 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeESS-ReduNet: Enhancing Subspace Separability of ReduNet via Dynamic Expansion with Bayesian Inference
Nov 27, 2024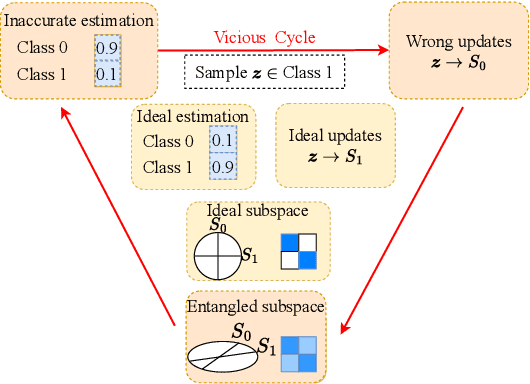
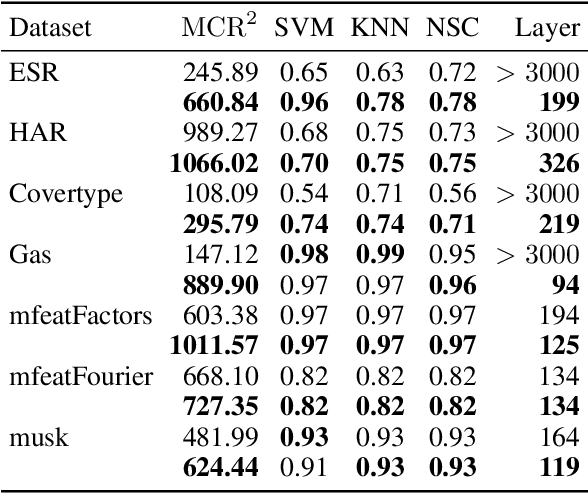
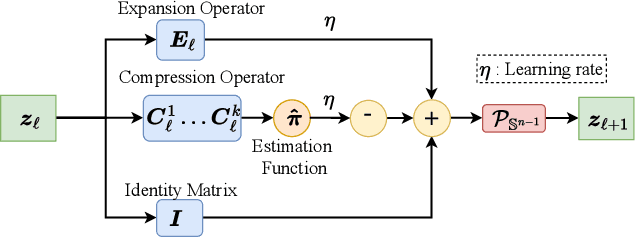

ReduNet is a deep neural network model that leverages the principle of maximal coding rate \textbf{redu}ction to transform original data samples into a low-dimensional, linear discriminative feature representation. Unlike traditional deep learning frameworks, ReduNet constructs its parameters explicitly layer by layer, with each layer's parameters derived based on the features transformed from the preceding layer. Rather than directly using labels, ReduNet uses the similarity between each category's spanned subspace and the data samples for feature updates at each layer. This may lead to features being updated in the wrong direction, impairing the correct construction of network parameters and reducing the network's convergence speed. To address this issue, based on the geometric interpretation of the network parameters, this paper presents ESS-ReduNet to enhance the separability of each category's subspace by dynamically controlling the expansion of the overall spanned space of the samples. Meanwhile, label knowledge is incorporated with Bayesian inference to encourage the decoupling of subspaces. Finally, stability, as assessed by the condition number, serves as an auxiliary criterion for halting training. Experiments on the ESR, HAR, Covertype, and Gas datasets demonstrate that ESS-ReduNet achieves more than 10x improvement in convergence compared to ReduNet. Notably, on the ESR dataset, the features transformed by ESS-ReduNet achieve a 47\% improvement in SVM classification accuracy.