 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDESCN: Deep Entire Space Cross Networks for Individual Treatment Effect Estimation
Jul 19, 2022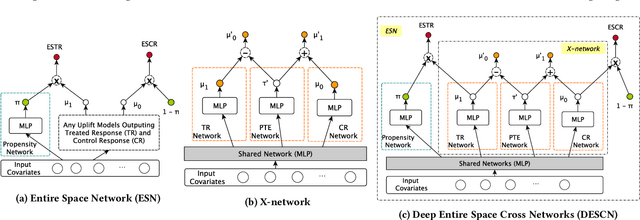

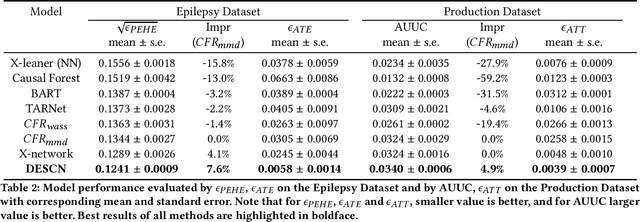

Causal Inference has wide applications in various areas such as E-commerce and precision medicine, and its performance heavily relies on the accurate estimation of the Individual Treatment Effect (ITE). Conventionally, ITE is predicted by modeling the treated and control response functions separately in their individual sample spaces. However, such an approach usually encounters two issues in practice, i.e. divergent distribution between treated and control groups due to treatment bias, and significant sample imbalance of their population sizes. This paper proposes Deep Entire Space Cross Networks (DESCN) to model treatment effects from an end-to-end perspective. DESCN captures the integrated information of the treatment propensity, the response, and the hidden treatment effect through a cross network in a multi-task learning manner. Our method jointly learns the treatment and response functions in the entire sample space to avoid treatment bias and employs an intermediate pseudo treatment effect prediction network to relieve sample imbalance. Extensive experiments are conducted on a synthetic dataset and a large-scaled production dataset from the E-commerce voucher distribution business. The results indicate that DESCN can successfully enhance the accuracy of ITE estimation and improve the uplift ranking performance. A sample of the production dataset and the source code are released to facilitate future research in the community, which is, to the best of our knowledge, the first large-scale public biased treatment dataset for causal inference.
* KDD 2022
KGR^4: Retrieval, Retrospect, Refine and Rethink for Commonsense Generation
Dec 15, 2021
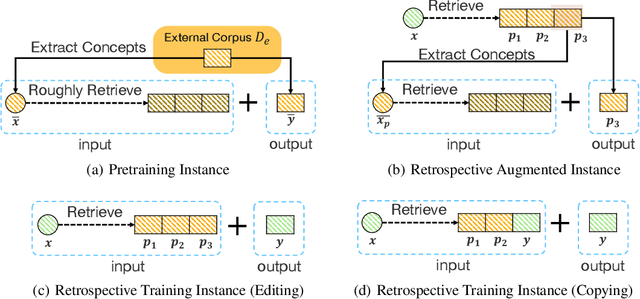


Generative commonsense reasoning requires machines to generate sentences describing an everyday scenario given several concepts, which has attracted much attention recently. However, existing models cannot perform as well as humans, since sentences they produce are often implausible and grammatically incorrect. In this paper, inspired by the process of humans creating sentences, we propose a novel Knowledge-enhanced Commonsense Generation framework, termed KGR^4, consisting of four stages: Retrieval, Retrospect, Refine, Rethink. Under this framework, we first perform retrieval to search for relevant sentences from external corpus as the prototypes. Then, we train the generator that either edits or copies these prototypes to generate candidate sentences, of which potential errors will be fixed by an autoencoder-based refiner. Finally, we select the output sentence from candidate sentences produced by generators with different hyper-parameters. Experimental results and in-depth analysis on the CommonGen benchmark strongly demonstrate the effectiveness of our framework. Particularly, KGR^4 obtains 33.56 SPICE points in the official leaderboard, outperforming the previously-reported best result by 2.49 SPICE points and achieving state-of-the-art performance.