 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Normality Shifts: Risk-Aware Test-Time Adaptation for Unsupervised Tabular Anomaly Detection
May 11, 2026Unsupervised tabular anomaly detection methods typically learn feature patterns from normal samples during training and subsequently identify samples that deviate from these patterns as anomalies during testing. However, in practical scenarios, the limited scale and diversity of training data often lead to an incomplete characterization of normal patterns. While test-time adaptation offers a remedy, its isolated focus on test-time optimization ignores the critical synergy with training-phase learning. Furthermore, indiscriminate adaptation to unlabeled test data inevitably triggers anomaly contamination, preventing the model from fully realizing its discriminative capability between normal and anomalous samples. To address these issues, we propose RTTAD, a Risk-aware Test-time adaptation method for unsupervised Tabular Anomaly Detection. RTTAD holistically tackles normality shifts via a synergistic two-stage mechanism. During training, collaborative dual-task learning captures multi-level representations to establish a robust normal prior. During testing, a Test-Time Contrastive Learning (TTCL) module explicitly accounts for adaptation risk by selectively updating the model using high-confidence pseudo-normal samples while constraining anomalous ones. Additionally, TTCL incorporates a k-nearest neighbor-based contrastive objective to refine embedding distributions, thereby further enhancing the model's discriminative capacity. Extensive experiments on 15 tabular datasets demonstrate that RTTAD achieves state-of-the-art overall detection performance.
Enhancing Tabular Anomaly Detection via Pseudo-Label-Guided Generation
Apr 20, 2026Identifying anomalous instances in tabular data is essential for improving data reliability and maintaining system stability. Due to the scarcity of ground-truth anomaly labels, existing methods mainly rely on unsupervised anomaly detection models, or exploit a small number of labeled anomalies to facilitate detection via sample generation or contrastive learning. However, unsupervised methods lack sufficient anomaly awareness, while current generation and contrastive approaches tend to compute anomalies globally, overlooking the localized anomaly patterns of tabular features, resulting in suboptimal detection performance. To address these limitations, we propose PLAG, a pseudo-label-guided anomaly generation method designed to enhance tabular anomaly detection. Specifically, by utilizing pseudo-anomalies as guidance signals and decoupling the overall anomaly quantification of a sample into an accumulation of feature-level abnormalities, PLAG not only effectively obviates the need for scarce ground-truth labels but also provides a novel perspective for the model to comprehend localized anomalous signals at a fine-grained level. Furthermore, a two-stage data selection strategy is proposed, integrating format verification and uncertainty estimation to rigorously filter candidate samples, thereby ensuring the fidelity and diversity of the synthetic anomalies. Ultimately, these filtered synthetic anomalies serve as robust discriminative guidance, empowering the model to better separate normal and anomalous instances. Extensive experiments demonstrate that PLAG achieves state-of-the-art performance against eight representative baselines. Moreover, as a flexible framework, it integrates seamlessly with existing unsupervised detectors, consistently boosting F1-scores by 0.08 to 0.21.
From Continuous sEMG Signals to Discrete Muscle State Tokens: A Robust and Interpretable Representation Framework
Feb 27, 2026Surface electromyography (sEMG) signals exhibit substantial inter-subject variability and are highly susceptible to noise, posing challenges for robust and interpretable decoding. To address these limitations, we propose a discrete representation of sEMG signals based on a physiology-informed tokenization framework. The method employs a sliding window aligned with the minimal muscle contraction cycle to isolate individual muscle activation events. From each window, ten time-frequency features, including root mean square (RMS) and median frequency (MDF), are extracted, and K-means clustering is applied to group segments into representative muscle-state tokens. We also introduce a large-scale benchmark dataset, ActionEMG-43, comprising 43 diverse actions and sEMG recordings from 16 major muscle groups across the body. Based on this dataset, we conduct extensive evaluations to assess the inter-subject consistency, representation capacity, and interpretability of the proposed sEMG tokens. Our results show that the token representation exhibits high inter-subject consistency (Cohen's Kappa = 0.82+-0.09), indicating that the learned tokens capture consistent and subject-independent muscle activation patterns. In action recognition tasks, models using sEMG tokens achieve Top-1 accuracies of 75.5% with ViT and 67.9% with SVM, outperforming raw-signal baselines (72.8% and 64.4%, respectively), despite a 96% reduction in input dimensionality. In movement quality assessment, the tokens intuitively reveal patterns of muscle underactivation and compensatory activation, offering interpretable insights into neuromuscular control. Together, these findings highlight the effectiveness of tokenized sEMG representations as a compact, generalizable, and physiologically meaningful feature space for applications in rehabilitation, human-machine interaction, and motor function analysis.
