 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised feature selection algorithm framework based on neighborhood interval disturbance fusion
Oct 20, 2024Feature selection technology is a key technology of data dimensionality reduction. Becauseof the lack of label information of collected data samples, unsupervised feature selection has attracted more attention. The universality and stability of many unsupervised feature selection algorithms are very low and greatly affected by the dataset structure. For this reason, many researchers have been keen to improve the stability of the algorithm. This paper attempts to preprocess the data set and use an interval method to approximate the data set, experimentally verifying the advantages and disadvantages of the new interval data set. This paper deals with these data sets from the global perspective and proposes a new algorithm-unsupervised feature selection algorithm based on neighborhood interval disturbance fusion(NIDF). This method can realize the joint learning of the final score of the feature and the approximate data interval. By comparing with the original unsupervised feature selection methods and several existing feature selection frameworks, the superiority of the proposed model is verified.
* in Chinese language
Manifold Adaptive Multiple Kernel K-Means for Clustering
Sep 30, 2020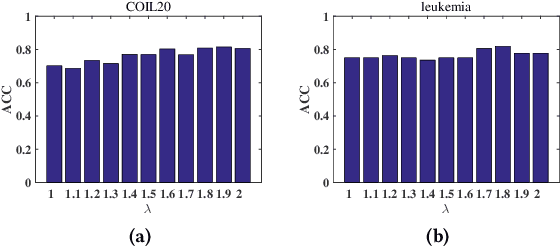
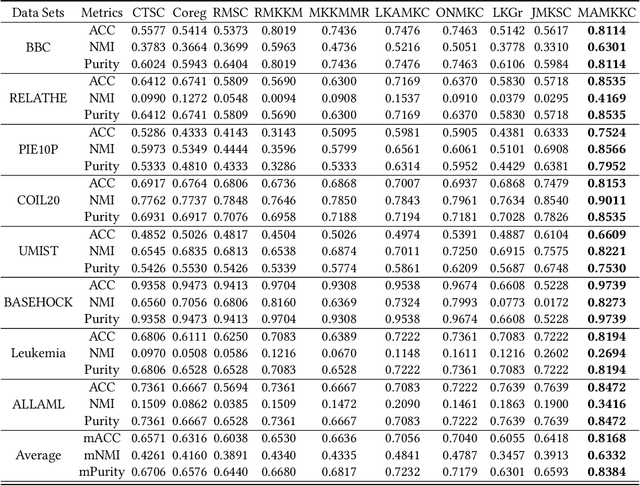
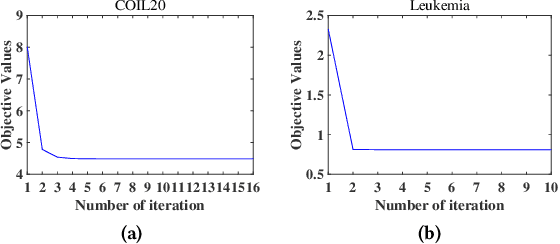
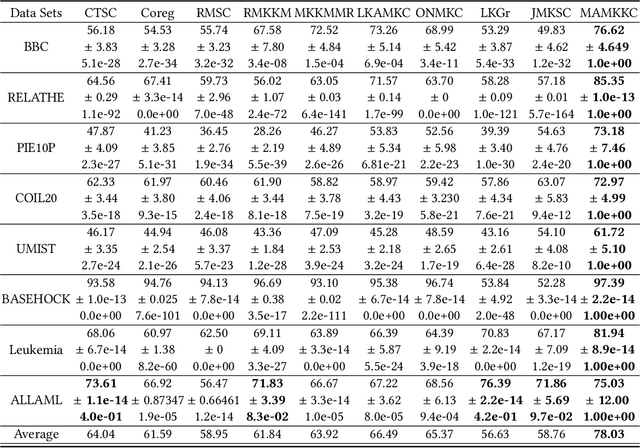
Multiple kernel methods based on k-means aims to integrate a group of kernels to improve the performance of kernel k-means clustering. However, we observe that most existing multiple kernel k-means methods exploit the nonlinear relationship within kernels, whereas the local manifold structure among multiple kernel space is not sufficiently considered. In this paper, we adopt the manifold adaptive kernel, instead of the original kernel, to integrate the local manifold structure of kernels. Thus, the induced multiple manifold adaptive kernels not only reflect the nonlinear relationship but also the local manifold structure. We then perform multiple kernel clustering within the multiple kernel k-means clustering framework. It has been verified that the proposed method outperforms several state-of-the-art baseline methods on a variety of data sets.