 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAIN-VLA: Modeling Abstraction of Intention and eNvironment for Vision-Language-Action Models
Feb 02, 2026Despite significant progress in Visual-Language-Action (VLA), in highly complex and dynamic environments that involve real-time unpredictable interactions (such as 3D open worlds and large-scale PvP games), existing approaches remain inefficient at extracting action-critical signals from redundant sensor streams. To tackle this, we introduce MAIN-VLA, a framework that explicitly Models the Abstraction of Intention and eNvironment to ground decision-making in deep semantic alignment rather than superficial pattern matching. Specifically, our Intention Abstraction (IA) extracts verbose linguistic instructions and their associated reasoning into compact, explicit semantic primitives, while the Environment Semantics Abstraction (ESA) projects overwhelming visual streams into a structured, topological affordance representation. Furthermore, aligning these two abstract modalities induces an emergent attention-concentration effect, enabling a parameter-free token-pruning strategy that filters out perceptual redundancy without degrading performance. Extensive experiments in open-world Minecraft and large-scale PvP environments (Game for Peace and Valorant) demonstrate that MAIN-VLA sets a new state-of-the-art, which achieves superior decision quality, stronger generalization, and cutting-edge inference efficiency.
FURINA: Free from Unmergeable Router via LINear Aggregation of mixed experts
Sep 18, 2025


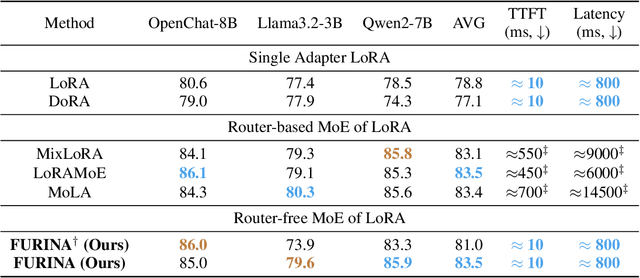
The Mixture of Experts (MoE) paradigm has been successfully integrated into Low-Rank Adaptation (LoRA) for parameter-efficient fine-tuning (PEFT), delivering performance gains with minimal parameter overhead. However, a key limitation of existing MoE-LoRA methods is their reliance on a discrete router, which prevents the integration of the MoE components into the backbone model. To overcome this, we propose FURINA, a novel Free from Unmergeable Router framework based on the LINear Aggregation of experts. FURINA eliminates the router by introducing a Self-Routing mechanism. This is achieved through three core innovations: (1) decoupled learning of the direction and magnitude for LoRA adapters, (2) a shared learnable magnitude vector for consistent activation scaling, and (3) expert selection loss that encourages divergent expert activation. The proposed mechanism leverages the angular similarity between the input and each adapter's directional component to activate experts, which are then scaled by the shared magnitude vector. This design allows the output norm to naturally reflect the importance of each expert, thereby enabling dynamic, router-free routing. The expert selection loss further sharpens this behavior by encouraging sparsity and aligning it with standard MoE activation patterns. We also introduce a shared expert within the MoE-LoRA block that provides stable, foundational knowledge. To the best of our knowledge, FURINA is the first router-free, MoE-enhanced LoRA method that can be fully merged into the backbone model, introducing zero additional inference-time cost or complexity. Extensive experiments demonstrate that FURINA not only significantly outperforms standard LoRA but also matches or surpasses the performance of existing MoE-LoRA methods, while eliminating the extra inference-time overhead of MoE.
CAD-Judge: Toward Efficient Morphological Grading and Verification for Text-to-CAD Generation
Aug 06, 2025Computer-Aided Design (CAD) models are widely used across industrial design, simulation, and manufacturing processes. Text-to-CAD systems aim to generate editable, general-purpose CAD models from textual descriptions, significantly reducing the complexity and entry barrier associated with traditional CAD workflows. However, rendering CAD models can be slow, and deploying VLMs to review CAD models can be expensive and may introduce reward hacking that degrades the systems. To address these challenges, we propose CAD-Judge, a novel, verifiable reward system for efficient and effective CAD preference grading and grammatical validation. We adopt the Compiler-as-a-Judge Module (CJM) as a fast, direct reward signal, optimizing model alignment by maximizing generative utility through prospect theory. To further improve the robustness of Text-to-CAD in the testing phase, we introduce a simple yet effective agentic CAD generation approach and adopt the Compiler-as-a-Review Module (CRM), which efficiently verifies the generated CAD models, enabling the system to refine them accordingly. Extensive experiments on challenging CAD datasets demonstrate that our method achieves state-of-the-art performance while maintaining superior efficiency.