Evaluating LLMs Across Multi-Cognitive Levels: From Medical Knowledge Mastery to Scenario-Based Problem Solving
Jun 10, 2025Large language models (LLMs) have demonstrated remarkable performance on various medical benchmarks, but their capabilities across different cognitive levels remain underexplored. Inspired by Bloom's Taxonomy, we propose a multi-cognitive-level evaluation framework for assessing LLMs in the medical domain in this study. The framework integrates existing medical datasets and introduces tasks targeting three cognitive levels: preliminary knowledge grasp, comprehensive knowledge application, and scenario-based problem solving. Using this framework, we systematically evaluate state-of-the-art general and medical LLMs from six prominent families: Llama, Qwen, Gemma, Phi, GPT, and DeepSeek. Our findings reveal a significant performance decline as cognitive complexity increases across evaluated models, with model size playing a more critical role in performance at higher cognitive levels. Our study highlights the need to enhance LLMs' medical capabilities at higher cognitive levels and provides insights for developing LLMs suited to real-world medical applications.
LLM Sensitivity Evaluation Framework for Clinical Diagnosis
Apr 18, 2025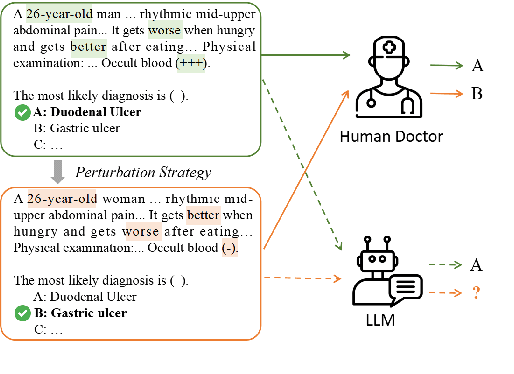
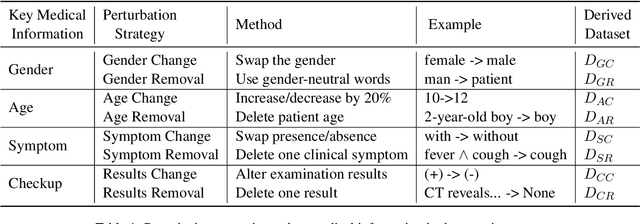
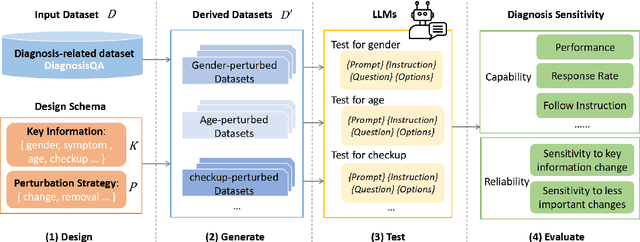
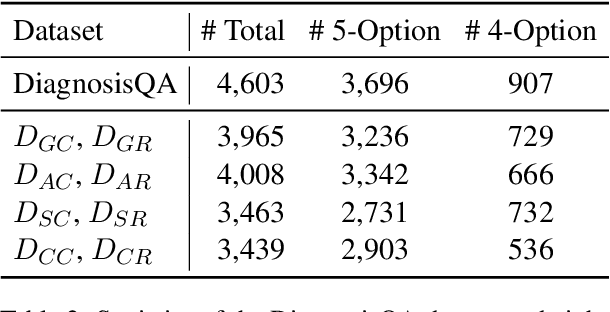
Large language models (LLMs) have demonstrated impressive performance across various domains. However, for clinical diagnosis, higher expectations are required for LLM's reliability and sensitivity: thinking like physicians and remaining sensitive to key medical information that affects diagnostic reasoning, as subtle variations can lead to different diagnosis results. Yet, existing works focus mainly on investigating the sensitivity of LLMs to irrelevant context and overlook the importance of key information. In this paper, we investigate the sensitivity of LLMs, i.e. GPT-3.5, GPT-4, Gemini, Claude3 and LLaMA2-7b, to key medical information by introducing different perturbation strategies. The evaluation results highlight the limitations of current LLMs in remaining sensitive to key medical information for diagnostic decision-making. The evolution of LLMs must focus on improving their reliability, enhancing their ability to be sensitive to key information, and effectively utilizing this information. These improvements will enhance human trust in LLMs and facilitate their practical application in real-world scenarios. Our code and dataset are available at https://github.com/chenwei23333/DiagnosisQA.
