 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHead-Pose-Aware Visual Speech Recognition with FiLM Modulation
May 30, 2026Visual Speech Recognition (VSR) aims to recognize speech from visual cues such as lip movements, but its performance is fundamentally limited by viseme ambiguity and pose-induced variations that introduce geometric distortions and occlusions. Existing approaches mainly rely on linguistic context or implicit invariance, leaving visual representations insufficiently robust under non-frontal views. In this work, we propose a pose-aware phoneme-level framework, termed HP-VSR-ResFiLM, that explicitly incorporates head-pose information into visual feature extraction. The proposed framework adopts a two-stage pipeline consisting of a pose-conditioned visual encoder in Stage 1 and a pretrained NLLB language model in Stage 2 for phoneme-to-text reconstruction. Specifically, Stage 1 incorporates a pose-conditioned residual Feature-wise Linear Modulation (FiLM) block after the 2D CNN frontend to adaptively refine visual representations using head-pose information. Experiments on LRS2 and LRS3 demonstrate that HP-VSR-ResFiLM achieves competitive performance under comparable training conditions, attaining word error rates (WER) of 25.0% and 33.2%, respectively, without relying on additional training data. Ablation studies further show that a single residual FiLM block consistently improves overall WER, while deeper modulation at Layers 3 and 4 provides larger gains for samples with yaw angles greater than 30° without degrading performance for smaller pose variations. These findings demonstrate that explicit pose-aware feature modulation offers an effective and computationally efficient solution for improving VSR robustness in unconstrained settings.
How Reliable Are Semantic-ID Tokenizer Comparisons in Generative Recommendation?
May 25, 2026In Semantic-ID (SID) based generative recommendation, each item is represented as a sequence of discrete codes, and an autoregressive model is trained to generate the SID sequence of the next item; top-K performance is then measured by checking whether the SID sequence of the target item appears among the generated sequences. This evaluation protocol equates SID-level matching with item-level recommendation, an equivalence that holds only when every SID sequence maps to a single item. We show this assumption breaks down in practice: because tokenizers compress item features into a code space, semantically similar but collaboratively distinct items are frequently assigned the same SID sequence. Across four datasets and five representative tokenizers, the fraction of items involved in such collisions reaches 30.5%, so matching a shared SID sequence identifies only a collision group rather than the target item. Consequently, SID-level metrics overestimate item-level performance (Hit@10 is inflated by up to 103.36%), and the inflation grows with the collision rate. To support faithful comparison, we develop collision-aware item-level metrics computed directly from generated SID sequences, together with a post-tokenizer procedure that reassigns last-level SIDs at minimum cost to obtain a collision-free assignment for any existing tokenizer. Our results indicate that SID-level rankings in prior work should be interpreted with caution, and that reliable tokenizer evaluation requires either item-level correction or collision-free SID assignments.
CAST: Modeling Semantic-Level Transitions for Complementary-Aware Sequential Recommendation
Apr 21, 2026Sequential Recommendation (SR) aims to predict the next interaction of a user based on their behavior sequence, where complementary relations often provide essential signals for predicting the next item. However, mainstream models relying on sparse co-purchase statistics often mistake spurious correlations (e.g., due to popularity bias) for true complementary relations. Identifying true complementary relations requires capturing the fine-grained item semantics (e.g., specifications) that simple cooccurrence statistics would be unable to model. While recent semantics-based methods utilize discrete semantic codes to represent items, they typically aggregate semantic codes into coarse item representations. This aggregation process blurs specific semantic details required to identify complementarity. To address these critical limitations and effectively leverage semantics for capturing reliable complementary relations, we propose a Complementary-Aware Semantic Transition (CAST) framework that introduces a new modeling paradigm built upon semantic-level transitions. Specifically, a semantic-level transition module is designed to model dynamic transitions directly in the discrete semantic code space, effectively capturing fine-grained semantic dependencies often lost in aggregated item representations. Then, a complementary prior injection module is designed to incorporate LLM-verified complementary priors into the attention mechanism, thereby prioritizing complementary patterns over co-occurrence statistics. Experiments on multiple e-commerce datasets demonstrate that CAST consistently outperforms the state-of-the-art approaches, achieving up to 17.6% Recall and 16.0% NDCG gains with 65x training acceleration. This validates its effectiveness and efficiency in uncovering latent item complementarity beyond statistics. The code will be released upon acceptance.
