 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Large Language Model based Intelligent Agents: Definitions, Methods, and Prospects
Jan 07, 2024Intelligent agents stand out as a potential path toward artificial general intelligence (AGI). Thus, researchers have dedicated significant effort to diverse implementations for them. Benefiting from recent progress in large language models (LLMs), LLM-based agents that use universal natural language as an interface exhibit robust generalization capabilities across various applications -- from serving as autonomous general-purpose task assistants to applications in coding, social, and economic domains, LLM-based agents offer extensive exploration opportunities. This paper surveys current research to provide an in-depth overview of LLM-based intelligent agents within single-agent and multi-agent systems. It covers their definitions, research frameworks, and foundational components such as their composition, cognitive and planning methods, tool utilization, and responses to environmental feedback. We also delve into the mechanisms of deploying LLM-based agents in multi-agent systems, including multi-role collaboration, message passing, and strategies to alleviate communication issues between agents. The discussions also shed light on popular datasets and application scenarios. We conclude by envisioning prospects for LLM-based agents, considering the evolving landscape of AI and natural language processing.
Towards Efficient SDRTV-to-HDRTV by Learning from Image Formation
Sep 08, 2023



Modern displays are capable of rendering video content with high dynamic range (HDR) and wide color gamut (WCG). However, the majority of available resources are still in standard dynamic range (SDR). As a result, there is significant value in transforming existing SDR content into the HDRTV standard. In this paper, we define and analyze the SDRTV-to-HDRTV task by modeling the formation of SDRTV/HDRTV content. Our analysis and observations indicate that a naive end-to-end supervised training pipeline suffers from severe gamut transition errors. To address this issue, we propose a novel three-step solution pipeline called HDRTVNet++, which includes adaptive global color mapping, local enhancement, and highlight refinement. The adaptive global color mapping step uses global statistics as guidance to perform image-adaptive color mapping. A local enhancement network is then deployed to enhance local details. Finally, we combine the two sub-networks above as a generator and achieve highlight consistency through GAN-based joint training. Our method is primarily designed for ultra-high-definition TV content and is therefore effective and lightweight for processing 4K resolution images. We also construct a dataset using HDR videos in the HDR10 standard, named HDRTV1K that contains 1235 and 117 training images and 117 testing images, all in 4K resolution. Besides, we select five metrics to evaluate the results of SDRTV-to-HDRTV algorithms. Our final results demonstrate state-of-the-art performance both quantitatively and visually. The code, model and dataset are available at https://github.com/xiaom233/HDRTVNet-plus.
A New Journey from SDRTV to HDRTV
Aug 18, 2021Nowadays modern displays are capable to render video content with high dynamic range (HDR) and wide color gamut (WCG). However, most available resources are still in standard dynamic range (SDR). Therefore, there is an urgent demand to transform existing SDR-TV contents into their HDR-TV versions. In this paper, we conduct an analysis of SDRTV-to-HDRTV task by modeling the formation of SDRTV/HDRTV content. Base on the analysis, we propose a three-step solution pipeline including adaptive global color mapping, local enhancement and highlight generation. Moreover, the above analysis inspires us to present a lightweight network that utilizes global statistics as guidance to conduct image-adaptive color mapping. In addition, we construct a dataset using HDR videos in HDR10 standard, named HDRTV1K, and select five metrics to evaluate the results of SDRTV-to-HDRTV algorithms. Furthermore, our final results achieve state-of-the-art performance in quantitative comparisons and visual quality. The code and dataset are available at https://github.com/chxy95/HDRTVNet.
