 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting AI-Generated Content in Academic Peer Reviews
Jan 30, 2026The growing availability of large language models (LLMs) has raised questions about their role in academic peer review. This study examines the temporal emergence of AI-generated content in peer reviews by applying a detection model trained on historical reviews to later review cycles at International Conference on Learning Representations (ICLR) and Nature Communications (NC). We observe minimal detection of AI-generated content before 2022, followed by a substantial increase through 2025, with approximately 20% of ICLR reviews and 12% of Nature Communications reviews classified as AI-generated in 2025. The most pronounced growth of AI-generated reviews in NC occurs between the third and fourth quarter of 2024. Together, these findings provide suggestive evidence of a rapidly increasing presence of AI-assisted content in peer review and highlight the need for further study of its implications for scholarly evaluation.
Hierarchical Structure-Property Alignment for Data-Efficient Molecular Generation and Editing
Nov 11, 2025Property-constrained molecular generation and editing are crucial in AI-driven drug discovery but remain hindered by two factors: (i) capturing the complex relationships between molecular structures and multiple properties remains challenging, and (ii) the narrow coverage and incomplete annotations of molecular properties weaken the effectiveness of property-based models. To tackle these limitations, we propose HSPAG, a data-efficient framework featuring hierarchical structure-property alignment. By treating SMILES and molecular properties as complementary modalities, the model learns their relationships at atom, substructure, and whole-molecule levels. Moreover, we select representative samples through scaffold clustering and hard samples via an auxiliary variational auto-encoder (VAE), substantially reducing the required pre-training data. In addition, we incorporate a property relevance-aware masking mechanism and diversified perturbation strategies to enhance generation quality under sparse annotations. Experiments demonstrate that HSPAG captures fine-grained structure-property relationships and supports controllable generation under multiple property constraints. Two real-world case studies further validate the editing capabilities of HSPAG.
$μ$NeuFMT: Optical-Property-Adaptive Fluorescence Molecular Tomography via Implicit Neural Representation
Nov 06, 2025Fluorescence Molecular Tomography (FMT) is a promising technique for non-invasive 3D visualization of fluorescent probes, but its reconstruction remains challenging due to the inherent ill-posedness and reliance on inaccurate or often-unknown tissue optical properties. While deep learning methods have shown promise, their supervised nature limits generalization beyond training data. To address these problems, we propose $\mu$NeuFMT, a self-supervised FMT reconstruction framework that integrates implicit neural-based scene representation with explicit physical modeling of photon propagation. Its key innovation lies in jointly optimize both the fluorescence distribution and the optical properties ($\mu$) during reconstruction, eliminating the need for precise prior knowledge of tissue optics or pre-conditioned training data. We demonstrate that $\mu$NeuFMT robustly recovers accurate fluorophore distributions and optical coefficients even with severely erroneous initial values (0.5$\times$ to 2$\times$ of ground truth). Extensive numerical, phantom, and in vivo validations show that $\mu$NeuFMT outperforms conventional and supervised deep learning approaches across diverse heterogeneous scenarios. Our work establishes a new paradigm for robust and accurate FMT reconstruction, paving the way for more reliable molecular imaging in complex clinically related scenarios, such as fluorescence guided surgery.
PerfDojo: Automated ML Library Generation for Heterogeneous Architectures
Nov 05, 2025



The increasing complexity of machine learning models and the proliferation of diverse hardware architectures (CPUs, GPUs, accelerators) make achieving optimal performance a significant challenge. Heterogeneity in instruction sets, specialized kernel requirements for different data types and model features (e.g., sparsity, quantization), and architecture-specific optimizations complicate performance tuning. Manual optimization is resource-intensive, while existing automatic approaches often rely on complex hardware-specific heuristics and uninterpretable intermediate representations, hindering performance portability. We introduce PerfLLM, a novel automatic optimization methodology leveraging Large Language Models (LLMs) and Reinforcement Learning (RL). Central to this is PerfDojo, an environment framing optimization as an RL game using a human-readable, mathematically-inspired code representation that guarantees semantic validity through transformations. This allows effective optimization without prior hardware knowledge, facilitating both human analysis and RL agent training. We demonstrate PerfLLM's ability to achieve significant performance gains across diverse CPU (x86, Arm, RISC-V) and GPU architectures.