Orchestrating Tokens and Sequences: Dynamic Hybrid Policy Optimization for RLVR
Jan 09, 2026Reinforcement Learning with Verifiable Rewards (RLVR) offers a promising framework for optimizing large language models in reasoning tasks. However, existing RLVR algorithms focus on different granularities, and each has complementary strengths and limitations. Group Relative Policy Optimization (GRPO) updates the policy with token-level importance ratios, which preserves fine-grained credit assignment but often suffers from high variance and instability. In contrast, Group Sequence Policy Optimization (GSPO) applies single sequence-level importance ratios across all tokens in a response that better matches sequence-level rewards, but sacrifices token-wise credit assignment. In this paper, we propose Dynamic Hybrid Policy Optimization (DHPO) to bridge GRPO and GSPO within a single clipped surrogate objective. DHPO combines token-level and sequence-level importance ratios using weighting mechanisms. We explore two variants of the mixing mechanism, including an averaged mixing and an entropy-guided mixing. To further stabilize training, we employ a branch-specific clipping strategy that constrains token-level and sequence-level ratios within separate trust regions before mixing, preventing outliers in either branch from dominating the update. Across seven challenging mathematical reasoning benchmarks, experiments on both dense and MoE models from the Qwen3 series show that DHPO consistently outperforms GRPO and GSPO. We will release our code upon acceptance of this paper.
Each Prompt Matters: Scaling Reinforcement Learning Without Wasting Rollouts on Hundred-Billion-Scale MoE
Dec 08, 2025We present CompassMax-V3-Thinking, a hundred-billion-scale MoE reasoning model trained with a new RL framework built on one principle: each prompt must matter. Scaling RL to this size exposes critical inefficiencies-zero-variance prompts that waste rollouts, unstable importance sampling over long horizons, advantage inversion from standard reward models, and systemic bottlenecks in rollout processing. To overcome these challenges, we introduce several unified innovations: (1) Multi-Stage Zero-Variance Elimination, which filters out non-informative prompts and stabilizes group-based policy optimization (e.g. GRPO) by removing wasted rollouts; (2) ESPO, an entropy-adaptive optimization method that balances token-level and sequence-level importance sampling to maintain stable learning dynamics; (3) a Router Replay strategy that aligns training-time MoE router decisions with inference-time behavior to mitigate train-infer discrepancies, coupled with a reward model adjustment to prevent advantage inversion; (4) a high-throughput RL system with FP8-precision rollouts, overlapped reward computation, and length-aware scheduling to eliminate performance bottlenecks. Together, these contributions form a cohesive pipeline that makes RL on hundred-billion-scale MoE models stable and efficient. The resulting model delivers strong performance across both internal and public evaluations.
Towards Reliable Evaluation of Large Language Models for Multilingual and Multimodal E-Commerce Applications
Oct 23, 2025Large Language Models (LLMs) excel on general-purpose NLP benchmarks, yet their capabilities in specialized domains remain underexplored. In e-commerce, existing evaluations-such as EcomInstruct, ChineseEcomQA, eCeLLM, and Shopping MMLU-suffer from limited task diversity (e.g., lacking product guidance and after-sales issues), limited task modalities (e.g., absence of multimodal data), synthetic or curated data, and a narrow focus on English and Chinese, leaving practitioners without reliable tools to assess models on complex, real-world shopping scenarios. We introduce EcomEval, a comprehensive multilingual and multimodal benchmark for evaluating LLMs in e-commerce. EcomEval covers six categories and 37 tasks (including 8 multimodal tasks), sourced primarily from authentic customer queries and transaction logs, reflecting the noisy and heterogeneous nature of real business interactions. To ensure both quality and scalability of reference answers, we adopt a semi-automatic pipeline in which large models draft candidate responses subsequently reviewed and modified by over 50 expert annotators with strong e-commerce and multilingual expertise. We define difficulty levels for each question and task category by averaging evaluation scores across models with different sizes and capabilities, enabling challenge-oriented and fine-grained assessment. EcomEval also spans seven languages-including five low-resource Southeast Asian languages-offering a multilingual perspective absent from prior work.
LLM-OREF: An Open Relation Extraction Framework Based on Large Language Models
Sep 18, 2025The goal of open relation extraction (OpenRE) is to develop an RE model that can generalize to new relations not encountered during training. Existing studies primarily formulate OpenRE as a clustering task. They first cluster all test instances based on the similarity between the instances, and then manually assign a new relation to each cluster. However, their reliance on human annotation limits their practicality. In this paper, we propose an OpenRE framework based on large language models (LLMs), which directly predicts new relations for test instances by leveraging their strong language understanding and generation abilities, without human intervention. Specifically, our framework consists of two core components: (1) a relation discoverer (RD), designed to predict new relations for test instances based on \textit{demonstrations} formed by training instances with known relations; and (2) a relation predictor (RP), used to select the most likely relation for a test instance from $n$ candidate relations, guided by \textit{demonstrations} composed of their instances. To enhance the ability of our framework to predict new relations, we design a self-correcting inference strategy composed of three stages: relation discovery, relation denoising, and relation prediction. In the first stage, we use RD to preliminarily predict new relations for all test instances. Next, we apply RP to select some high-reliability test instances for each new relation from the prediction results of RD through a cross-validation method. During the third stage, we employ RP to re-predict the relations of all test instances based on the demonstrations constructed from these reliable test instances. Extensive experiments on three OpenRE datasets demonstrate the effectiveness of our framework. We release our code at https://github.com/XMUDeepLIT/LLM-OREF.git.
