 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCI-PRM: A Tool Aware Process Reward Model for Scientific Reasoning Verification
Jun 03, 2026While Process Reward Models (PRMs) have achieved remarkable success in mathematical reasoning, their application in complex scientific domains-such as biology, chemistry, and physics remains largely unexplored. Scientific problems demand not only logical rigor but also factual consistency and the precise usage of domain-specific tools, areas where current models often suffer from hallucinations and lack of verification. In this paper, we first construct SCIPRM70K, a large-scale dataset featuring Chain-of-Tool trajectories that explicitly interleave reasoning with the execution of scientific tools. Building upon this, we train an efficient reward model called Sci-PRM to provide fine-grained supervision on tool selection, execution accuracy, and result interpretation at each step in one inference. Experiments demonstrate that Sci-PRM significantly enhances foundation models in two key aspects: (1) it enables effective test-time scaling via Best-of-N selection; and (2) when integrated into Reinforcement Learning, it serves as a dense reward signal that mitigates the critical issue of advantage disappearance, allowing the model to break through existing performance ceilings.
LLaVA-CMoE: Towards Continual Mixture of Experts for Large Vision-Language Models
Mar 27, 2025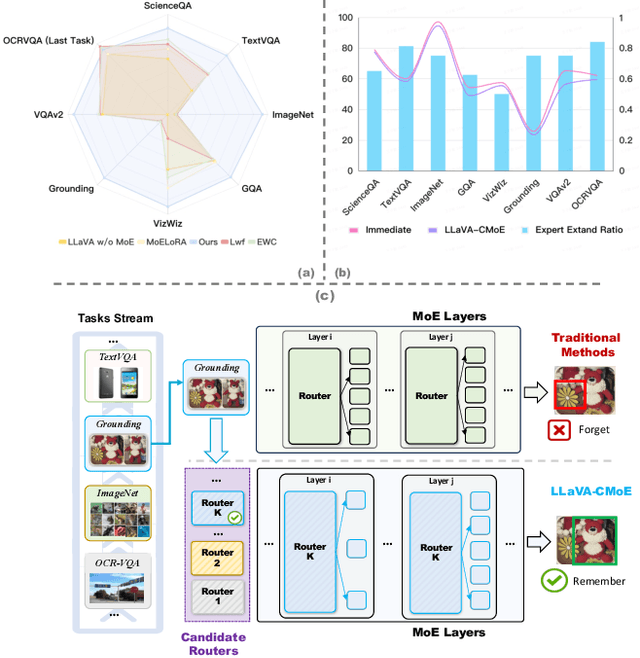
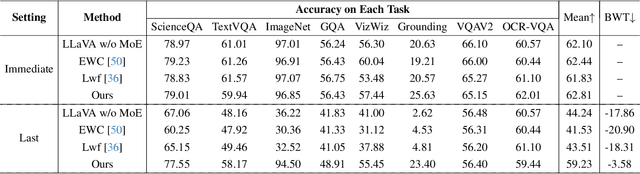
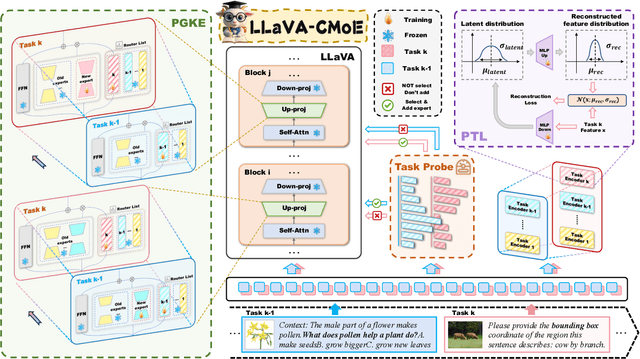
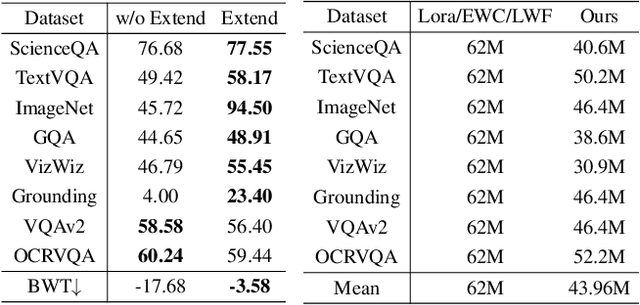
Although applying Mixture of Experts to large language models for learning new tasks is widely regarded as an effective strategy for continuous learning, there still remain two major challenges: (1) As the number of tasks grows, simple parameter expansion strategies can lead to excessively large models. (2) Modifying the parameters of the existing router results in the erosion of previously acquired knowledge. In this paper, we present an innovative framework named LLaVA-CMoE, which is a continuous Mixture of Experts (MoE) architecture without any replay data. Specifically, we have developed a method called Probe-Guided Knowledge Extension (PGKE), which employs probe experts to assess whether additional knowledge is required for a specific layer. This approach enables the model to adaptively expand its network parameters based on task distribution, thereby significantly improving the efficiency of parameter expansion. Additionally, we introduce a hierarchical routing algorithm called Probabilistic Task Locator (PTL), where high-level routing captures inter-task information and low-level routing focuses on intra-task details, ensuring that new task experts do not interfere with existing ones. Our experiments shows that our efficient architecture has substantially improved model performance on the Coin benchmark while maintaining a reasonable parameter count.
