 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBubbleRAG: Evidence-Driven Retrieval-Augmented Generation for Black-Box Knowledge Graphs
Mar 19, 2026Large Language Models (LLMs) exhibit hallucinations in knowledge-intensive tasks. Graph-based retrieval augmented generation (RAG) has emerged as a promising solution, yet existing approaches suffer from fundamental recall and precision limitations when operating over black-box knowledge graphs -- graphs whose schema and structure are unknown in advance. We identify three core challenges that cause recall loss (semantic instantiation uncertainty and structural path uncertainty) and precision loss (evidential comparison uncertainty). To address these challenges, we formalize the retrieval task as the Optimal Informative Subgraph Retrieval (OISR) problem -- a variant of Group Steiner Tree -- and prove it to be NP-hard and APX-hard. We propose BubbleRAG, a training-free pipeline that systematically optimizes for both recall and precision through semantic anchor grouping, heuristic bubble expansion to discover candidate evidence graphs (CEGs), composite ranking, and reasoning-aware expansion. Experiments on multi-hop QA benchmarks demonstrate that BubbleRAG achieves state-of-the-art results, outperforming strong baselines in both F1 and accuracy while remaining plug-and-play.
AdaFV: Accelerating VLMs with Self-Adaptive Cross-Modality Attention Mixture
Jan 16, 2025



The success of VLMs often relies on the dynamic high-resolution schema that adaptively augments the input images to multiple crops, so that the details of the images can be retained. However, such approaches result in a large number of redundant visual tokens, thus significantly reducing the efficiency of the VLMs. To improve the VLMs' efficiency without introducing extra training costs, many research works are proposed to reduce the visual tokens by filtering the uninformative visual tokens or aggregating their information. Some approaches propose to reduce the visual tokens according to the self-attention of VLMs, which are biased, to result in inaccurate responses. The token reduction approaches solely rely on visual cues are text-agnostic, and fail to focus on the areas that are most relevant to the question, especially when the queried objects are non-salient to the image. In this work, we first conduct experiments to show that the original text embeddings are aligned with the visual tokens, without bias on the tailed visual tokens. We then propose a self-adaptive cross-modality attention mixture mechanism that dynamically leverages the effectiveness of visual saliency and text-to-image similarity in the pre-LLM layers to select the visual tokens that are informative. Extensive experiments demonstrate that the proposed approach achieves state-of-the-art training-free VLM acceleration performance, especially when the reduction rate is sufficiently large.
SLIM: Let LLM Learn More and Forget Less with Soft LoRA and Identity Mixture
Oct 10, 2024



Although many efforts have been made, it is still a challenge to balance the training budget, downstream performance, and the general capabilities of the LLMs in many applications. Training the whole model for downstream tasks is expensive, and could easily result in catastrophic forgetting. By introducing parameter-efficient fine-tuning (PEFT), the training cost could be reduced, but it still suffers from forgetting, and limits the learning on the downstream tasks. To efficiently fine-tune the LLMs with less limitation to their downstream performance while mitigating the forgetting of general capabilities, we propose a novel mixture of expert (MoE) framework based on Soft LoRA and Identity Mixture (SLIM), that allows dynamic routing between LoRA adapters and skipping connection, enables the suppression of forgetting. We adopt weight-yielding with sliding clustering for better out-of-domain distinguish to enhance the routing. We also propose to convert the mixture of low-rank adapters to the model merging formulation and introduce fast dynamic merging of LoRA adapters to keep the general capabilities of the base model. Extensive experiments demonstrate that the proposed SLIM is comparable to the state-of-the-art PEFT approaches on the downstream tasks while achieving the leading performance in mitigating catastrophic forgetting.
IMUSIC: IMU-based Facial Expression Capture
Feb 03, 2024