Compass-Thinker-7B Technical Report
Aug 12, 2025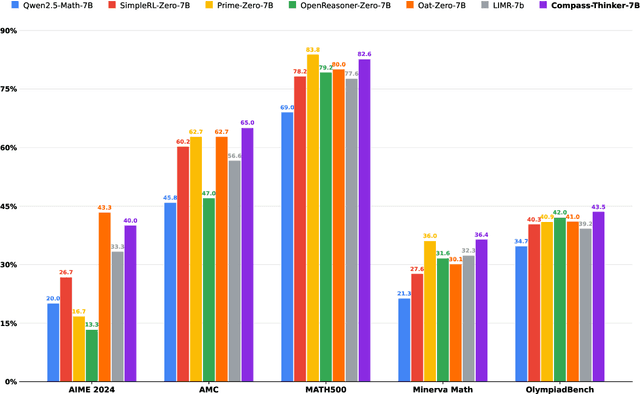

Recent R1-Zero-like research further demonstrates that reasoning extension has given large language models (LLMs) unprecedented reasoning capabilities, and Reinforcement Learning is the core technology to elicit its complex reasoning. However, conducting RL experiments directly on hyperscale models involves high computational costs and resource demands, posing significant risks. We propose the Compass-Thinker-7B model, which aims to explore the potential of Reinforcement Learning with less computational resources and costs, and provides insights for further research into RL recipes for larger models. Compass-Thinker-7B is trained from an open source model through a specially designed Reinforcement Learning Pipeline. we curate a dataset of 30k verifiable mathematics problems for the Reinforcement Learning Pipeline. By configuring data and training settings with different difficulty distributions for different stages, the potential of the model is gradually released and the training efficiency is improved. Extensive evaluations show that Compass-Thinker-7B possesses exceptional reasoning potential, and achieves superior performance on mathematics compared to the same-sized RL model.Especially in the challenging AIME2024 evaluation, Compass-Thinker-7B achieves 40% accuracy.
Optimal Transport-Based Token Weighting scheme for Enhanced Preference Optimization
May 24, 2025Direct Preference Optimization (DPO) has emerged as a promising framework for aligning Large Language Models (LLMs) with human preferences by directly optimizing the log-likelihood difference between chosen and rejected responses. However, existing methods assign equal importance to all tokens in the response, while humans focus on more meaningful parts. This leads to suboptimal preference optimization, as irrelevant or noisy tokens disproportionately influence DPO loss. To address this limitation, we propose \textbf{O}ptimal \textbf{T}ransport-based token weighting scheme for enhancing direct \textbf{P}reference \textbf{O}ptimization (OTPO). By emphasizing semantically meaningful token pairs and de-emphasizing less relevant ones, our method introduces a context-aware token weighting scheme that yields a more contrastive reward difference estimate. This adaptive weighting enhances reward stability, improves interpretability, and ensures that preference optimization focuses on meaningful differences between responses. Extensive experiments have validated OTPO's effectiveness in improving instruction-following ability across various settings\footnote{Code is available at https://github.com/Mimasss2/OTPO.}.
Leveraging Generalizability of Image-to-Image Translation for Enhanced Adversarial Defense
Apr 02, 2025



In the rapidly evolving field of artificial intelligence, machine learning emerges as a key technology characterized by its vast potential and inherent risks. The stability and reliability of these models are important, as they are frequent targets of security threats. Adversarial attacks, first rigorously defined by Ian Goodfellow et al. in 2013, highlight a critical vulnerability: they can trick machine learning models into making incorrect predictions by applying nearly invisible perturbations to images. Although many studies have focused on constructing sophisticated defensive mechanisms to mitigate such attacks, they often overlook the substantial time and computational costs of training and maintaining these models. Ideally, a defense method should be able to generalize across various, even unseen, adversarial attacks with minimal overhead. Building on our previous work on image-to-image translation-based defenses, this study introduces an improved model that incorporates residual blocks to enhance generalizability. The proposed method requires training only a single model, effectively defends against diverse attack types, and is well-transferable between different target models. Experiments show that our model can restore the classification accuracy from near zero to an average of 72\% while maintaining competitive performance compared to state-of-the-art methods.