 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple Kernel Clustering via Local Regression Integration
Oct 20, 2024Multiple kernel methods less consider the intrinsic manifold structure of multiple kernel data and estimate the consensus kernel matrix with quadratic number of variables, which makes it vulnerable to the noise and outliers within multiple candidate kernels. This paper first presents the clustering method via kernelized local regression (CKLR). It captures the local structure of kernel data and employs kernel regression on the local region to predict the clustering results. Moreover, this paper further extends it to perform clustering via the multiple kernel local regression (CMKLR). We construct the kernel level local regression sparse coefficient matrix for each candidate kernel, which well characterizes the kernel level manifold structure. We then aggregate all the kernel level local regression coefficients via linear weights and generate the consensus sparse local regression coefficient, which largely reduces the number of candidate variables and becomes more robust against noises and outliers within multiple kernel data. Thus, the proposed method CMKLR avoids the above two limitations. It only contains one additional hyperparameter for tuning. Extensive experimental results show that the clustering performance of the proposed method on benchmark datasets is better than that of 10 state-of-the-art multiple kernel clustering methods.
* in Chinese language
KGR^4: Retrieval, Retrospect, Refine and Rethink for Commonsense Generation
Dec 15, 2021
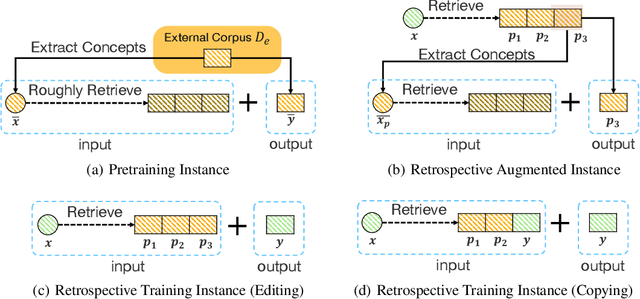


Generative commonsense reasoning requires machines to generate sentences describing an everyday scenario given several concepts, which has attracted much attention recently. However, existing models cannot perform as well as humans, since sentences they produce are often implausible and grammatically incorrect. In this paper, inspired by the process of humans creating sentences, we propose a novel Knowledge-enhanced Commonsense Generation framework, termed KGR^4, consisting of four stages: Retrieval, Retrospect, Refine, Rethink. Under this framework, we first perform retrieval to search for relevant sentences from external corpus as the prototypes. Then, we train the generator that either edits or copies these prototypes to generate candidate sentences, of which potential errors will be fixed by an autoencoder-based refiner. Finally, we select the output sentence from candidate sentences produced by generators with different hyper-parameters. Experimental results and in-depth analysis on the CommonGen benchmark strongly demonstrate the effectiveness of our framework. Particularly, KGR^4 obtains 33.56 SPICE points in the official leaderboard, outperforming the previously-reported best result by 2.49 SPICE points and achieving state-of-the-art performance.