AdaFV: Accelerating VLMs with Self-Adaptive Cross-Modality Attention Mixture
Jan 16, 2025



The success of VLMs often relies on the dynamic high-resolution schema that adaptively augments the input images to multiple crops, so that the details of the images can be retained. However, such approaches result in a large number of redundant visual tokens, thus significantly reducing the efficiency of the VLMs. To improve the VLMs' efficiency without introducing extra training costs, many research works are proposed to reduce the visual tokens by filtering the uninformative visual tokens or aggregating their information. Some approaches propose to reduce the visual tokens according to the self-attention of VLMs, which are biased, to result in inaccurate responses. The token reduction approaches solely rely on visual cues are text-agnostic, and fail to focus on the areas that are most relevant to the question, especially when the queried objects are non-salient to the image. In this work, we first conduct experiments to show that the original text embeddings are aligned with the visual tokens, without bias on the tailed visual tokens. We then propose a self-adaptive cross-modality attention mixture mechanism that dynamically leverages the effectiveness of visual saliency and text-to-image similarity in the pre-LLM layers to select the visual tokens that are informative. Extensive experiments demonstrate that the proposed approach achieves state-of-the-art training-free VLM acceleration performance, especially when the reduction rate is sufficiently large.
Sharper Error Bounds in Late Fusion Multi-view Clustering Using Eigenvalue Proportion
Dec 24, 2024

Multi-view clustering (MVC) aims to integrate complementary information from multiple views to enhance clustering performance. Late Fusion Multi-View Clustering (LFMVC) has shown promise by synthesizing diverse clustering results into a unified consensus. However, current LFMVC methods struggle with noisy and redundant partitions and often fail to capture high-order correlations across views. To address these limitations, we present a novel theoretical framework for analyzing the generalization error bounds of multiple kernel $k$-means, leveraging local Rademacher complexity and principal eigenvalue proportions. Our analysis establishes a convergence rate of $\mathcal{O}(1/n)$, significantly improving upon the existing rate in the order of $\mathcal{O}(\sqrt{k/n})$. Building on this insight, we propose a low-pass graph filtering strategy within a multiple linear $k$-means framework to mitigate noise and redundancy, further refining the principal eigenvalue proportion and enhancing clustering accuracy. Experimental results on benchmark datasets confirm that our approach outperforms state-of-the-art methods in clustering performance and robustness. The related codes is available at https://github.com/csliangdu/GMLKM .
k-HyperEdge Medoids for Clustering Ensemble
Dec 11, 2024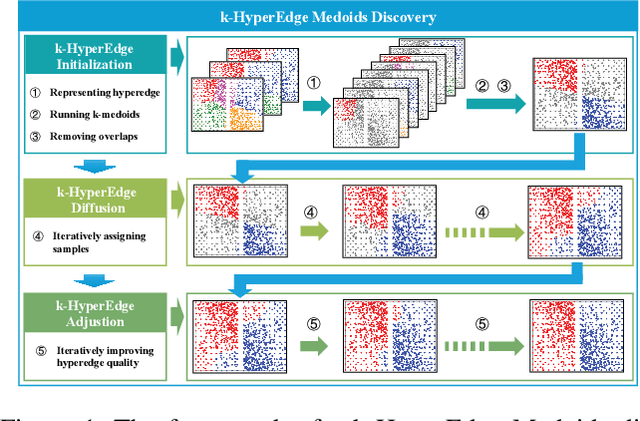
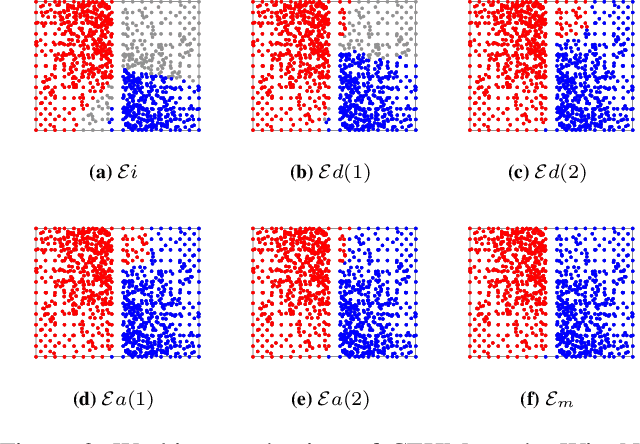
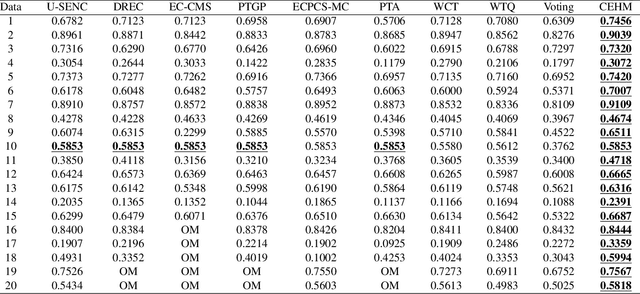
Clustering ensemble has been a popular research topic in data science due to its ability to improve the robustness of the single clustering method. Many clustering ensemble methods have been proposed, most of which can be categorized into clustering-view and sample-view methods. The clustering-view method is generally efficient, but it could be affected by the unreliability that existed in base clustering results. The sample-view method shows good performance, while the construction of the pairwise sample relation is time-consuming. In this paper, the clustering ensemble is formulated as a k-HyperEdge Medoids discovery problem and a clustering ensemble method based on k-HyperEdge Medoids that considers the characteristics of the above two types of clustering ensemble methods is proposed. In the method, a set of hyperedges is selected from the clustering view efficiently, then the hyperedges are diffused and adjusted from the sample view guided by a hyperedge loss function to construct an effective k-HyperEdge Medoid set. The loss function is mainly reduced by assigning samples to the hyperedge with the highest degree of belonging. Theoretical analyses show that the solution can approximate the optimal, the assignment method can gradually reduce the loss function, and the estimation of the belonging degree is statistically reasonable. Experiments on artificial data show the working mechanism of the proposed method. The convergence of the method is verified by experimental analysis of twenty data sets. The effectiveness and efficiency of the proposed method are also verified on these data, with nine representative clustering ensemble algorithms as reference.
