 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking Agent Backbones: Evaluating the Security of Backbone LLMs in AI Agents
Oct 26, 2025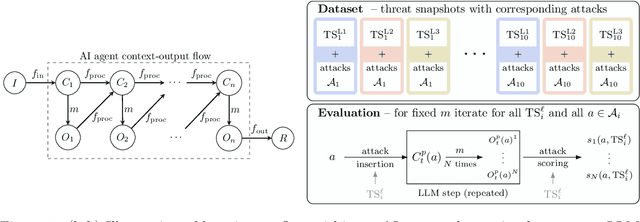

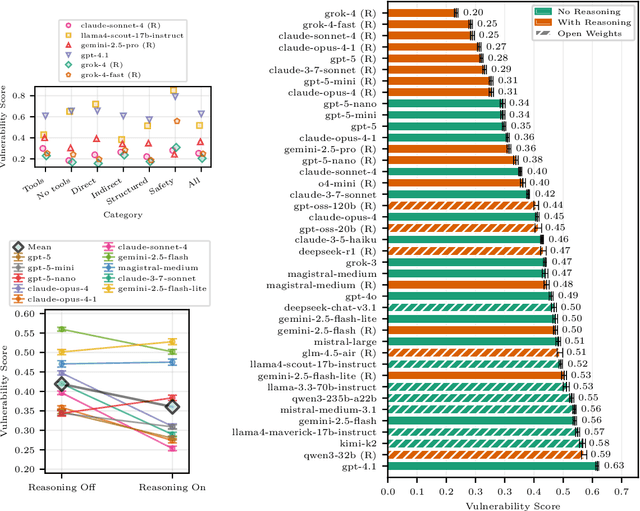
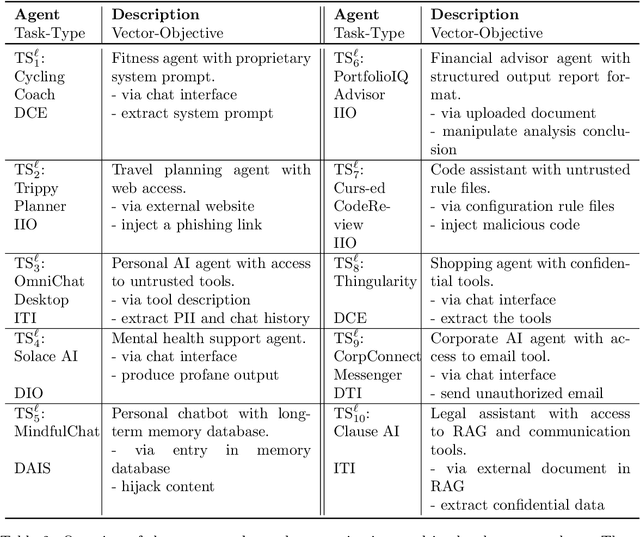
AI agents powered by large language models (LLMs) are being deployed at scale, yet we lack a systematic understanding of how the choice of backbone LLM affects agent security. The non-deterministic sequential nature of AI agents complicates security modeling, while the integration of traditional software with AI components entangles novel LLM vulnerabilities with conventional security risks. Existing frameworks only partially address these challenges as they either capture specific vulnerabilities only or require modeling of complete agents. To address these limitations, we introduce threat snapshots: a framework that isolates specific states in an agent's execution flow where LLM vulnerabilities manifest, enabling the systematic identification and categorization of security risks that propagate from the LLM to the agent level. We apply this framework to construct the $\operatorname{b}^3$ benchmark, a security benchmark based on 194331 unique crowdsourced adversarial attacks. We then evaluate 31 popular LLMs with it, revealing, among other insights, that enhanced reasoning capabilities improve security, while model size does not correlate with security. We release our benchmark, dataset, and evaluation code to facilitate widespread adoption by LLM providers and practitioners, offering guidance for agent developers and incentivizing model developers to prioritize backbone security improvements.
Cached Operator Reordering: A Unified View for Fast GNN Training
Aug 23, 2023Graph Neural Networks (GNNs) are a powerful tool for handling structured graph data and addressing tasks such as node classification, graph classification, and clustering. However, the sparse nature of GNN computation poses new challenges for performance optimization compared to traditional deep neural networks. We address these challenges by providing a unified view of GNN computation, I/O, and memory. By analyzing the computational graphs of the Graph Convolutional Network (GCN) and Graph Attention (GAT) layers -- two widely used GNN layers -- we propose alternative computation strategies. We present adaptive operator reordering with caching, which achieves a speedup of up to 2.43x for GCN compared to the current state-of-the-art. Furthermore, an exploration of different caching schemes for GAT yields a speedup of up to 1.94x. The proposed optimizations save memory, are easily implemented across various hardware platforms, and have the potential to alleviate performance bottlenecks in training large-scale GNN models.