 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplications of BERT Based Sequence Tagging Models on Chinese Medical Text Attributes Extraction
Aug 22, 2020
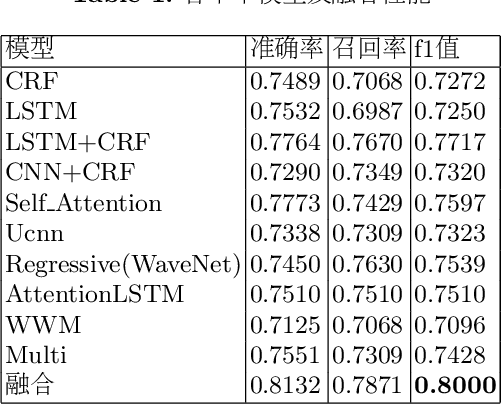


We convert the Chinese medical text attributes extraction task into a sequence tagging or machine reading comprehension task. Based on BERT pre-trained models, we have not only tried the widely used LSTM-CRF sequence tagging model, but also other sequence models, such as CNN, UCNN, WaveNet, SelfAttention, etc, which reaches similar performance as LSTM+CRF. This sheds a light on the traditional sequence tagging models. Since the aspect of emphasis for different sequence tagging models varies substantially, ensembling these models adds diversity to the final system. By doing so, our system achieves good performance on the task of Chinese medical text attributes extraction (subtask 2 of CCKS 2019 task 1).
Tensor Graph Convolutional Networks for Text Classification
Jan 12, 2020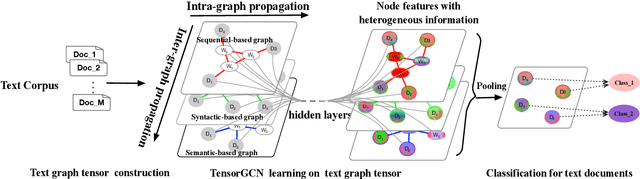


Compared to sequential learning models, graph-based neural networks exhibit some excellent properties, such as ability capturing global information. In this paper, we investigate graph-based neural networks for text classification problem. A new framework TensorGCN (tensor graph convolutional networks), is presented for this task. A text graph tensor is firstly constructed to describe semantic, syntactic, and sequential contextual information. Then, two kinds of propagation learning perform on the text graph tensor. The first is intra-graph propagation used for aggregating information from neighborhood nodes in a single graph. The second is inter-graph propagation used for harmonizing heterogeneous information between graphs. Extensive experiments are conducted on benchmark datasets, and the results illustrate the effectiveness of our proposed framework. Our proposed TensorGCN presents an effective way to harmonize and integrate heterogeneous information from different kinds of graphs.
Exploiting Sentence Embedding for Medical Question Answering
Nov 15, 2018
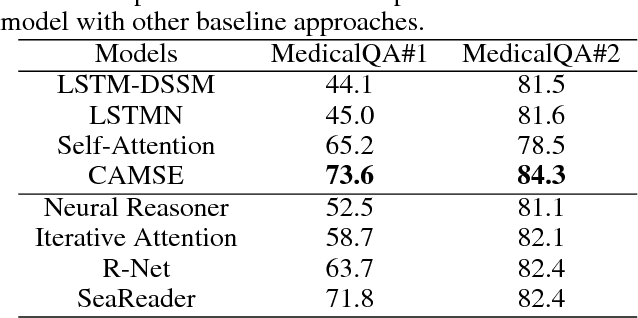


Despite the great success of word embedding, sentence embedding remains a not-well-solved problem. In this paper, we present a supervised learning framework to exploit sentence embedding for the medical question answering task. The learning framework consists of two main parts: 1) a sentence embedding producing module, and 2) a scoring module. The former is developed with contextual self-attention and multi-scale techniques to encode a sentence into an embedding tensor. This module is shortly called Contextual self-Attention Multi-scale Sentence Embedding (CAMSE). The latter employs two scoring strategies: Semantic Matching Scoring (SMS) and Semantic Association Scoring (SAS). SMS measures similarity while SAS captures association between sentence pairs: a medical question concatenated with a candidate choice, and a piece of corresponding supportive evidence. The proposed framework is examined by two Medical Question Answering(MedicalQA) datasets which are collected from real-world applications: medical exam and clinical diagnosis based on electronic medical records (EMR). The comparison results show that our proposed framework achieved significant improvements compared to competitive baseline approaches. Additionally, a series of controlled experiments are also conducted to illustrate that the multi-scale strategy and the contextual self-attention layer play important roles for producing effective sentence embedding, and the two kinds of scoring strategies are highly complementary to each other for question answering problems.