 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavigating Public Sentiment in the Circular Economy through Topic Modelling and Hyperparameter Optimisation
Paper and Code
May 16, 2024

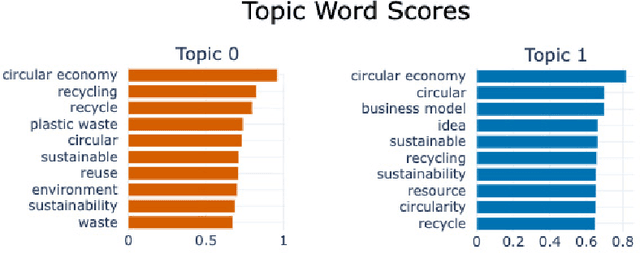
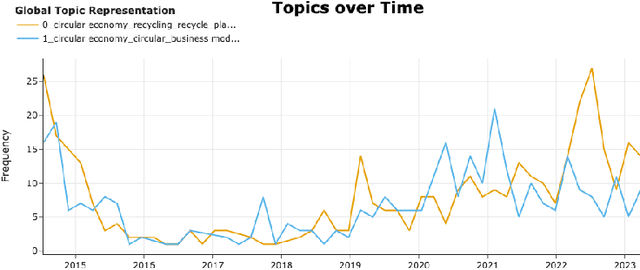
To advance the circular economy (CE), it is crucial to gain insights into the evolution of public sentiments, cognitive pathways of the masses concerning circular products and digital technology, and recognise the primary concerns. To achieve this, we collected data related to the CE from diverse platforms including Twitter, Reddit, and The Guardian. This comprehensive data collection spanned across three distinct strata of the public: the general public, professionals, and official sources. Subsequently, we utilised three topic models on the collected data. Topic modelling represents a type of data-driven and machine learning approach for text mining, capable of automatically categorising a large number of documents into distinct semantic groups. Simultaneously, these groups are described by topics, and these topics can aid in understanding the semantic content of documents at a high level. However, the performance of topic modelling may vary depending on different hyperparameter values. Therefore, in this study, we proposed a framework for topic modelling with hyperparameter optimisation for CE and conducted a series of systematic experiments to ensure that topic models are set with appropriate hyperparameters and to gain insights into the correlations between the CE and public opinion based on well-established models. The results of this study indicate that concerns about sustainability and economic impact persist across all three datasets. Official sources demonstrate a higher level of engagement with the application and regulation of CE. To the best of our knowledge, this study is pioneering in investigating various levels of public opinions concerning CE through topic modelling with the exploration of hyperparameter optimisation.