Revisit Parameter-Efficient Transfer Learning: A Two-Stage Paradigm
Mar 14, 2023



Parameter-Efficient Transfer Learning (PETL) aims at efficiently adapting large models pre-trained on massive data to downstream tasks with limited task-specific data. In view of the practicality of PETL, previous works focus on tuning a small set of parameters for each downstream task in an end-to-end manner while rarely considering the task distribution shift issue between the pre-training task and the downstream task. This paper proposes a novel two-stage paradigm, where the pre-trained model is first aligned to the target distribution. Then the task-relevant information is leveraged for effective adaptation. Specifically, the first stage narrows the task distribution shift by tuning the scale and shift in the LayerNorm layers. In the second stage, to efficiently learn the task-relevant information, we propose a Taylor expansion-based importance score to identify task-relevant channels for the downstream task and then only tune such a small portion of channels, making the adaptation to be parameter-efficient. Overall, we present a promising new direction for PETL, and the proposed paradigm achieves state-of-the-art performance on the average accuracy of 19 downstream tasks.
Evaluating the Generalization Ability of Super-Resolution Networks
May 14, 2022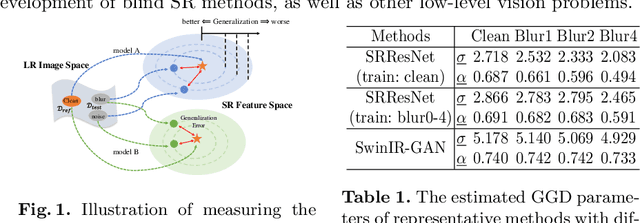


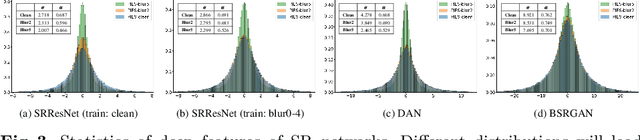
Performance and generalization ability are two important aspects to evaluate deep learning models. However, research on the generalization ability of Super-Resolution (SR) networks is currently absent. We make the first attempt to propose a Generalization Assessment Index for SR networks, namely SRGA. SRGA exploits the statistical characteristics of internal features of deep networks, not output images to measure the generalization ability. Specially, it is a non-parametric and non-learning metric. To better validate our method, we collect a patch-based image evaluation set (PIES) that includes both synthetic and real-world images, covering a wide range of degradations. With SRGA and PIES dataset, we benchmark existing SR models on the generalization ability. This work could lay the foundation for future research on model generalization in low-level vision.
