 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMKE-Coder: Multi-Axial Knowledge with Evidence Verification in ICD Coding for Chinese EMRs
Feb 19, 2025The task of automatically coding the International Classification of Diseases (ICD) in the medical field has been well-established and has received much attention. Automatic coding of the ICD in the medical field has been successful in English but faces challenges when dealing with Chinese electronic medical records (EMRs). The first issue lies in the difficulty of extracting disease code-related information from Chinese EMRs, primarily due to the concise writing style and specific internal structure of the EMRs. The second problem is that previous methods have failed to leverage the disease-based multi-axial knowledge and lack of association with the corresponding clinical evidence. This paper introduces a novel framework called MKE-Coder: Multi-axial Knowledge with Evidence verification in ICD coding for Chinese EMRs. Initially, we identify candidate codes for the diagnosis and categorize each of them into knowledge under four coding axes.Subsequently, we retrieve corresponding clinical evidence from the comprehensive content of EMRs and filter credible evidence through a scoring model. Finally, to ensure the validity of the candidate code, we propose an inference module based on the masked language modeling strategy. This module verifies that all the axis knowledge associated with the candidate code is supported by evidence and provides recommendations accordingly. To evaluate the performance of our framework, we conduct experiments using a large-scale Chinese EMR dataset collected from various hospitals. The experimental results demonstrate that MKE-Coder exhibits significant superiority in the task of automatic ICD coding based on Chinese EMRs. In the practical evaluation of our method within simulated real coding scenarios, it has been demonstrated that our approach significantly aids coders in enhancing both their coding accuracy and speed.
MIH-TCCT: Mitigating Inconsistent Hallucinations in LLMs via Event-Driven Text-Code Cyclic Training
Feb 13, 2025Recent methodologies utilizing synthetic datasets have aimed to address inconsistent hallucinations in large language models (LLMs); however,these approaches are primarily tailored to specific tasks, limiting their generalizability. Inspired by the strong performance of code-trained models in logic-intensive domains, we propose a novel framework that leverages event-based text to generate corresponding code and employs cyclic training to transfer the logical consistency of code to natural language effectively. Our method significantly reduces inconsistent hallucinations across three leading LLMs and two categories of natural language tasks while maintaining overall performance. This framework effectively alleviates hallucinations without necessitating adaptation to downstream tasks, demonstrating generality and providing new perspectives to tackle the challenge of inconsistent hallucinations.
THiFLY Research at SemEval-2023 Task 7: A Multi-granularity System for CTR-based Textual Entailment and Evidence Retrieval
Jun 02, 2023The NLI4CT task aims to entail hypotheses based on Clinical Trial Reports (CTRs) and retrieve the corresponding evidence supporting the justification. This task poses a significant challenge, as verifying hypotheses in the NLI4CT task requires the integration of multiple pieces of evidence from one or two CTR(s) and the application of diverse levels of reasoning, including textual and numerical. To address these problems, we present a multi-granularity system for CTR-based textual entailment and evidence retrieval in this paper. Specifically, we construct a Multi-granularity Inference Network (MGNet) that exploits sentence-level and token-level encoding to handle both textual entailment and evidence retrieval tasks. Moreover, we enhance the numerical inference capability of the system by leveraging a T5-based model, SciFive, which is pre-trained on the medical corpus. Model ensembling and a joint inference method are further utilized in the system to increase the stability and consistency of inference. The system achieves f1-scores of 0.856 and 0.853 on textual entailment and evidence retrieval tasks, resulting in the best performance on both subtasks. The experimental results corroborate the effectiveness of our proposed method. Our code is publicly available at https://github.com/THUMLP/NLI4CT.