YOLOv11-RGBT: Towards a Comprehensive Single-Stage Multispectral Object Detection Framework
Jun 18, 2025Multispectral object detection, which integrates information from multiple bands, can enhance detection accuracy and environmental adaptability, holding great application potential across various fields. Although existing methods have made progress in cross-modal interaction, low-light conditions, and model lightweight, there are still challenges like the lack of a unified single-stage framework, difficulty in balancing performance and fusion strategy, and unreasonable modality weight allocation. To address these, based on the YOLOv11 framework, we present YOLOv11-RGBT, a new comprehensive multimodal object detection framework. We designed six multispectral fusion modes and successfully applied them to models from YOLOv3 to YOLOv12 and RT-DETR. After reevaluating the importance of the two modalities, we proposed a P3 mid-fusion strategy and multispectral controllable fine-tuning (MCF) strategy for multispectral models. These improvements optimize feature fusion, reduce redundancy and mismatches, and boost overall model performance. Experiments show our framework excels on three major open-source multispectral object detection datasets, like LLVIP and FLIR. Particularly, the multispectral controllable fine-tuning strategy significantly enhanced model adaptability and robustness. On the FLIR dataset, it consistently improved YOLOv11 models' mAP by 3.41%-5.65%, reaching a maximum of 47.61%, verifying the framework and strategies' effectiveness. The code is available at: https://github.com/wandahangFY/YOLOv11-RGBT.
MARMOT: Masked Autoencoder for Modeling Transient Imaging
Jun 10, 2025



Pretrained models have demonstrated impressive success in many modalities such as language and vision. Recent works facilitate the pretraining paradigm in imaging research. Transients are a novel modality, which are captured for an object as photon counts versus arrival times using a precisely time-resolved sensor. In particular for non-line-of-sight (NLOS) scenarios, transients of hidden objects are measured beyond the sensor's direct line of sight. Using NLOS transients, the majority of previous works optimize volume density or surfaces to reconstruct the hidden objects and do not transfer priors learned from datasets. In this work, we present a masked autoencoder for modeling transient imaging, or MARMOT, to facilitate NLOS applications. Our MARMOT is a self-supervised model pretrianed on massive and diverse NLOS transient datasets. Using a Transformer-based encoder-decoder, MARMOT learns features from partially masked transients via a scanning pattern mask (SPM), where the unmasked subset is functionally equivalent to arbitrary sampling, and predicts full measurements. Pretrained on TransVerse-a synthesized transient dataset of 500K 3D models-MARMOT adapts to downstream imaging tasks using direct feature transfer or decoder finetuning. Comprehensive experiments are carried out in comparisons with state-of-the-art methods. Quantitative and qualitative results demonstrate the efficiency of our MARMOT.