HDRUNet: Single Image HDR Reconstruction with Denoising and Dequantization
Jun 19, 2021
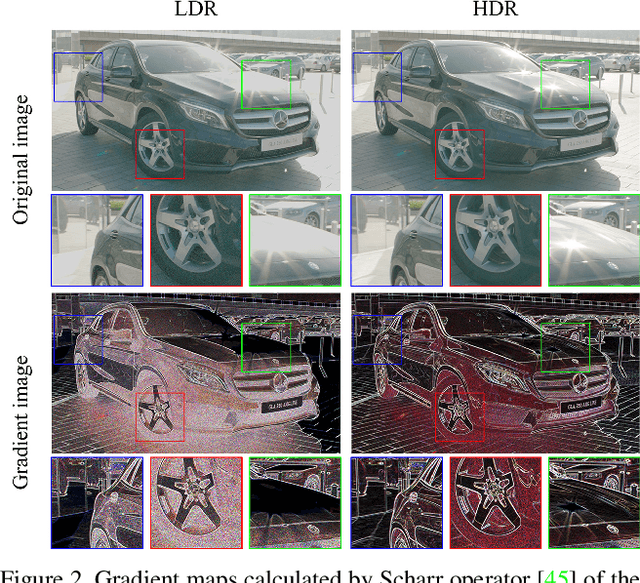
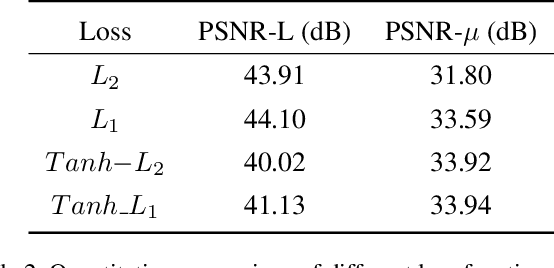

Most consumer-grade digital cameras can only capture a limited range of luminance in real-world scenes due to sensor constraints. Besides, noise and quantization errors are often introduced in the imaging process. In order to obtain high dynamic range (HDR) images with excellent visual quality, the most common solution is to combine multiple images with different exposures. However, it is not always feasible to obtain multiple images of the same scene and most HDR reconstruction methods ignore the noise and quantization loss. In this work, we propose a novel learning-based approach using a spatially dynamic encoder-decoder network, HDRUNet, to learn an end-to-end mapping for single image HDR reconstruction with denoising and dequantization. The network consists of a UNet-style base network to make full use of the hierarchical multi-scale information, a condition network to perform pattern-specific modulation and a weighting network for selectively retaining information. Moreover, we propose a Tanh_L1 loss function to balance the impact of over-exposed values and well-exposed values on the network learning. Our method achieves the state-of-the-art performance in quantitative comparisons and visual quality. The proposed HDRUNet model won the second place in the single frame track of NITRE2021 High Dynamic Range Challenge.
Very Lightweight Photo Retouching Network with Conditional Sequential Modulation