Temporally Consistent Video Colorization with Deep Feature Propagation and Self-regularization Learning
Oct 09, 2021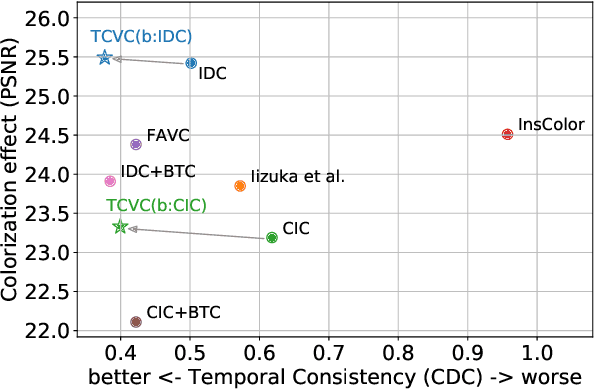
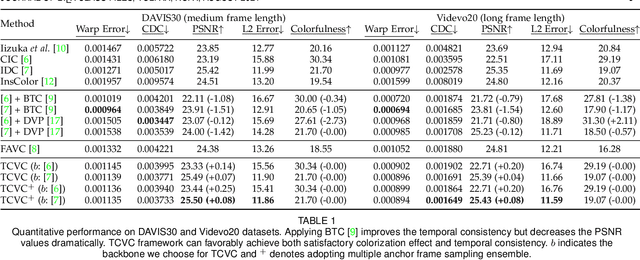

Video colorization is a challenging and highly ill-posed problem. Although recent years have witnessed remarkable progress in single image colorization, there is relatively less research effort on video colorization and existing methods always suffer from severe flickering artifacts (temporal inconsistency) or unsatisfying colorization performance. We address this problem from a new perspective, by jointly considering colorization and temporal consistency in a unified framework. Specifically, we propose a novel temporally consistent video colorization framework (TCVC). TCVC effectively propagates frame-level deep features in a bidirectional way to enhance the temporal consistency of colorization. Furthermore, TCVC introduces a self-regularization learning (SRL) scheme to minimize the prediction difference obtained with different time steps. SRL does not require any ground-truth color videos for training and can further improve temporal consistency. Experiments demonstrate that our method can not only obtain visually pleasing colorized video, but also achieve clearly better temporal consistency than state-of-the-art methods.
Color2Style: Real-Time Exemplar-Based Image Colorization with Self-Reference Learning and Deep Feature Modulation
Jun 16, 2021

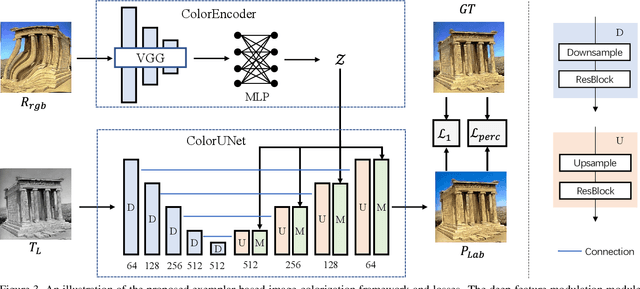
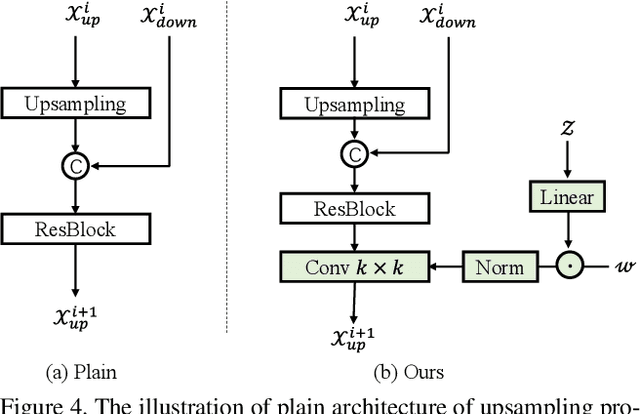
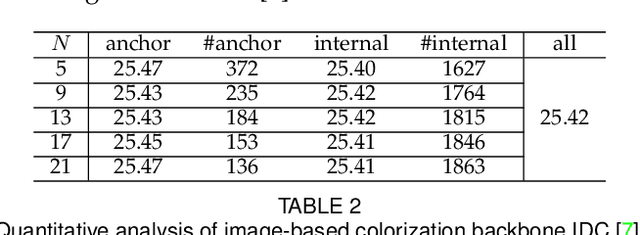