TransiT: Transient Transformer for Non-line-of-sight Videography
Mar 14, 2025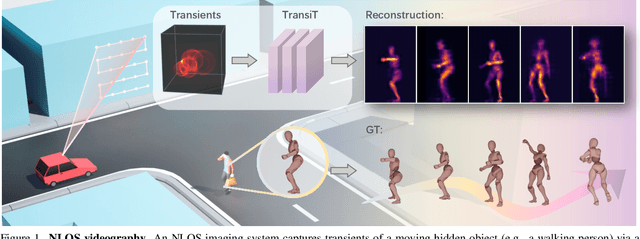
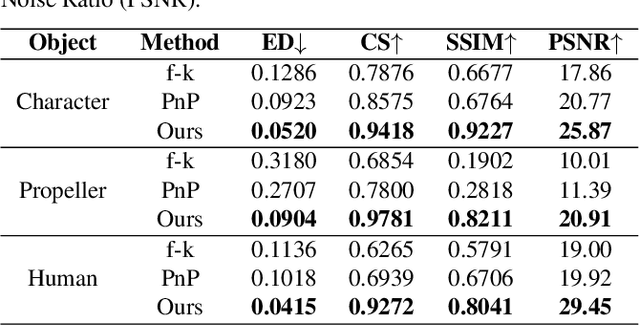
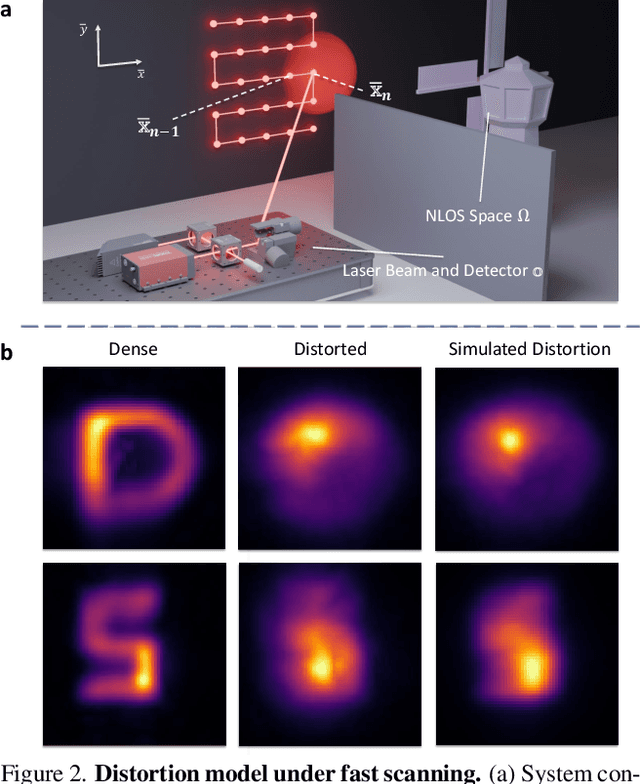
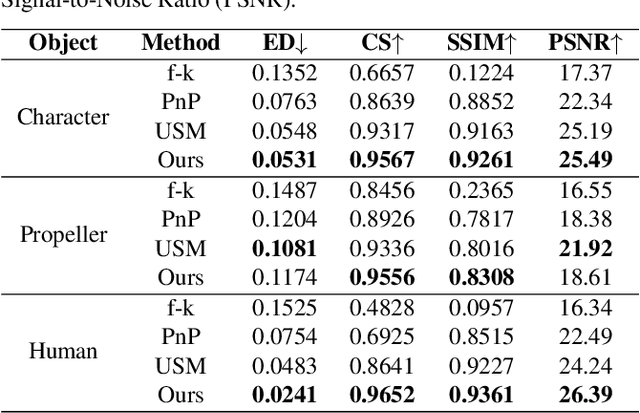
High quality and high speed videography using Non-Line-of-Sight (NLOS) imaging benefit autonomous navigation, collision prevention, and post-disaster search and rescue tasks. Current solutions have to balance between the frame rate and image quality. High frame rates, for example, can be achieved by reducing either per-point scanning time or scanning density, but at the cost of lowering the information density at individual frames. Fast scanning process further reduces the signal-to-noise ratio and different scanning systems exhibit different distortion characteristics. In this work, we design and employ a new Transient Transformer architecture called TransiT to achieve real-time NLOS recovery under fast scans. TransiT directly compresses the temporal dimension of input transients to extract features, reducing computation costs and meeting high frame rate requirements. It further adopts a feature fusion mechanism as well as employs a spatial-temporal Transformer to help capture features of NLOS transient videos. Moreover, TransiT applies transfer learning to bridge the gap between synthetic and real-measured data. In real experiments, TransiT manages to reconstruct from sparse transients of $16 \times 16$ measured at an exposure time of 0.4 ms per point to NLOS videos at a $64 \times 64$ resolution at 10 frames per second. We will make our code and dataset available to the community.
