 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Structural Recovery Parameters Enhance Prediction of Visual Outcomes After Macular Hole Surgery
Sep 11, 2025Purpose: To introduce novel dynamic structural parameters and evaluate their integration within a multimodal deep learning (DL) framework for predicting postoperative visual recovery in idiopathic full-thickness macular hole (iFTMH) patients. Methods: We utilized a publicly available longitudinal OCT dataset at five stages (preoperative, 2 weeks, 3 months, 6 months, and 12 months). A stage specific segmentation model delineated related structures, and an automated pipeline extracted quantitative, composite, qualitative, and dynamic features. Binary logistic regression models, constructed with and without dynamic parameters, assessed their incremental predictive value for best-corrected visual acuity (BCVA). A multimodal DL model combining clinical variables, OCT-derived features, and raw OCT images was developed and benchmarked against regression models. Results: The segmentation model achieved high accuracy across all timepoints (mean Dice > 0.89). Univariate and multivariate analyses identified base diameter, ellipsoid zone integrity, and macular hole area as significant BCVA predictors (P < 0.05). Incorporating dynamic recovery rates consistently improved logistic regression AUC, especially at the 3-month follow-up. The multimodal DL model outperformed logistic regression, yielding higher AUCs and overall accuracy at each stage. The difference is as high as 0.12, demonstrating the complementary value of raw image volume and dynamic parameters. Conclusions: Integrating dynamic parameters into the multimodal DL model significantly enhances the accuracy of predictions. This fully automated process therefore represents a promising clinical decision support tool for personalized postoperative management in macular hole surgery.
CLAPS: A CLIP-Unified Auto-Prompt Segmentation for Multi-Modal Retinal Imaging
Sep 10, 2025Recent advancements in foundation models, such as the Segment Anything Model (SAM), have significantly impacted medical image segmentation, especially in retinal imaging, where precise segmentation is vital for diagnosis. Despite this progress, current methods face critical challenges: 1) modality ambiguity in textual disease descriptions, 2) a continued reliance on manual prompting for SAM-based workflows, and 3) a lack of a unified framework, with most methods being modality- and task-specific. To overcome these hurdles, we propose CLIP-unified Auto-Prompt Segmentation (\CLAPS), a novel method for unified segmentation across diverse tasks and modalities in retinal imaging. Our approach begins by pre-training a CLIP-based image encoder on a large, multi-modal retinal dataset to handle data scarcity and distribution imbalance. We then leverage GroundingDINO to automatically generate spatial bounding box prompts by detecting local lesions. To unify tasks and resolve ambiguity, we use text prompts enhanced with a unique "modality signature" for each imaging modality. Ultimately, these automated textual and spatial prompts guide SAM to execute precise segmentation, creating a fully automated and unified pipeline. Extensive experiments on 12 diverse datasets across 11 critical segmentation categories show that CLAPS achieves performance on par with specialized expert models while surpassing existing benchmarks across most metrics, demonstrating its broad generalizability as a foundation model.
UOPSL: Unpaired OCT Predilection Sites Learning for Fundus Image Diagnosis Augmentation
Sep 10, 2025Significant advancements in AI-driven multimodal medical image diagnosis have led to substantial improvements in ophthalmic disease identification in recent years. However, acquiring paired multimodal ophthalmic images remains prohibitively expensive. While fundus photography is simple and cost-effective, the limited availability of OCT data and inherent modality imbalance hinder further progress. Conventional approaches that rely solely on fundus or textual features often fail to capture fine-grained spatial information, as each imaging modality provides distinct cues about lesion predilection sites. In this study, we propose a novel unpaired multimodal framework \UOPSL that utilizes extensive OCT-derived spatial priors to dynamically identify predilection sites, enhancing fundus image-based disease recognition. Our approach bridges unpaired fundus and OCTs via extended disease text descriptions. Initially, we employ contrastive learning on a large corpus of unpaired OCT and fundus images while simultaneously learning the predilection sites matrix in the OCT latent space. Through extensive optimization, this matrix captures lesion localization patterns within the OCT feature space. During the fine-tuning or inference phase of the downstream classification task based solely on fundus images, where paired OCT data is unavailable, we eliminate OCT input and utilize the predilection sites matrix to assist in fundus image classification learning. Extensive experiments conducted on 9 diverse datasets across 28 critical categories demonstrate that our framework outperforms existing benchmarks.