Data Augmentation Techniques for Chinese Disease Name Normalization
Jan 02, 2025


Disease name normalization is an important task in the medical domain. It classifies disease names written in various formats into standardized names, serving as a fundamental component in smart healthcare systems for various disease-related functions. Nevertheless, the most significant obstacle to existing disease name normalization systems is the severe shortage of training data. Consequently, we present a novel data augmentation approach that includes a series of data augmentation techniques and some supporting modules to help mitigate the problem. Through extensive experimentation, we illustrate that our proposed approach exhibits significant performance improvements across various baseline models and training objectives, particularly in scenarios with limited training data
Exploring semantic information in disease: Simple Data Augmentation Techniques for Chinese Disease Normalization
Jun 02, 2023



The disease is a core concept in the medical field, and the task of normalizing disease names is the basis of all disease-related tasks. However, due to the multi-axis and multi-grain nature of disease names, incorrect information is often injected and harms the performance when using general text data augmentation techniques. To address the above problem, we propose a set of data augmentation techniques that work together as an augmented training task for disease normalization. Our data augmentation methods are based on both the clinical disease corpus and standard disease corpus derived from ICD-10 coding. Extensive experiments are conducted to show the effectiveness of our proposed methods. The results demonstrate that our methods can have up to 3\% performance gain compared to non-augmented counterparts, and they can work even better on smaller datasets.
LMR-CBT: Learning Modality-fused Representations with CB-Transformer for Multimodal Emotion Recognition from Unaligned Multimodal Sequences
Dec 03, 2021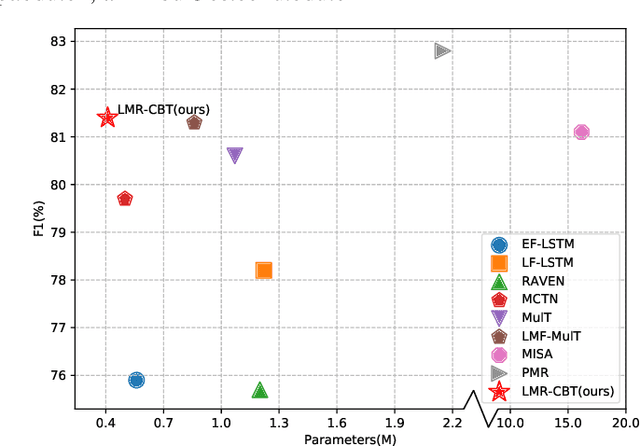
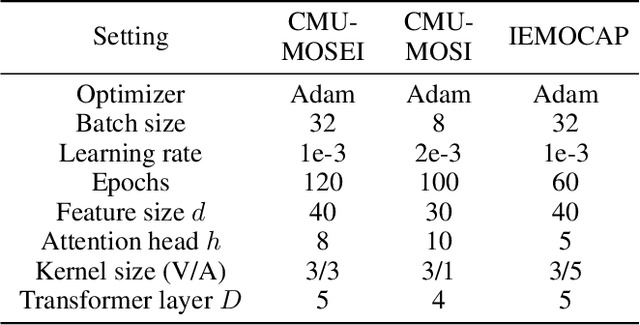
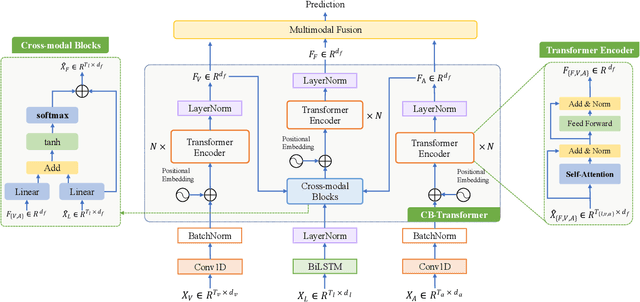
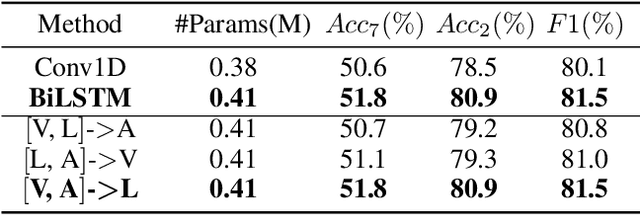
Learning modality-fused representations and processing unaligned multimodal sequences are meaningful and challenging in multimodal emotion recognition. Existing approaches use directional pairwise attention or a message hub to fuse language, visual, and audio modalities. However, those approaches introduce information redundancy when fusing features and are inefficient without considering the complementarity of modalities. In this paper, we propose an efficient neural network to learn modality-fused representations with CB-Transformer (LMR-CBT) for multimodal emotion recognition from unaligned multimodal sequences. Specifically, we first perform feature extraction for the three modalities respectively to obtain the local structure of the sequences. Then, we design a novel transformer with cross-modal blocks (CB-Transformer) that enables complementary learning of different modalities, mainly divided into local temporal learning,cross-modal feature fusion and global self-attention representations. In addition, we splice the fused features with the original features to classify the emotions of the sequences. Finally, we conduct word-aligned and unaligned experiments on three challenging datasets, IEMOCAP, CMU-MOSI, and CMU-MOSEI. The experimental results show the superiority and efficiency of our proposed method in both settings. Compared with the mainstream methods, our approach reaches the state-of-the-art with a minimum number of parameters.