Robust Dynamic Facial Expression Recognition
Feb 22, 2025The study of Dynamic Facial Expression Recognition (DFER) is a nascent field of research that involves the automated recognition of facial expressions in video data. Although existing research has primarily focused on learning representations under noisy and hard samples, the issue of the coexistence of both types of samples remains unresolved. In order to overcome this challenge, this paper proposes a robust method of distinguishing between hard and noisy samples. This is achieved by evaluating the prediction agreement of the model on different sampled clips of the video. Subsequently, methodologies that reinforce the learning of hard samples and mitigate the impact of noisy samples can be employed. Moreover, to identify the principal expression in a video and enhance the model's capacity for representation learning, comprising a key expression re-sampling framework and a dual-stream hierarchical network is proposed, namely Robust Dynamic Facial Expression Recognition (RDFER). The key expression re-sampling framework is designed to identify the key expression, thereby mitigating the potential confusion caused by non-target expressions. RDFER employs two sequence models with the objective of disentangling short-term facial movements and long-term emotional changes. The proposed method has been shown to outperform current State-Of-The-Art approaches in DFER through extensive experimentation on benchmark datasets such as DFEW and FERV39K. A comprehensive analysis provides valuable insights and observations regarding the proposed agreement. This work has significant implications for the field of dynamic facial expression recognition and promotes the further development of the field of noise-consistent robust learning in dynamic facial expression recognition. The code is available from [https://github.com/Cross-Innovation-Lab/RDFER].
Emotion Neural Transducer for Fine-Grained Speech Emotion Recognition
Mar 28, 2024The mainstream paradigm of speech emotion recognition (SER) is identifying the single emotion label of the entire utterance. This line of works neglect the emotion dynamics at fine temporal granularity and mostly fail to leverage linguistic information of speech signal explicitly. In this paper, we propose Emotion Neural Transducer for fine-grained speech emotion recognition with automatic speech recognition (ASR) joint training. We first extend typical neural transducer with emotion joint network to construct emotion lattice for fine-grained SER. Then we propose lattice max pooling on the alignment lattice to facilitate distinguishing emotional and non-emotional frames. To adapt fine-grained SER to transducer inference manner, we further make blank, the special symbol of ASR, serve as underlying emotion indicator as well, yielding Factorized Emotion Neural Transducer. For typical utterance-level SER, our ENT models outperform state-of-the-art methods on IEMOCAP in low word error rate. Experiments on IEMOCAP and the latest speech emotion diarization dataset ZED also demonstrate the superiority of fine-grained emotion modeling. Our code is available at https://github.com/ECNU-Cross-Innovation-Lab/ENT.
EyeLS: Shadow-Guided Instrument Landing System for Intraocular Target Approaching in Robotic Eye Surgery
Nov 15, 2023Robotic ophthalmic surgery is an emerging technology to facilitate high-precision interventions such as retina penetration in subretinal injection and removal of floating tissues in retinal detachment depending on the input imaging modalities such as microscopy and intraoperative OCT (iOCT). Although iOCT is explored to locate the needle tip within its range-limited ROI, it is still difficult to coordinate iOCT's motion with the needle, especially at the initial target-approaching stage. Meanwhile, due to 2D perspective projection and thus the loss of depth information, current image-based methods cannot effectively estimate the needle tip's trajectory towards both retinal and floating targets. To address this limitation, we propose to use the shadow positions of the target and the instrument tip to estimate their relative depth position and accordingly optimize the instrument tip's insertion trajectory until the tip approaches targets within iOCT's scanning area. Our method succeeds target approaching on a retina model, and achieves an average depth error of 0.0127 mm and 0.3473 mm for floating and retinal targets respectively in the surgical simulator without damaging the retina.