Label-guided Learning for Text Classification
Feb 25, 2020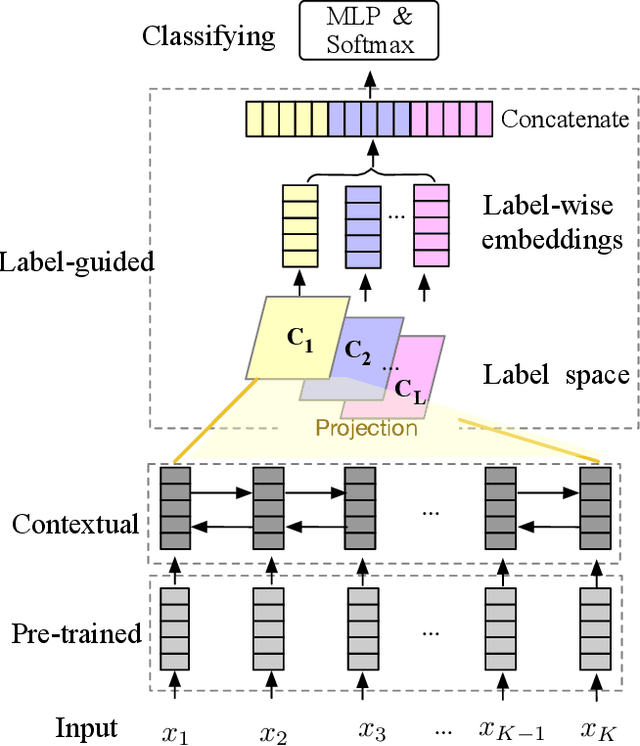
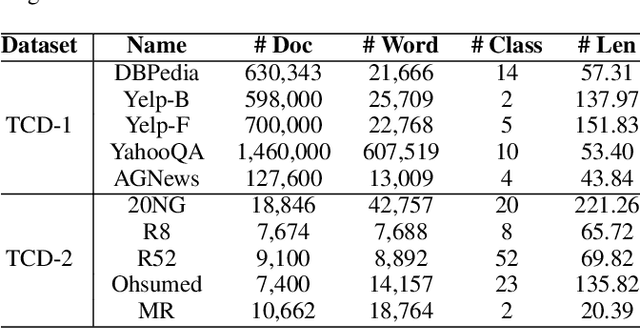
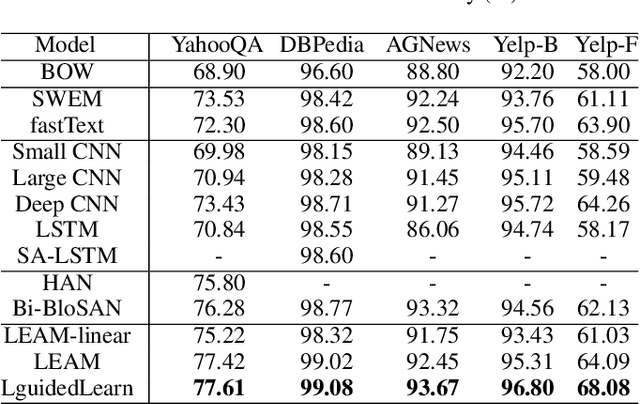
Text classification is one of the most important and fundamental tasks in natural language processing. Performance of this task mainly dependents on text representation learning. Currently, most existing learning frameworks mainly focus on encoding local contextual information between words. These methods always neglect to exploit global clues, such as label information, for encoding text information. In this study, we propose a label-guided learning framework LguidedLearn for text representation and classification. Our method is novel but simple that we only insert a label-guided encoding layer into the commonly used text representation learning schemas. That label-guided layer performs label-based attentive encoding to map the universal text embedding (encoded by a contextual information learner) into different label spaces, resulting in label-wise embeddings. In our proposed framework, the label-guided layer can be easily and directly applied with a contextual encoding method to perform jointly learning. Text information is encoded based on both the local contextual information and the global label clues. Therefore, the obtained text embeddings are more robust and discriminative for text classification. Extensive experiments are conducted on benchmark datasets to illustrate the effectiveness of our proposed method.
Tensor Graph Convolutional Networks for Text Classification
Jan 12, 2020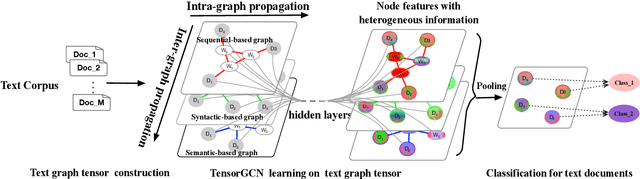


Compared to sequential learning models, graph-based neural networks exhibit some excellent properties, such as ability capturing global information. In this paper, we investigate graph-based neural networks for text classification problem. A new framework TensorGCN (tensor graph convolutional networks), is presented for this task. A text graph tensor is firstly constructed to describe semantic, syntactic, and sequential contextual information. Then, two kinds of propagation learning perform on the text graph tensor. The first is intra-graph propagation used for aggregating information from neighborhood nodes in a single graph. The second is inter-graph propagation used for harmonizing heterogeneous information between graphs. Extensive experiments are conducted on benchmark datasets, and the results illustrate the effectiveness of our proposed framework. Our proposed TensorGCN presents an effective way to harmonize and integrate heterogeneous information from different kinds of graphs.