 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRCCF: A Persona-guided Retrieval and Causal-aware Cognitive Filtering Framework for Emotional Support Conversation
Apr 02, 2026Emotional Support Conversation (ESC) aims to alleviate individual emotional distress by generating empathetic responses. However, existing methods face challenges in effectively supporting deep contextual understanding. To address this issue, we propose PRCCF, a Persona-guided Retrieval and Causality-aware Cognitive Filtering framework. Specifically, the framework incorporates a persona-guided retrieval mechanism that jointly models semantic compatibility and persona alignment to enhance response generation. Furthermore, it employs a causality-aware cognitive filtering module to prioritize causally relevant external knowledge, thereby improving contextual cognitive understanding for emotional reasoning. Extensive experiments on the ESConv dataset demonstrate that PRCCF outperforms state-of-the-art baselines on both automatic metrics and human evaluations. Our code is publicly available at: https://github.com/YancyLyx/PRCCF.
FURINA: Free from Unmergeable Router via LINear Aggregation of mixed experts
Sep 18, 2025


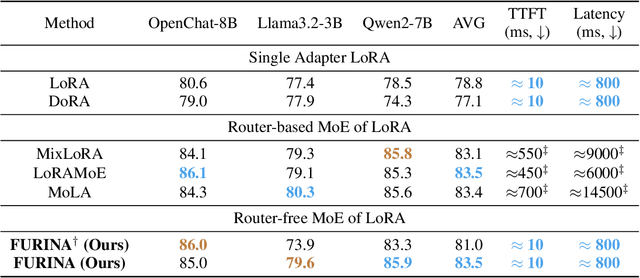
The Mixture of Experts (MoE) paradigm has been successfully integrated into Low-Rank Adaptation (LoRA) for parameter-efficient fine-tuning (PEFT), delivering performance gains with minimal parameter overhead. However, a key limitation of existing MoE-LoRA methods is their reliance on a discrete router, which prevents the integration of the MoE components into the backbone model. To overcome this, we propose FURINA, a novel Free from Unmergeable Router framework based on the LINear Aggregation of experts. FURINA eliminates the router by introducing a Self-Routing mechanism. This is achieved through three core innovations: (1) decoupled learning of the direction and magnitude for LoRA adapters, (2) a shared learnable magnitude vector for consistent activation scaling, and (3) expert selection loss that encourages divergent expert activation. The proposed mechanism leverages the angular similarity between the input and each adapter's directional component to activate experts, which are then scaled by the shared magnitude vector. This design allows the output norm to naturally reflect the importance of each expert, thereby enabling dynamic, router-free routing. The expert selection loss further sharpens this behavior by encouraging sparsity and aligning it with standard MoE activation patterns. We also introduce a shared expert within the MoE-LoRA block that provides stable, foundational knowledge. To the best of our knowledge, FURINA is the first router-free, MoE-enhanced LoRA method that can be fully merged into the backbone model, introducing zero additional inference-time cost or complexity. Extensive experiments demonstrate that FURINA not only significantly outperforms standard LoRA but also matches or surpasses the performance of existing MoE-LoRA methods, while eliminating the extra inference-time overhead of MoE.
SLIM: Let LLM Learn More and Forget Less with Soft LoRA and Identity Mixture
Oct 10, 2024



Although many efforts have been made, it is still a challenge to balance the training budget, downstream performance, and the general capabilities of the LLMs in many applications. Training the whole model for downstream tasks is expensive, and could easily result in catastrophic forgetting. By introducing parameter-efficient fine-tuning (PEFT), the training cost could be reduced, but it still suffers from forgetting, and limits the learning on the downstream tasks. To efficiently fine-tune the LLMs with less limitation to their downstream performance while mitigating the forgetting of general capabilities, we propose a novel mixture of expert (MoE) framework based on Soft LoRA and Identity Mixture (SLIM), that allows dynamic routing between LoRA adapters and skipping connection, enables the suppression of forgetting. We adopt weight-yielding with sliding clustering for better out-of-domain distinguish to enhance the routing. We also propose to convert the mixture of low-rank adapters to the model merging formulation and introduce fast dynamic merging of LoRA adapters to keep the general capabilities of the base model. Extensive experiments demonstrate that the proposed SLIM is comparable to the state-of-the-art PEFT approaches on the downstream tasks while achieving the leading performance in mitigating catastrophic forgetting.
CAB: Empathetic Dialogue Generation with Cognition, Affection and Behavior
Feb 03, 2023



