Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplications of BERT Based Sequence Tagging Models on Chinese Medical Text Attributes Extraction
Aug 22, 2020
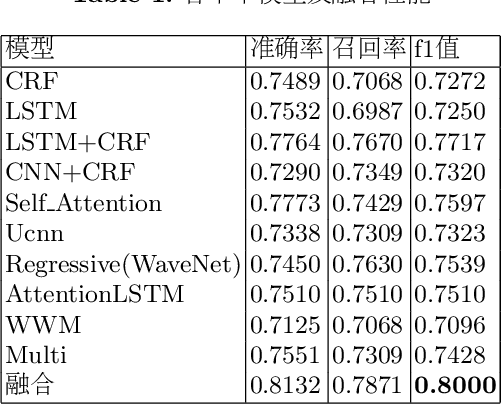


We convert the Chinese medical text attributes extraction task into a sequence tagging or machine reading comprehension task. Based on BERT pre-trained models, we have not only tried the widely used LSTM-CRF sequence tagging model, but also other sequence models, such as CNN, UCNN, WaveNet, SelfAttention, etc, which reaches similar performance as LSTM+CRF. This sheds a light on the traditional sequence tagging models. Since the aspect of emphasis for different sequence tagging models varies substantially, ensembling these models adds diversity to the final system. By doing so, our system achieves good performance on the task of Chinese medical text attributes extraction (subtask 2 of CCKS 2019 task 1).
* in Chinese language
Via