AgentAlign: Misalignment-Adapted Multi-Agent Perception for Resilient Inter-Agent Sensor Correlations
Dec 09, 2024Cooperative perception has attracted wide attention given its capability to leverage shared information across connected automated vehicles (CAVs) and smart infrastructures to address sensing occlusion and range limitation issues. However, existing research overlooks the fragile multi-sensor correlations in multi-agent settings, as the heterogeneous agent sensor measurements are highly susceptible to environmental factors, leading to weakened inter-agent sensor interactions. The varying operational conditions and other real-world factors inevitably introduce multifactorial noise and consequentially lead to multi-sensor misalignment, making the deployment of multi-agent multi-modality perception particularly challenging in the real world. In this paper, we propose AgentAlign, a real-world heterogeneous agent cross-modality feature alignment framework, to effectively address these multi-modality misalignment issues. Our method introduces a cross-modality feature alignment space (CFAS) and heterogeneous agent feature alignment (HAFA) mechanism to harmonize multi-modality features across various agents dynamically. Additionally, we present a novel V2XSet-noise dataset that simulates realistic sensor imperfections under diverse environmental conditions, facilitating a systematic evaluation of our approach's robustness. Extensive experiments on the V2X-Real and V2XSet-Noise benchmarks demonstrate that our framework achieves state-of-the-art performance, underscoring its potential for real-world applications in cooperative autonomous driving. The controllable V2XSet-Noise dataset and generation pipeline will be released in the future.
Extrapolating Prospective Glaucoma Fundus Images through Diffusion Model in Irregular Longitudinal Sequences
Oct 28, 2024



The utilization of longitudinal datasets for glaucoma progression prediction offers a compelling approach to support early therapeutic interventions. Predominant methodologies in this domain have primarily focused on the direct prediction of glaucoma stage labels from longitudinal datasets. However, such methods may not adequately encapsulate the nuanced developmental trajectory of the disease. To enhance the diagnostic acumen of medical practitioners, we propose a novel diffusion-based model to predict prospective images by extrapolating from existing longitudinal fundus images of patients. The methodology delineated in this study distinctively leverages sequences of images as inputs. Subsequently, a time-aligned mask is employed to select a specific year for image generation. During the training phase, the time-aligned mask resolves the issue of irregular temporal intervals in longitudinal image sequence sampling. Additionally, we utilize a strategy of randomly masking a frame in the sequence to establish the ground truth. This methodology aids the network in continuously acquiring knowledge regarding the internal relationships among the sequences throughout the learning phase. Moreover, the introduction of textual labels is instrumental in categorizing images generated within the sequence. The empirical findings from the conducted experiments indicate that our proposed model not only effectively generates longitudinal data but also significantly improves the precision of downstream classification tasks.
KaLDeX: Kalman Filter based Linear Deformable Cross Attention for Retina Vessel Segmentation
Oct 28, 2024Background and Objective: In the realm of ophthalmic imaging, accurate vascular segmentation is paramount for diagnosing and managing various eye diseases. Contemporary deep learning-based vascular segmentation models rival human accuracy but still face substantial challenges in accurately segmenting minuscule blood vessels in neural network applications. Due to the necessity of multiple downsampling operations in the CNN models, fine details from high-resolution images are inevitably lost. The objective of this study is to design a structure to capture the delicate and small blood vessels. Methods: To address these issues, we propose a novel network (KaLDeX) for vascular segmentation leveraging a Kalman filter based linear deformable cross attention (LDCA) module, integrated within a UNet++ framework. Our approach is based on two key components: Kalman filter (KF) based linear deformable convolution (LD) and cross-attention (CA) modules. The LD module is designed to adaptively adjust the focus on thin vessels that might be overlooked in standard convolution. The CA module improves the global understanding of vascular structures by aggregating the detailed features from the LD module with the high level features from the UNet++ architecture. Finally, we adopt a topological loss function based on persistent homology to constrain the topological continuity of the segmentation. Results: The proposed method is evaluated on retinal fundus image datasets (DRIVE, CHASE_BD1, and STARE) as well as the 3mm and 6mm of the OCTA-500 dataset, achieving an average accuracy (ACC) of 97.25%, 97.77%, 97.85%, 98.89%, and 98.21%, respectively. Conclusions: Empirical evidence shows that our method outperforms the current best models on different vessel segmentation datasets. Our source code is available at: https://github.com/AIEyeSystem/KalDeX.