A cross-modal fusion network based on self-attention and residual structure for multimodal emotion recognition
Nov 03, 2021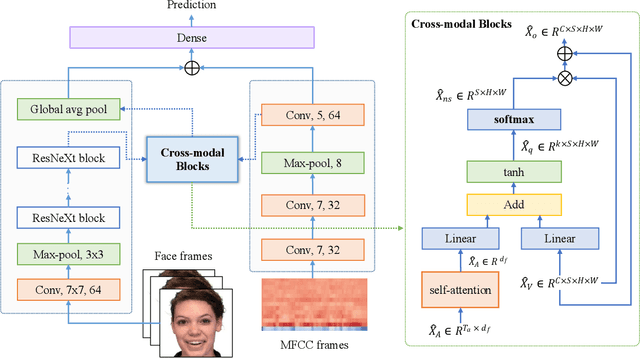
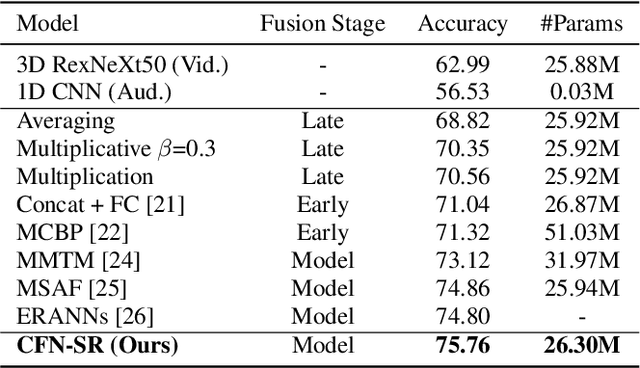
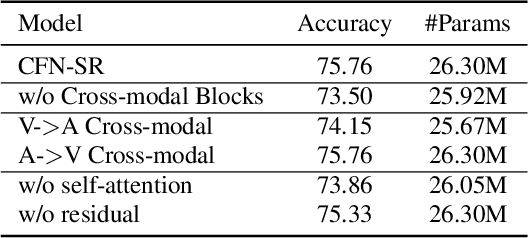
The audio-video based multimodal emotion recognition has attracted a lot of attention due to its robust performance. Most of the existing methods focus on proposing different cross-modal fusion strategies. However, these strategies introduce redundancy in the features of different modalities without fully considering the complementary properties between modal information, and these approaches do not guarantee the non-loss of original semantic information during intra- and inter-modal interactions. In this paper, we propose a novel cross-modal fusion network based on self-attention and residual structure (CFN-SR) for multimodal emotion recognition. Firstly, we perform representation learning for audio and video modalities to obtain the semantic features of the two modalities by efficient ResNeXt and 1D CNN, respectively. Secondly, we feed the features of the two modalities into the cross-modal blocks separately to ensure efficient complementarity and completeness of information through the self-attention mechanism and residual structure. Finally, we obtain the output of emotions by splicing the obtained fused representation with the original representation. To verify the effectiveness of the proposed method, we conduct experiments on the RAVDESS dataset. The experimental results show that the proposed CFN-SR achieves the state-of-the-art and obtains 75.76% accuracy with 26.30M parameters. Our code is available at https://github.com/skeletonNN/CFN-SR.