Empathy is an important characteristic to be considered when building a more intelligent and humanized dialogue agent. However, existing methods did not fully comprehend empathy as a complex process involving three aspects: cognition, affection and behavior. In this paper, we propose CAB, a novel framework that takes a comprehensive perspective of cognition, affection and behavior to generate empathetic responses. For cognition, we build paths between critical keywords in the dialogue by leveraging external knowledge. This is because keywords in a dialogue are the core of sentences. Building the logic relationship between keywords, which is overlooked by the majority of existing works, can improve the understanding of keywords and contextual logic, thus enhance the cognitive ability. For affection, we capture the emotional dependencies with dual latent variables that contain both interlocutors' emotions. The reason is that considering both interlocutors' emotions simultaneously helps to learn the emotional dependencies. For behavior, we use appropriate dialogue acts to guide the dialogue generation to enhance the empathy expression. Extensive experiments demonstrate that our multi-perspective model outperforms the state-of-the-art models in both automatic and manual evaluation.
Fine-Grained Emotion Classification of Chinese Microblogs Based on Graph Convolution Networks
Dec 05, 2019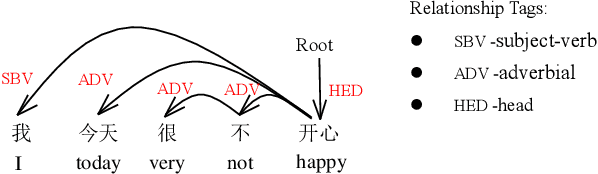
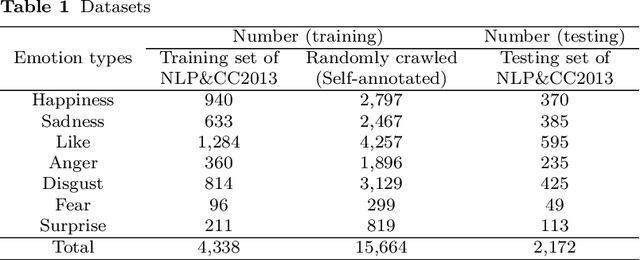
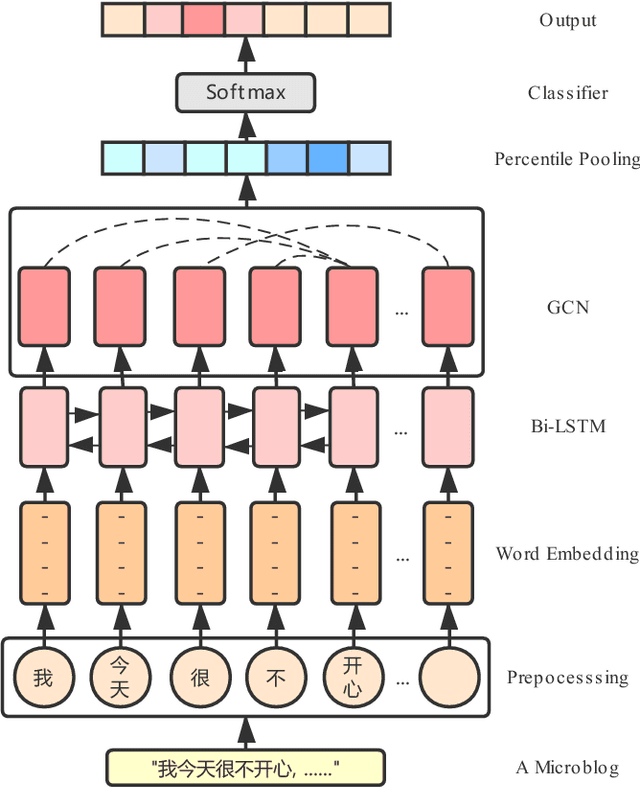
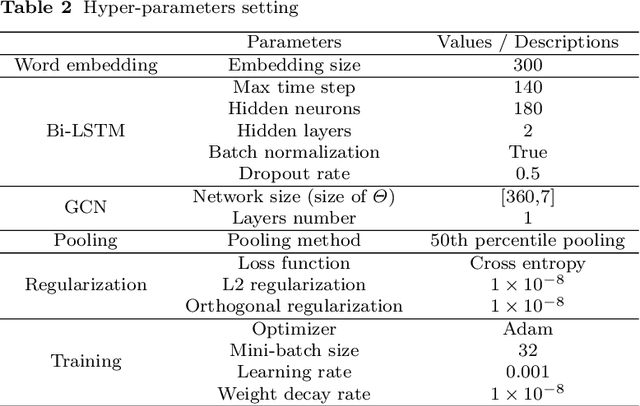
Microblogs are widely used to express people's opinions and feelings in daily life. Sentiment analysis (SA) can timely detect personal sentiment polarities through analyzing text. Deep learning approaches have been broadly used in SA but still have not fully exploited syntax information. In this paper, we propose a syntax-based graph convolution network (GCN) model to enhance the understanding of diverse grammatical structures of Chinese microblogs. In addition, a pooling method based on percentile is proposed to improve the accuracy of the model. In experiments, for Chinese microblogs emotion classification categories including happiness, sadness, like, anger, disgust, fear, and surprise, the F-measure of our model reaches 82.32% and exceeds the state-of-the-art algorithm by 5.90%. The experimental results show that our model can effectively utilize the information of dependency parsing to improve the performance of emotion detection. What is more, we annotate a new dataset for Chinese emotion classification, which is open to other researchers.