AI-Based Fully Automatic Analysis of Retinal Vascular Morphology in Pediatric High Myopia
Sep 30, 2024Purpose: To investigate the changes in retinal vascular structures associated various stages of myopia by designing automated software based on an artif intelligencemodel. Methods: The study involved 1324 pediatric participants from the National Childr Medical Center in China, and 2366 high-quality retinal images and correspon refractive parameters were obtained and analyzed. Spherical equivalent refrac(SER) degree was calculated. We proposed a data analysis model based c combination of the Convolutional Neural Networks (CNN) model and the atter module to classify images, segment vascular structures, and measure vasc parameters, such as main angle (MA), branching angle (BA), bifurcation edge al(BEA) and bifurcation edge coefficient (BEC). One-way ANOVA compared param measurements betweenthenormalfundus,lowmyopia,moderate myopia,and high myopia group. Results: There were 279 (12.38%) images in normal group and 384 (16.23%) images in the high myopia group. Compared normal fundus, the MA of fundus vessels in different myopic refractive groups significantly reduced (P = 0.006, P = 0.004, P = 0.019, respectively), and performance of the venous system was particularly obvious (P<0.001). At the sa time, the BEC decreased disproportionately (P<0.001). Further analysis of fundus vascular parameters at different degrees of myopia showed that there were also significant differences in BA and branching coefficient (BC). The arterial BA value of the fundus vessel in the high myopia group was lower than that of other groups (P : 0.032, 95% confidence interval [Ci], 0.22-4.86), while the venous BA values increased(P = 0.026). The BEC values of high myopia were higher than those of low and moderate myopia groups. When the loss function of our data classification model converged to 0.09,the model accuracy reached 94.19%
EyeLS: Shadow-Guided Instrument Landing System for Intraocular Target Approaching in Robotic Eye Surgery
Nov 15, 2023Robotic ophthalmic surgery is an emerging technology to facilitate high-precision interventions such as retina penetration in subretinal injection and removal of floating tissues in retinal detachment depending on the input imaging modalities such as microscopy and intraoperative OCT (iOCT). Although iOCT is explored to locate the needle tip within its range-limited ROI, it is still difficult to coordinate iOCT's motion with the needle, especially at the initial target-approaching stage. Meanwhile, due to 2D perspective projection and thus the loss of depth information, current image-based methods cannot effectively estimate the needle tip's trajectory towards both retinal and floating targets. To address this limitation, we propose to use the shadow positions of the target and the instrument tip to estimate their relative depth position and accordingly optimize the instrument tip's insertion trajectory until the tip approaches targets within iOCT's scanning area. Our method succeeds target approaching on a retina model, and achieves an average depth error of 0.0127 mm and 0.3473 mm for floating and retinal targets respectively in the surgical simulator without damaging the retina.