Legacy black-and-white photos are riddled with people's nostalgia and glorious memories of the past. To better relive the elapsed frozen moments, in this paper, we present a deep exemplar-based image colorization approach named Color2Style to resurrect these grayscale image media by filling them with vibrant colors. Generally, for exemplar-based colorization, unsupervised and unpaired training are usually adopted, due to the difficulty of obtaining input and ground truth image pairs. To train an exemplar-based colorization model, current algorithms usually strive to achieve two procedures: i) retrieving a large number of reference images with high similarity in advance, which is inevitably time-consuming and tedious; ii) designing complicated modules to transfer the colors of the reference image to the grayscale image, by calculating and leveraging the deep semantic correspondence between them (e.g., non-local operation). Contrary to the previous methods, we solve and simplify the above two steps in one end-to-end learning procedure. First, we adopt a self-augmented self-reference training scheme, where the reference image is generated by graphical transformations from the original colorful one whereby the training can be formulated in a paired manner. Second, instead of computing complex and inexplicable correspondence maps, our method exploits a simple yet effective deep feature modulation (DFM) module, which injects the color embeddings extracted from the reference image into the deep representations of the input grayscale image. Such design is much more lightweight and intelligible, achieving appealing performance with real-time processing speed. Moreover, our model does not require multifarious loss functions and regularization terms like existing methods, but only two widely used loss functions. Codes and models will be available at https://github.com/zhaohengyuan1/Color2Style.