Clustering ensemble algorithm with high-order consistency learning
Oct 31, 2024Most of the research on clustering ensemble focuses on designing practical consistency learning algorithms.To solve the problems that the quality of base clusters varies and the low-quality base clusters have an impact on the performance of the clustering ensemble, from the perspective of data mining, the intrinsic connections of data were mined based on the base clusters, and a high-order information fusion algorithm was proposed to represent the connections between data from different dimensions, namely Clustering Ensemble with High-order Consensus learning (HCLCE). Firstly, each high-order information was fused into a new structured consistency matrix. Then, the obtained multiple consistency matrices were fused together. Finally, multiple information was fused into a consistent result. Experimental results show that LCLCE algorithm has the clustering accuracy improved by an average of 7.22%, and the Normalized Mutual Information (NMI) improved by an average of 9.19% compared with the suboptimal Locally Weighted Evidence Accumulation (LWEA) algorithm. It can be seen that the proposed algorithm can obtain better clustering results compared with clustering ensemble algorithms and using one information alone.
* in Chinese language
Multiple kernel concept factorization algorithm based on global fusion
Oct 27, 2024Non-negative Matrix Factorization(NMF) algorithm can only be used to find low rank approximation of original non-negative data while Concept Factorization(CF) algorithm extends matrix factorization to single non-linear kernel space, improving learning ability and adaptability of matrix factorization. In unsupervised environment, to design or select proper kernel function for specific dataset, a new algorithm called Globalized Multiple Kernel CF(GMKCF)was proposed. Multiple candidate kernel functions were input in the same time and learned in the CF framework based on global linear fusion, obtaining a clustering result with high quality and stability and solving the problem of kernel function selection that the CF faced. The convergence of the proposed algorithm was verified by solving the model with alternate iteration. The experimental results on several real databases show that the proposed algorithm outperforms comparison algorithms in data clustering, such as Kernel K-Means(KKM), Spectral Clustering(SC), Kernel CF(KCF), Co-regularized multi-view spectral clustering(Coreg), and Robust Multiple KKM(RMKKM).
* in Chinese language
Hierarchical Multiple Kernel K-Means Algorithm Based on Sparse Connectivity
Oct 27, 2024Multiple kernel learning (MKL) aims to find an optimal, consistent kernel function. In the hierarchical multiple kernel clustering (HMKC) algorithm, sample features are extracted layer by layer from a high-dimensional space to maximize the retention of effective information. However, information interaction between layers is often ignored. In this model, only corresponding nodes in adjacent layers exchange information; other nodes remain isolated, and if full connectivity is adopted, the diversity of the final consistency matrix is reduced. Therefore, this paper proposes a hierarchical multiple kernel K-Means (SCHMKKM) algorithm based on sparse connectivity, which controls the assignment matrix to achieve sparse connections through a sparsity rate, thereby locally fusing the features obtained by distilling information between layers. Finally, we conduct cluster analysis on multiple datasets and compare it with the fully connected hierarchical multiple kernel K-Means (FCHMKKM) algorithm in experiments. It is shown that more discriminative information fusion is beneficial for learning a better consistent partition matrix, and the fusion strategy based on sparse connection outperforms the full connection strategy.
* in Chinese language
Multiple Kernel Clustering via Local Regression Integration
Oct 20, 2024Multiple kernel methods less consider the intrinsic manifold structure of multiple kernel data and estimate the consensus kernel matrix with quadratic number of variables, which makes it vulnerable to the noise and outliers within multiple candidate kernels. This paper first presents the clustering method via kernelized local regression (CKLR). It captures the local structure of kernel data and employs kernel regression on the local region to predict the clustering results. Moreover, this paper further extends it to perform clustering via the multiple kernel local regression (CMKLR). We construct the kernel level local regression sparse coefficient matrix for each candidate kernel, which well characterizes the kernel level manifold structure. We then aggregate all the kernel level local regression coefficients via linear weights and generate the consensus sparse local regression coefficient, which largely reduces the number of candidate variables and becomes more robust against noises and outliers within multiple kernel data. Thus, the proposed method CMKLR avoids the above two limitations. It only contains one additional hyperparameter for tuning. Extensive experimental results show that the clustering performance of the proposed method on benchmark datasets is better than that of 10 state-of-the-art multiple kernel clustering methods.
* in Chinese language