Deep Autoencoder Model Construction Based on Pytorch
Aug 17, 2022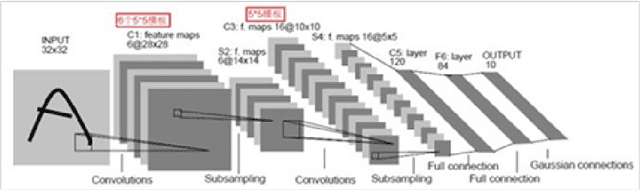
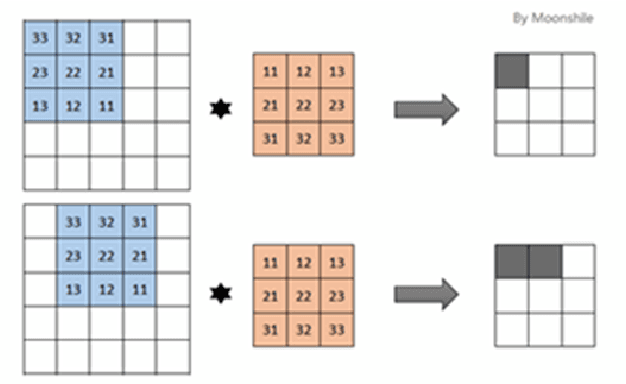
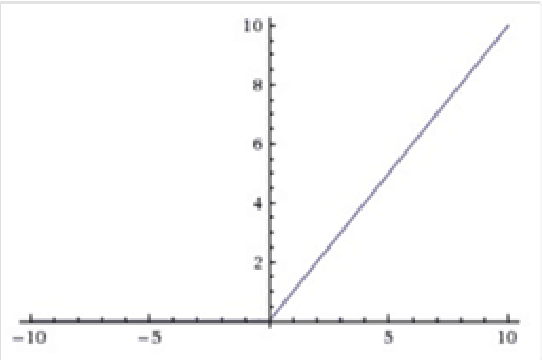
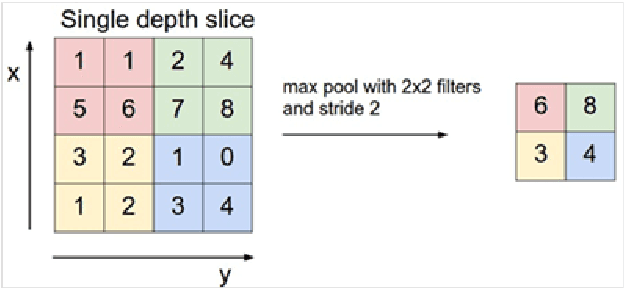
This paper proposes a deep autoencoder model based on Pytorch. This algorithm introduces the idea of Pytorch into the auto-encoder, and randomly clears the input weights connected to the hidden layer neurons with a certain probability, so as to achieve the effect of sparse network, which is similar to the starting point of the sparse auto-encoder. The new algorithm effectively solves the problem of possible overfitting of the model and improves the accuracy of image classification. Finally, the experiment is carried out, and the experimental results are compared with ELM, RELM, AE, SAE, DAE.
Research on restaurant recommendation using machine learning
Aug 10, 2022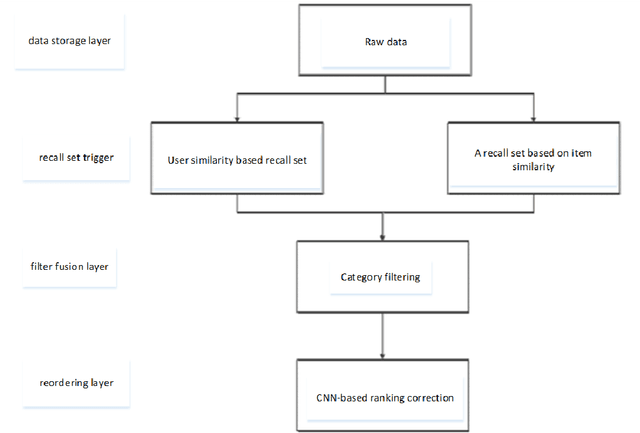



A recommender system is a system that helps users filter irrelevant information and create user interest models based on their historical records. With the continuous development of Internet information, recommendation systems have received widespread attention in the industry. In this era of ubiquitous data and information, how to obtain and analyze these data has become the research topic of many people. In view of this situation, this paper makes some brief overviews of machine learning-related recommendation systems. By analyzing some technologies and ideas used by machine learning in recommender systems, let more people understand what is Big data and what is machine learning. The most important point is to let everyone understand the profound impact of machine learning on our daily life.