Painting and Calligraphy
Feb 01, 2023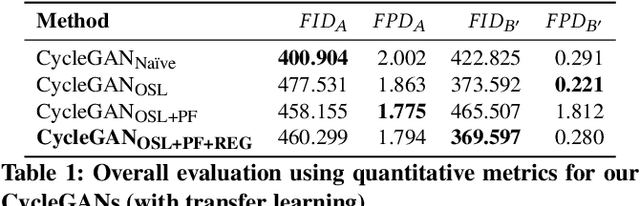

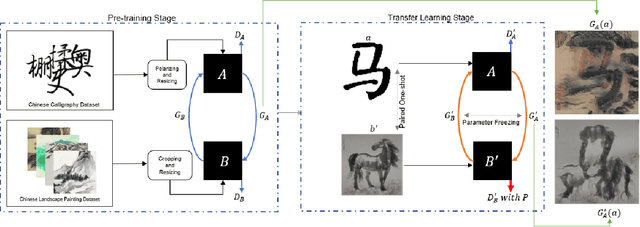

AI-Generated Content (AIGC) has recently gained a surge in popularity, powered by its high efficiency and consistency in production, and its capability of being customized and diversified. The cross-modality nature of the representation learning mechanism in most AIGC technology allows for more freedom and flexibility in exploring new types of art that would be impossible in the past. Inspired by the pictogram subset of Chinese characters, we proposed PaCaNet, a CycleGAN-based pipeline for producing novel artworks that fuse two different art types, traditional Chinese painting and calligraphy. In an effort to produce stable and diversified output, we adopted three main technical innovations: 1. Using one-shot learning to increase the creativity of pre-trained models and diversify the content of the fused images. 2. Controlling the preference over generated Chinese calligraphy by freezing randomly sampled parameters in pre-trained models. 3. Using a regularization method to encourage the models to produce images similar to Chinese paintings. Furthermore, we conducted a systematic study to explore the performance of PaCaNet in diversifying fused Chinese painting and calligraphy, which showed satisfying results. In conclusion, we provide a new direction of creating arts by fusing the visual information in paintings and the stroke features in Chinese calligraphy. Our approach creates a unique aesthetic experience rooted in the origination of Chinese hieroglyph characters. It is also a unique opportunity to delve deeper into traditional artwork and, in doing so, to create a meaningful impact on preserving and revitalizing traditional heritage.
Which Hyperparameters to Optimise? An Investigation of Evolutionary Hyperparameter Optimisation in Graph Neural Network For Molecular Property Prediction
Apr 14, 2021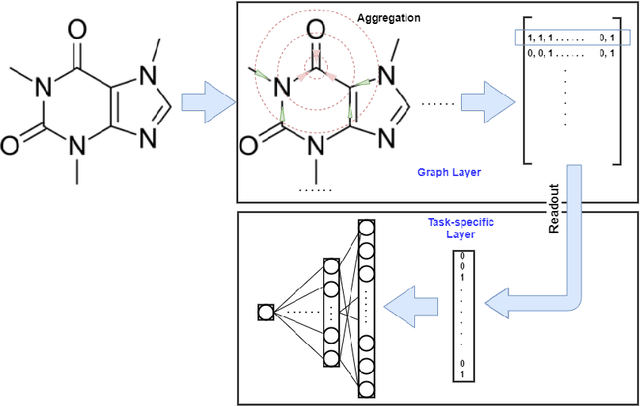