For facial motion capture and analysis, the dominated solutions are generally based on visual cues, which cannot protect privacy and are vulnerable to occlusions. Inertial measurement units (IMUs) serve as potential rescues yet are mainly adopted for full-body motion capture. In this paper, we propose IMUSIC to fill the gap, a novel path for facial expression capture using purely IMU signals, significantly distant from previous visual solutions.The key design in our IMUSIC is a trilogy. We first design micro-IMUs to suit facial capture, companion with an anatomy-driven IMU placement scheme. Then, we contribute a novel IMU-ARKit dataset, which provides rich paired IMU/visual signals for diverse facial expressions and performances. Such unique multi-modality brings huge potential for future directions like IMU-based facial behavior analysis. Moreover, utilizing IMU-ARKit, we introduce a strong baseline approach to accurately predict facial blendshape parameters from purely IMU signals. Specifically, we tailor a Transformer diffusion model with a two-stage training strategy for this novel tracking task. The IMUSIC framework empowers us to perform accurate facial capture in scenarios where visual methods falter and simultaneously safeguard user privacy. We conduct extensive experiments about both the IMU configuration and technical components to validate the effectiveness of our IMUSIC approach. Notably, IMUSIC enables various potential and novel applications, i.e., privacy-protecting facial capture, hybrid capture against occlusions, or detecting minute facial movements that are often invisible through visual cues. We will release our dataset and implementations to enrich more possibilities of facial capture and analysis in our community.
NARRATE: A Normal Assisted Free-View Portrait Stylizer
Jul 03, 2022
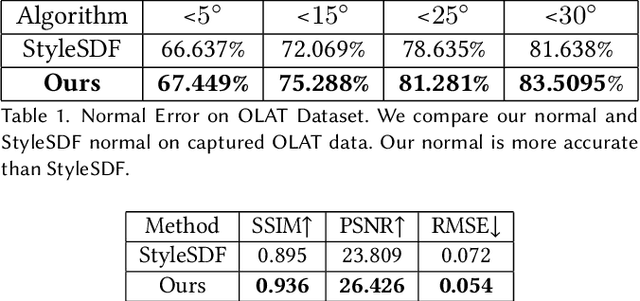
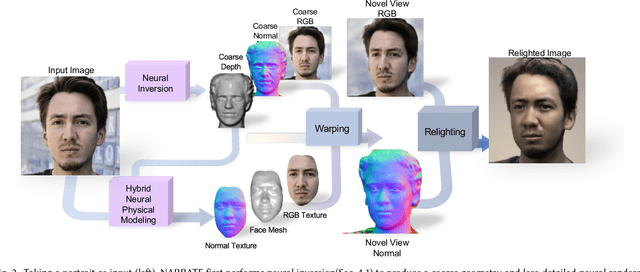
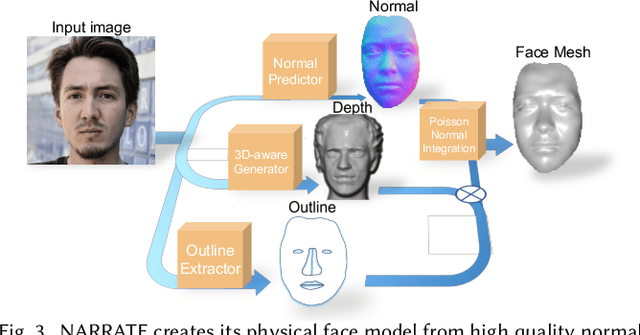
In this work, we propose NARRATE, a novel pipeline that enables simultaneously editing portrait lighting and perspective in a photorealistic manner. As a hybrid neural-physical face model, NARRATE leverages complementary benefits of geometry-aware generative approaches and normal-assisted physical face models. In a nutshell, NARRATE first inverts the input portrait to a coarse geometry and employs neural rendering to generate images resembling the input, as well as producing convincing pose changes. However, inversion step introduces mismatch, bringing low-quality images with less facial details. As such, we further estimate portrait normal to enhance the coarse geometry, creating a high-fidelity physical face model. In particular, we fuse the neural and physical renderings to compensate for the imperfect inversion, resulting in both realistic and view-consistent novel perspective images. In relighting stage, previous works focus on single view portrait relighting but ignoring consistency between different perspectives as well, leading unstable and inconsistent lighting effects for view changes. We extend Total Relighting to fix this problem by unifying its multi-view input normal maps with the physical face model. NARRATE conducts relighting with consistent normal maps, imposing cross-view constraints and exhibiting stable and coherent illumination effects. We experimentally demonstrate that NARRATE achieves more photorealistic, reliable results over prior works. We further bridge NARRATE with animation and style transfer tools, supporting pose change, light change, facial animation, and style transfer, either separately or in combination, all at a photographic quality. We showcase vivid free-view facial animations as well as 3D-aware relightable stylization, which help facilitate various AR/VR applications like virtual cinematography, 3D video conferencing, and post-production.
Low Complexity Component Nonlinear Distortions Mitigation Scheme for Probabilistically Shaped 64-QAM Signals
Dec 21, 2020

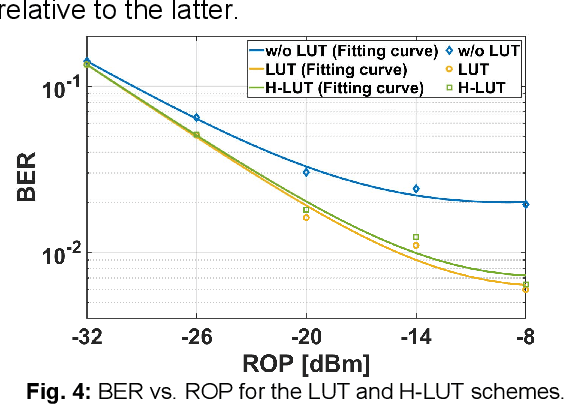
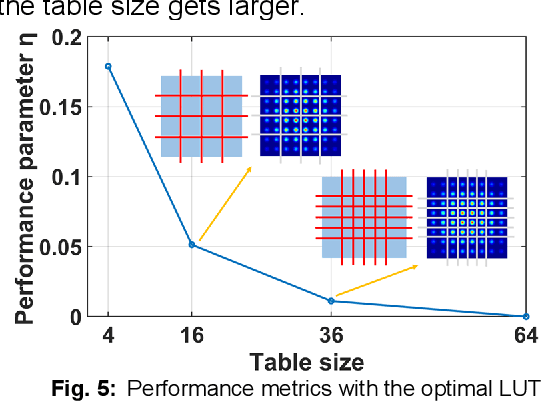
We propose a degenerated hierarchical look-up table (DH-LUT) scheme to compensate component nonlinearities. For probabilistically shaped 64-QAM signals, it achieves up to 2-dB SNR improvement, while the size of table is only 8.59% compared to the conventional LUT method.