Very Lightweight Photo Retouching Network with Conditional Sequential Modulation
Apr 13, 2021
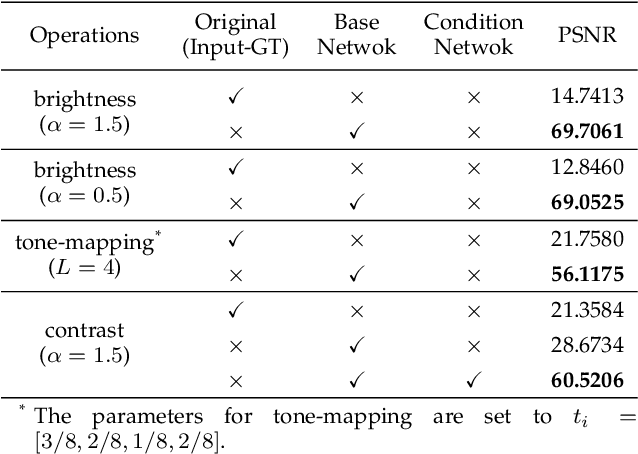
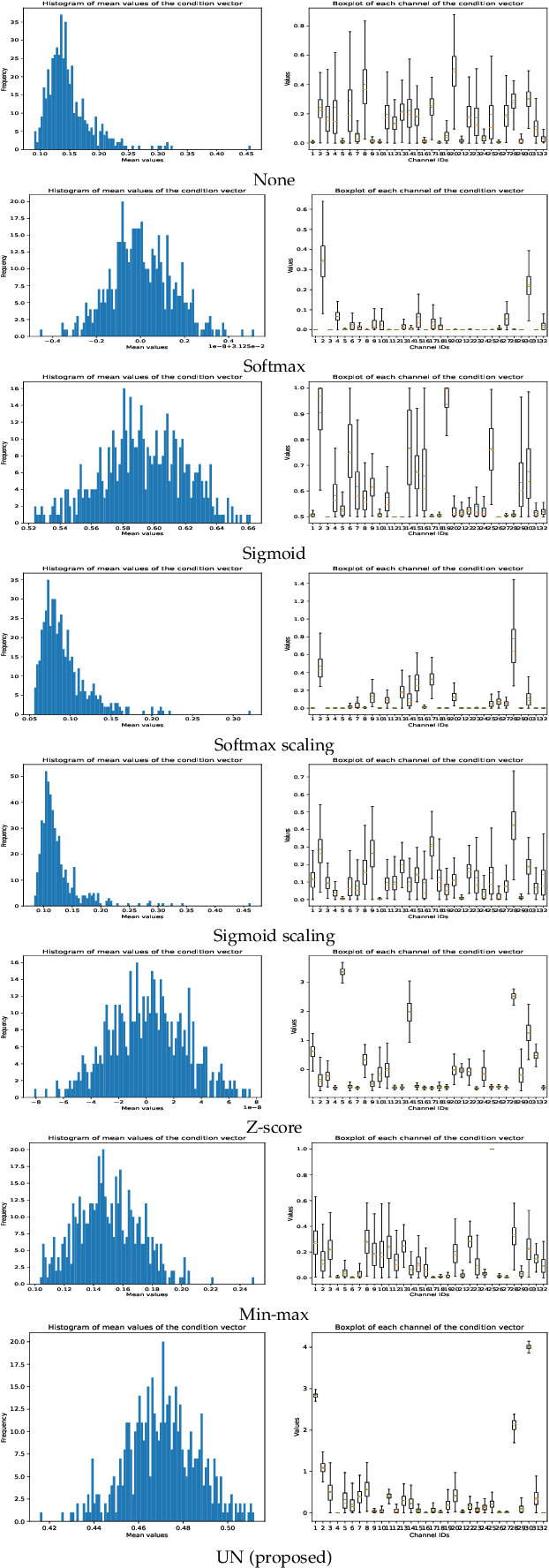
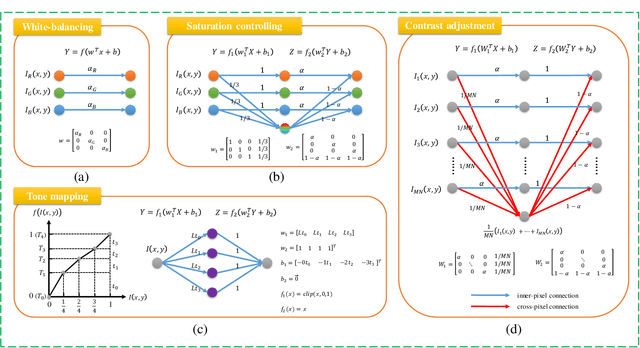
Photo retouching aims at improving the aesthetic visual quality of images that suffer from photographic defects such as poor contrast, over/under exposure, and inharmonious saturation. In practice, photo retouching can be accomplished by a series of image processing operations. As most commonly-used retouching operations are pixel-independent, i.e., the manipulation on one pixel is uncorrelated with its neighboring pixels, we can take advantage of this property and design a specialized algorithm for efficient global photo retouching. We analyze these global operations and find that they can be mathematically formulated by a Multi-Layer Perceptron (MLP). Based on this observation, we propose an extremely lightweight framework -- Conditional Sequential Retouching Network (CSRNet). Benefiting from the utilization of $1\times1$ convolution, CSRNet only contains less than 37K trainable parameters, which are orders of magnitude smaller than existing learning-based methods. Experiments show that our method achieves state-of-the-art performance on the benchmark MIT-Adobe FiveK dataset quantitively and qualitatively. In addition to achieve global photo retouching, the proposed framework can be easily extended to learn local enhancement effects. The extended model, namly CSRNet-L, also achieves competitive results in various local enhancement tasks. Codes will be available.