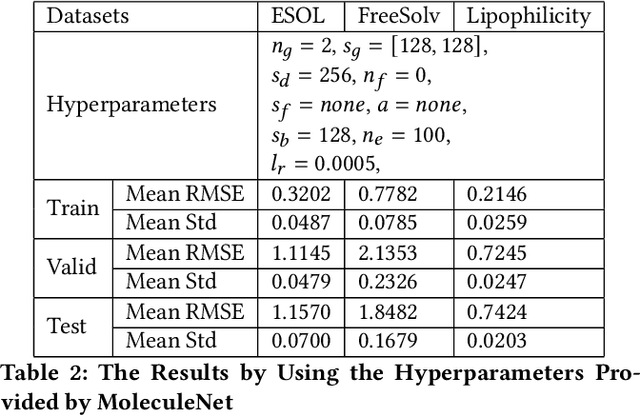
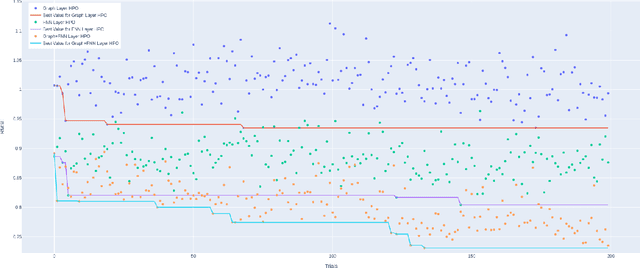
Recently, the study of graph neural network (GNN) has attracted much attention and achieved promising performance in molecular property prediction. Most GNNs for molecular property prediction are proposed based on the idea of learning the representations for the nodes by aggregating the information of their neighbor nodes (e.g. atoms). Then, the representations can be passed to subsequent layers to deal with individual downstream tasks. Therefore, the architectures of GNNs can be considered as being composed of two core parts: graph-related layers and task-specific layers. Facing real-world molecular problems, the hyperparameter optimization for those layers are vital. Hyperparameter optimization (HPO) becomes expensive in this situation because evaluating candidate solutions requires massive computational resources to train and validate models. Furthermore, a larger search space often makes the HPO problems more challenging. In this research, we focus on the impact of selecting two types of GNN hyperparameters, those belonging to graph-related layers and those of task-specific layers, on the performance of GNN for molecular property prediction. In our experiments. we employed a state-of-the-art evolutionary algorithm (i.e., CMA-ES) for HPO. The results reveal that optimizing the two types of hyperparameters separately can gain the improvements on GNNs' performance, but optimising both types of hyperparameters simultaneously will lead to predominant improvements. Meanwhile, our study also further confirms the importance of HPO for GNNs in molecular property prediction problems.
A Genetic Algorithm with Tree-structured Mutation for Hyperparameter Optimisation of Graph Neural Networks
Feb 24, 2021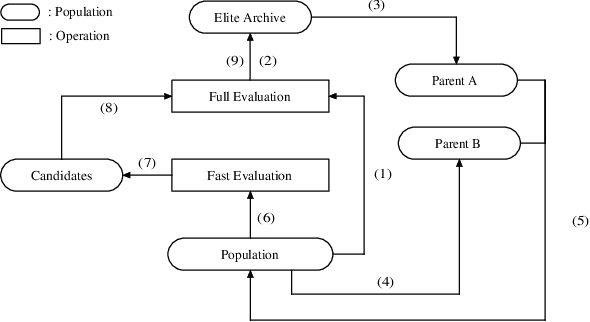
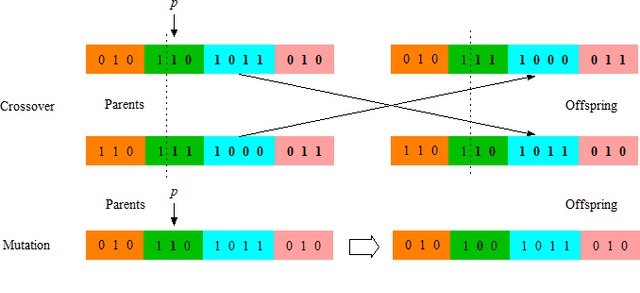
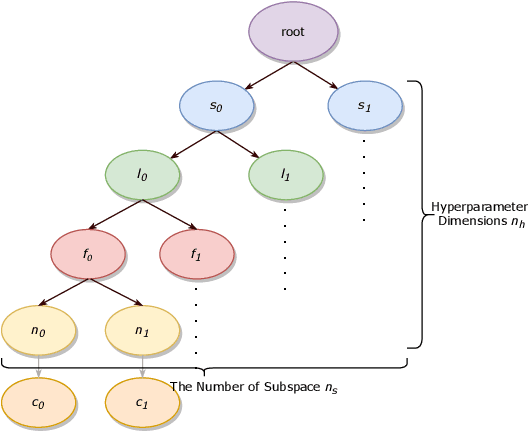

In recent years, graph neural networks (GNNs) have gained increasing attention, as they possess excellent capability of processing graph-related problems. In practice, hyperparameter optimisation (HPO) is critical for GNNs to achieve satisfactory results, but this process is costly because the evaluations of different hyperparameter settings require excessively training many GNNs. Many approaches have been proposed for HPO which aims to identify promising hyperparameters efficiently. In particular, genetic algorithm (GA) for HPO has been explored, which treats GNNs as a black-box model, of which only the outputs can be observed given a set of hyperparameters. However, because GNN models are extremely sophisticated and the evaluations of hyperparameters on GNNs are expensive, GA requires advanced techniques to balance the exploration and exploitation of the search and make the optimisation more effective given limited computational resources. Therefore, we proposed a tree-structured mutation strategy for GA to alleviate this issue. Meanwhile, we reviewed the recent HPO works which gives the room to the idea of tree-structure to develop, and we hope our approach can further improve these HPO methods in the future.