Bridging Subword Gaps in Pretrain-Finetune Paradigm for Natural Language Generation
Jun 11, 2021
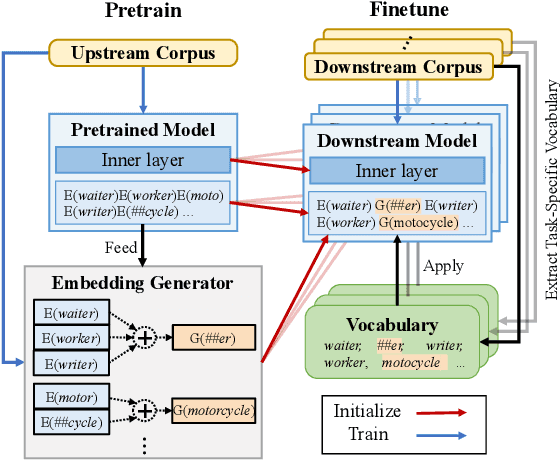
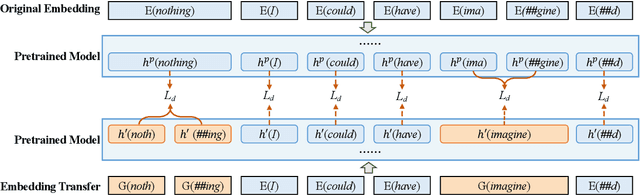
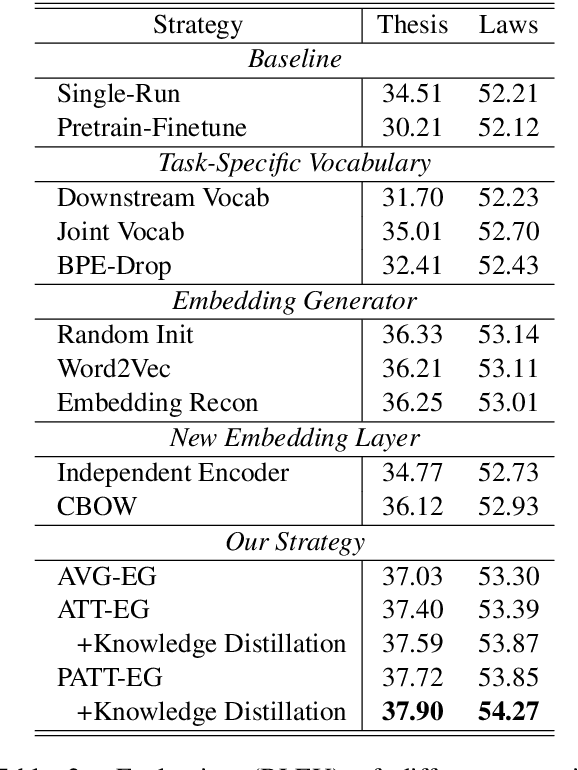
A well-known limitation in pretrain-finetune paradigm lies in its inflexibility caused by the one-size-fits-all vocabulary. This potentially weakens the effect when applying pretrained models into natural language generation (NLG) tasks, especially for the subword distributions between upstream and downstream tasks with significant discrepancy. Towards approaching this problem, we extend the vanilla pretrain-finetune pipeline with an extra embedding transfer step. Specifically, a plug-and-play embedding generator is introduced to produce the representation of any input token, according to pre-trained embeddings of its morphologically similar ones. Thus, embeddings of mismatch tokens in downstream tasks can also be efficiently initialized. We conduct experiments on a variety of NLG tasks under the pretrain-finetune fashion. Experimental results and extensive analyses show that the proposed strategy offers us opportunities to feel free to transfer the vocabulary, leading to more efficient and better performed downstream NLG models.
Manifold Adaptive Multiple Kernel K-Means for Clustering
Sep 30, 2020
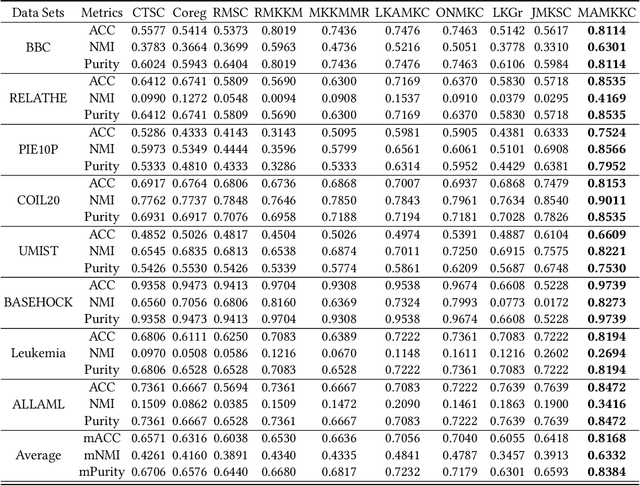
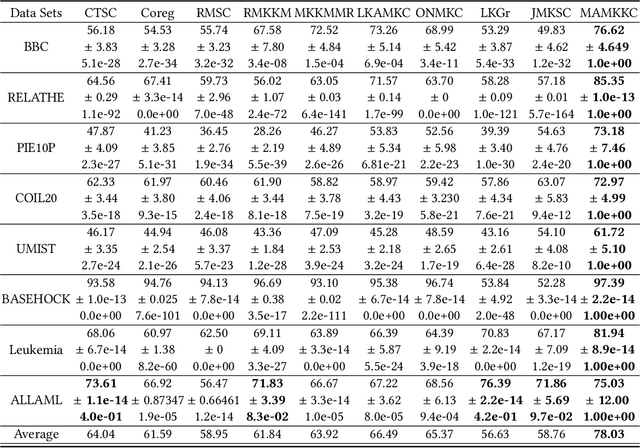
Multiple kernel methods based on k-means aims to integrate a group of kernels to improve the performance of kernel k-means clustering. However, we observe that most existing multiple kernel k-means methods exploit the nonlinear relationship within kernels, whereas the local manifold structure among multiple kernel space is not sufficiently considered. In this paper, we adopt the manifold adaptive kernel, instead of the original kernel, to integrate the local manifold structure of kernels. Thus, the induced multiple manifold adaptive kernels not only reflect the nonlinear relationship but also the local manifold structure. We then perform multiple kernel clustering within the multiple kernel k-means clustering framework. It has been verified that the proposed method outperforms several state-of-the-art baseline methods on a variety of data sets.