ClassSR: A General Framework to Accelerate Super-Resolution Networks by Data Characteristic
Mar 06, 2021
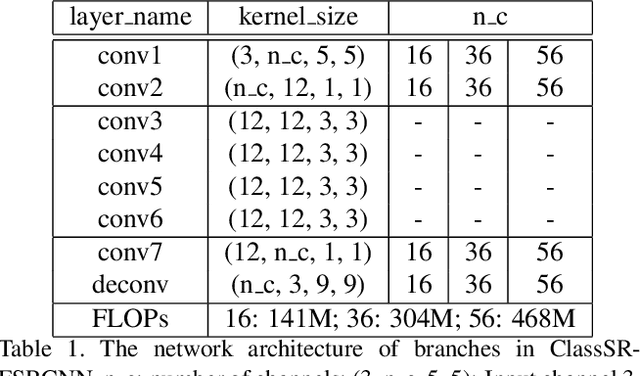
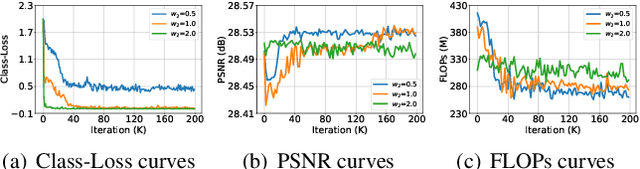
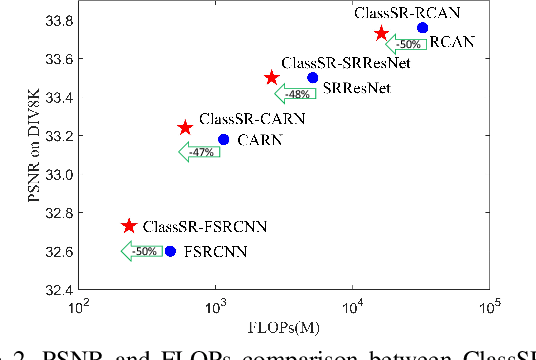
We aim at accelerating super-resolution (SR) networks on large images (2K-8K). The large images are usually decomposed into small sub-images in practical usages. Based on this processing, we found that different image regions have different restoration difficulties and can be processed by networks with different capacities. Intuitively, smooth areas are easier to super-solve than complex textures. To utilize this property, we can adopt appropriate SR networks to process different sub-images after the decomposition. On this basis, we propose a new solution pipeline -- ClassSR that combines classification and SR in a unified framework. In particular, it first uses a Class-Module to classify the sub-images into different classes according to restoration difficulties, then applies an SR-Module to perform SR for different classes. The Class-Module is a conventional classification network, while the SR-Module is a network container that consists of the to-be-accelerated SR network and its simplified versions. We further introduce a new classification method with two losses -- Class-Loss and Average-Loss to produce the classification results. After joint training, a majority of sub-images will pass through smaller networks, thus the computational cost can be significantly reduced. Experiments show that our ClassSR can help most existing methods (e.g., FSRCNN, CARN, SRResNet, RCAN) save up to 50% FLOPs on DIV8K datasets. This general framework can also be applied in other low-level vision tasks.
Efficient Image Super-Resolution Using Pixel Attention
Oct 02, 2020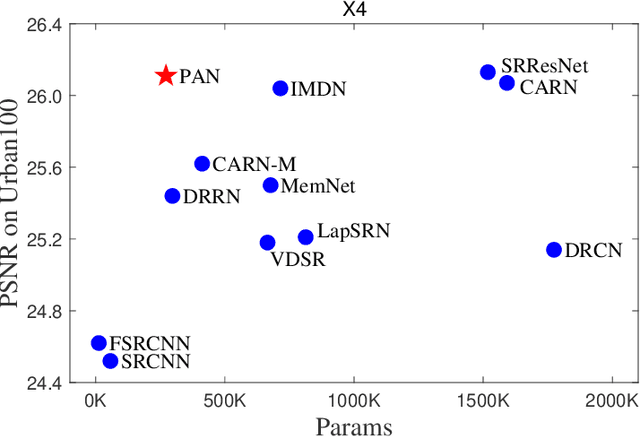
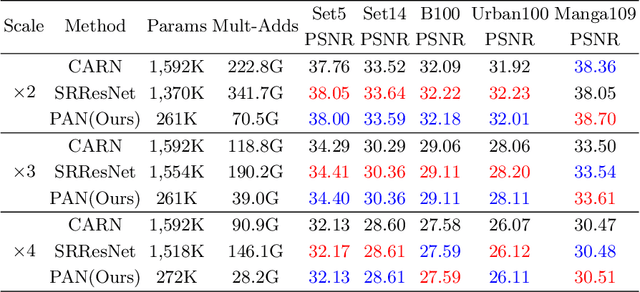
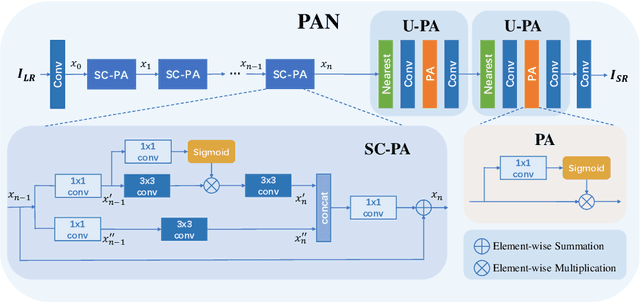
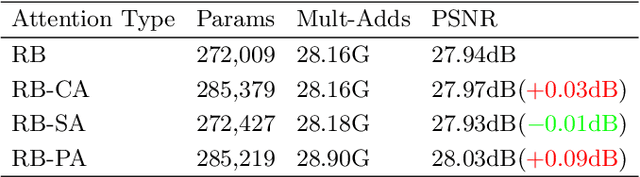
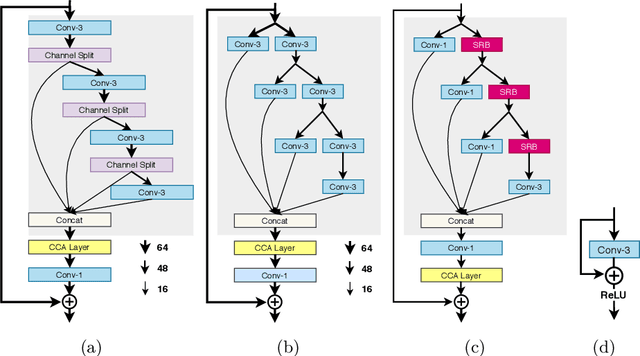
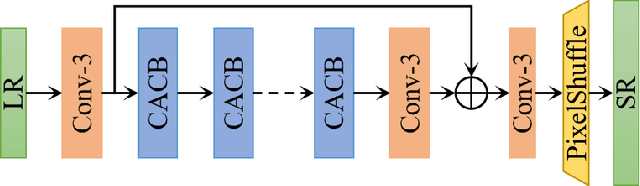