Apr 13, 2021
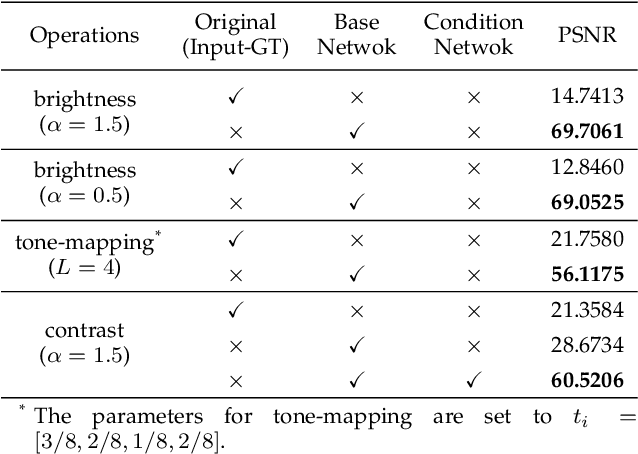
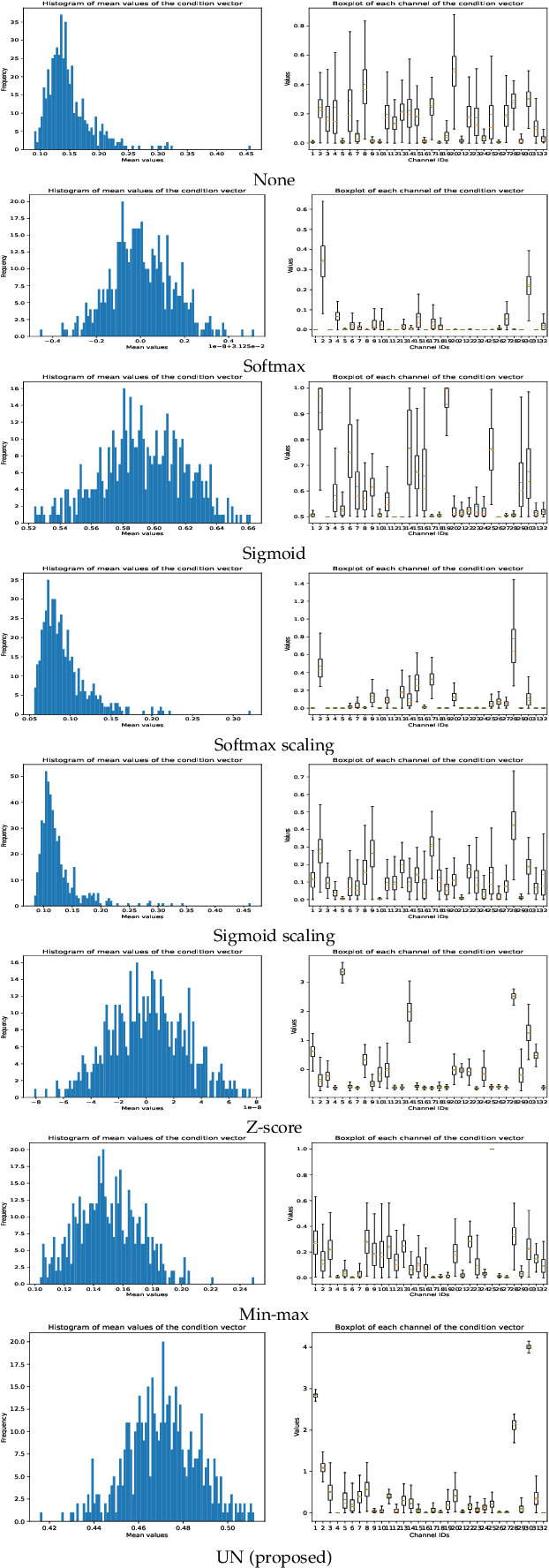
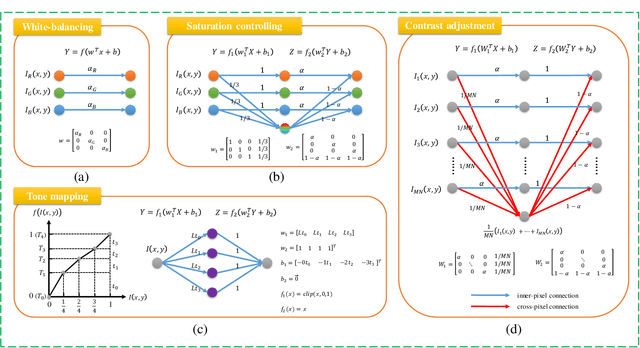
Photo retouching aims at improving the aesthetic visual quality of images that suffer from photographic defects such as poor contrast, over/under exposure, and inharmonious saturation. In practice, photo retouching can be accomplished by a series of image processing operations. As most commonly-used retouching operations are pixel-independent, i.e., the manipulation on one pixel is uncorrelated with its neighboring pixels, we can take advantage of this property and design a specialized algorithm for efficient global photo retouching. We analyze these global operations and find that they can be mathematically formulated by a Multi-Layer Perceptron (MLP). Based on this observation, we propose an extremely lightweight framework -- Conditional Sequential Retouching Network (CSRNet). Benefiting from the utilization of $1\times1$ convolution, CSRNet only contains less than 37K trainable parameters, which are orders of magnitude smaller than existing learning-based methods. Experiments show that our method achieves state-of-the-art performance on the benchmark MIT-Adobe FiveK dataset quantitively and qualitatively. In addition to achieve global photo retouching, the proposed framework can be easily extended to learn local enhancement effects. The extended model, namly CSRNet-L, also achieves competitive results in various local enhancement tasks. Codes will be available.