 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransiT: Transient Transformer for Non-line-of-sight Videography
Mar 14, 2025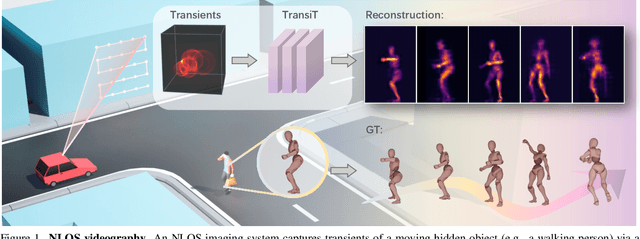
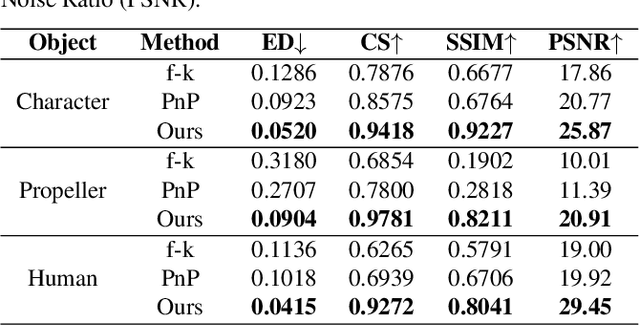
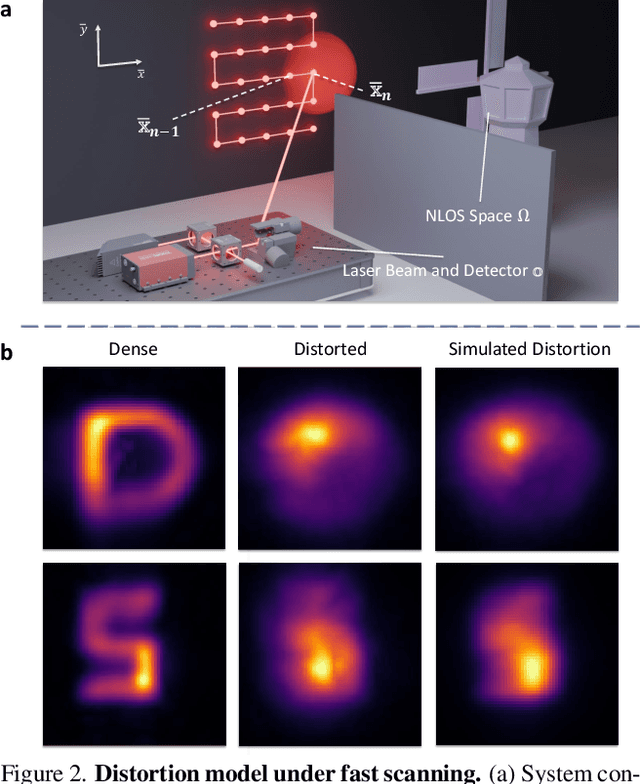
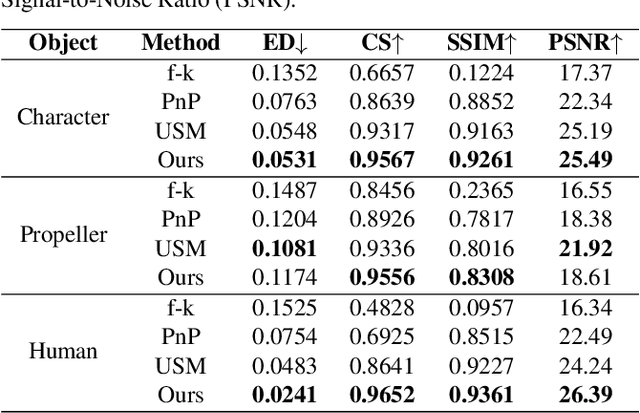
High quality and high speed videography using Non-Line-of-Sight (NLOS) imaging benefit autonomous navigation, collision prevention, and post-disaster search and rescue tasks. Current solutions have to balance between the frame rate and image quality. High frame rates, for example, can be achieved by reducing either per-point scanning time or scanning density, but at the cost of lowering the information density at individual frames. Fast scanning process further reduces the signal-to-noise ratio and different scanning systems exhibit different distortion characteristics. In this work, we design and employ a new Transient Transformer architecture called TransiT to achieve real-time NLOS recovery under fast scans. TransiT directly compresses the temporal dimension of input transients to extract features, reducing computation costs and meeting high frame rate requirements. It further adopts a feature fusion mechanism as well as employs a spatial-temporal Transformer to help capture features of NLOS transient videos. Moreover, TransiT applies transfer learning to bridge the gap between synthetic and real-measured data. In real experiments, TransiT manages to reconstruct from sparse transients of $16 \times 16$ measured at an exposure time of 0.4 ms per point to NLOS videos at a $64 \times 64$ resolution at 10 frames per second. We will make our code and dataset available to the community.
IMUSIC: IMU-based Facial Expression Capture
Feb 03, 2024



For facial motion capture and analysis, the dominated solutions are generally based on visual cues, which cannot protect privacy and are vulnerable to occlusions. Inertial measurement units (IMUs) serve as potential rescues yet are mainly adopted for full-body motion capture. In this paper, we propose IMUSIC to fill the gap, a novel path for facial expression capture using purely IMU signals, significantly distant from previous visual solutions.The key design in our IMUSIC is a trilogy. We first design micro-IMUs to suit facial capture, companion with an anatomy-driven IMU placement scheme. Then, we contribute a novel IMU-ARKit dataset, which provides rich paired IMU/visual signals for diverse facial expressions and performances. Such unique multi-modality brings huge potential for future directions like IMU-based facial behavior analysis. Moreover, utilizing IMU-ARKit, we introduce a strong baseline approach to accurately predict facial blendshape parameters from purely IMU signals. Specifically, we tailor a Transformer diffusion model with a two-stage training strategy for this novel tracking task. The IMUSIC framework empowers us to perform accurate facial capture in scenarios where visual methods falter and simultaneously safeguard user privacy. We conduct extensive experiments about both the IMU configuration and technical components to validate the effectiveness of our IMUSIC approach. Notably, IMUSIC enables various potential and novel applications, i.e., privacy-protecting facial capture, hybrid capture against occlusions, or detecting minute facial movements that are often invisible through visual cues. We will release our dataset and implementations to enrich more possibilities of facial capture and analysis in our community.