This work aims at designing a lightweight convolutional neural network for image super resolution (SR). With simplicity bare in mind, we construct a pretty concise and effective network with a newly proposed pixel attention scheme. Pixel attention (PA) is similar as channel attention and spatial attention in formulation. The difference is that PA produces 3D attention maps instead of a 1D attention vector or a 2D map. This attention scheme introduces fewer additional parameters but generates better SR results. On the basis of PA, we propose two building blocks for the main branch and the reconstruction branch, respectively. The first one - SC-PA block has the same structure as the Self-Calibrated convolution but with our PA layer. This block is much more efficient than conventional residual/dense blocks, for its twobranch architecture and attention scheme. While the second one - UPA block combines the nearest-neighbor upsampling, convolution and PA layers. It improves the final reconstruction quality with little parameter cost. Our final model- PAN could achieve similar performance as the lightweight networks - SRResNet and CARN, but with only 272K parameters (17.92% of SRResNet and 17.09% of CARN). The effectiveness of each proposed component is also validated by ablation study. The code is available at https://github.com/zhaohengyuan1/PAN.
AIM 2020 Challenge on Efficient Super-Resolution: Methods and Results
Sep 15, 2020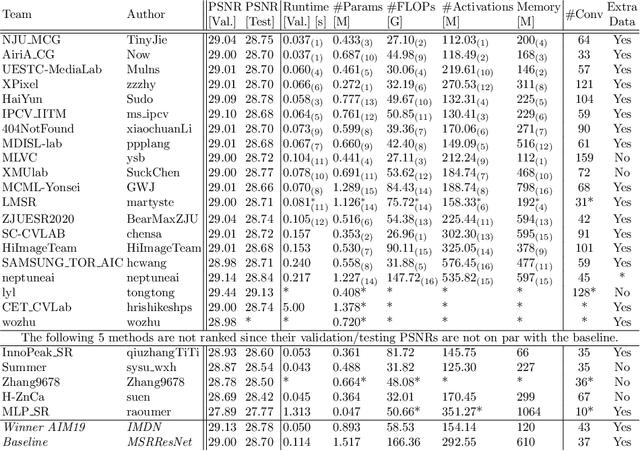
This paper reviews the AIM 2020 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The challenge task was to super-resolve an input image with a magnification factor x4 based on a set of prior examples of low and corresponding high resolution images. The goal is to devise a network that reduces one or several aspects such as runtime, parameter count, FLOPs, activations, and memory consumption while at least maintaining PSNR of MSRResNet. The track had 150 registered participants, and 25 teams submitted the final results. They gauge the state-of-the-art in efficient single image super-resolution.